.png)
#Short Answer
Explains What Is Generative AI, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
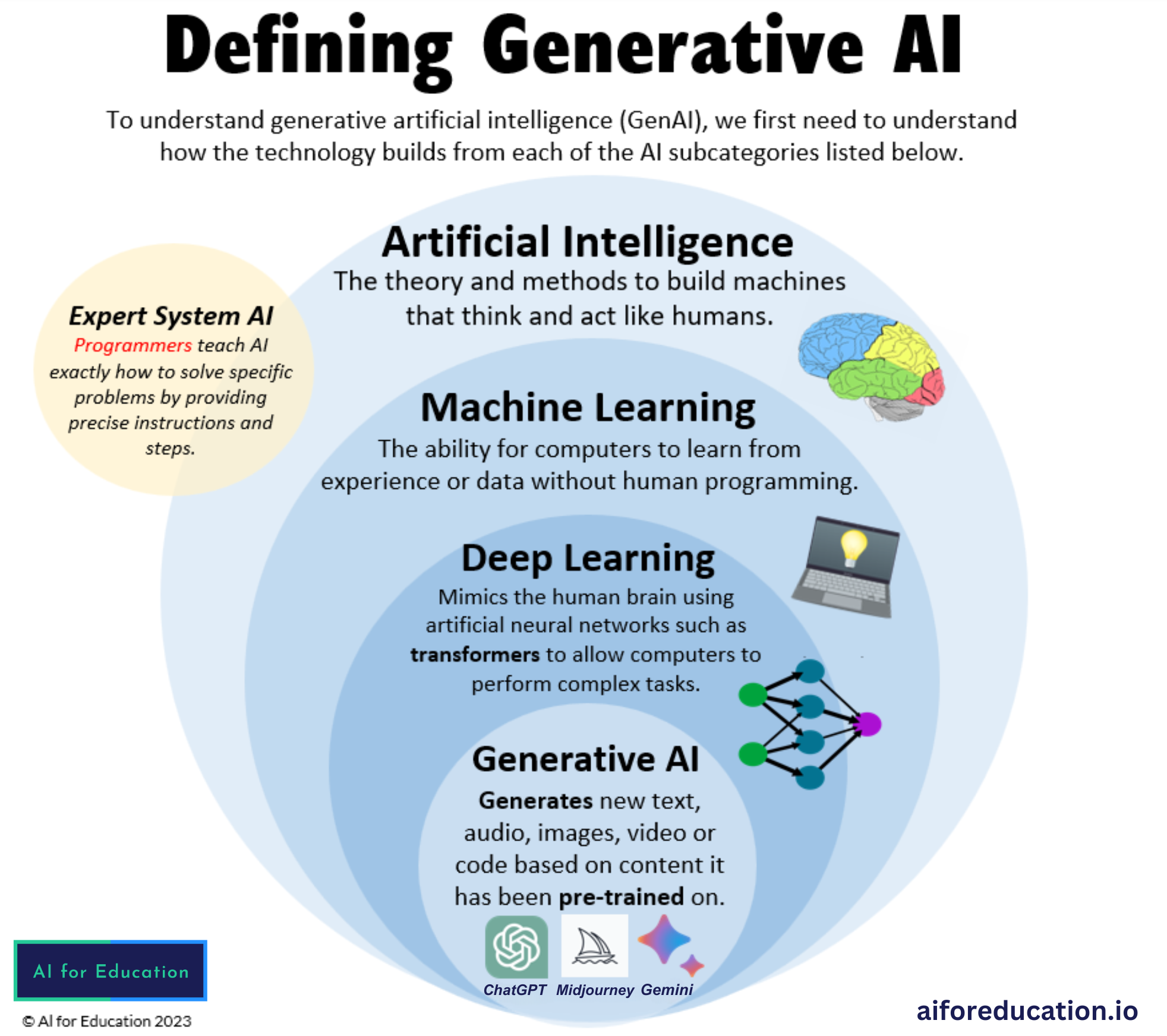
Generative AI represents a transformative branch of artificial intelligence focused on producing novel, coherent, and contextually relevant outputs. These systems leverage deep learning techniques to understand underlying data distributions and generate new instances that mimic real-world examples. Unlike discriminative models, which classify or predict labels, generative models aim to model the data generation process itself. The applications of generative AI span multiple domains, including natural language processing (NLP), computer vision, audio synthesis, and drug discovery. In NLP, models like large language models (LLMs) generate human-like text, while in computer vision, tools such as diffusion models create photorealistic images from textual descriptions. The versatility of generative AI has led to its adoption in creative industries, healthcare, finance, and education. One of the defining characteristics of generative AI is its ability to generalize from limited or noisy data. By learning statistical patterns, these models can produce outputs that are not explicitly present in their training datasets but are plausible extensions of the learned distribution. This capability has significant implications for innovation, automation, and personalization in digital systems.
#History / Background
The conceptual foundations of generative AI trace back to early work in statistical modeling and machine learning. In the 1950s and 1960s, researchers explored probabilistic models such as Markov chains and hidden Markov models (HMMs) to generate sequences of data, particularly in speech and text. However, these early systems lacked the complexity to produce high-quality, diverse outputs. A major milestone occurred in 2014 with the introduction of Generative Adversarial Networks (GANs) by Ian Goodfellow and colleagues. GANs introduced a novel training paradigm involving two competing neural networks: a generator that creates data and a discriminator that evaluates its authenticity. This adversarial process led to significant improvements in image generation quality, enabling the creation of realistic faces, objects, and scenes. The subsequent development of Variational Autoencoders (VAEs) in 2013 by Diederik P. Kingma and Max Welling provided another powerful framework for generative modeling. VAEs combine probabilistic inference with deep learning, allowing for controlled and interpretable generation of data. Unlike GANs, VAEs are trained using a variational approach that optimizes a lower bound on the data likelihood. The breakthrough in transformer-based models in 2017, particularly with the release of the Transformer architecture by Vaswani et al., revolutionized generative AI. Transformers, with their self-attention mechanisms, enabled models to process long-range dependencies in data, leading to the development of large language models (LLMs) such as GPT-2 (2019) and GPT-3 (2020). These models demonstrated unprecedented capabilities in generating coherent, contextually appropriate text across diverse topics. The evolution continued with the rise of diffusion models, introduced in 2015 and popularized in 2020 with models like DDPM (Denoising Diffusion Probabilistic Models). Diffusion models generate data by gradually denoising a corrupted version of the input, resulting in high-fidelity outputs in both image and audio domains. The release of Stable Diffusion (2022) and DALL·E 2 (2022) made generative AI accessible to the public, sparking widespread adoption and debate.
#How It Works
Generative AI systems operate through a combination of data representation learning and probabilistic modeling. The underlying mechanism varies depending on the architecture, but most modern approaches rely on deep neural networks trained on large datasets.
#Core Architectures
- Generative Adversarial Networks (GANs)
- Generator: A neural network that takes random noise as input and produces synthetic data (e.g., an image).
- Discriminator: A network that evaluates whether the generated data is real or fake.
- Training: The generator and discriminator are trained simultaneously in a minimax game, where the generator aims to fool the discriminator, and the discriminator aims to correctly classify real vs. fake data.
- Output: High-resolution images, videos, or audio that closely resemble real data.
- Variational Autoencoders (VAEs)
- Encoder: Maps input data to a latent space distribution (e.g., mean and variance).
- Latent Space: A compressed, lower-dimensional representation of the data.
- Decoder: Reconstructs data from a sample drawn from the latent space.
- Training: Optimizes a loss function combining reconstruction error and a regularization term (KL divergence) to ensure the latent space follows a prior distribution (e.g., Gaussian).
- Output: Smooth interpolations between data points and controlled generation via latent space manipulation.
- Transformer-Based Models (e.g., LLMs)
- Self-Attention Mechanism: Enables the model to weigh the importance of different parts of the input sequence dynamically.
- Autoregressive Generation: The model predicts the next token in a sequence based on previous tokens, enabling text generation word by word.
- Pretraining and Fine-Tuning: Models are first pretrained on vast text corpora to learn language patterns, then fine-tuned for specific tasks.
- Output: Coherent, contextually relevant text, code, or structured data.
- Diffusion Models
- Forward Process: Gradually adds noise to the data over many steps.
- Reverse Process: A neural network learns to reverse the noise addition, generating data from pure noise.
- Training: Optimizes the model to predict and remove noise at each step.
- Output: High-quality images, audio, or video with fine details and realism.
#Training Process
Generative models are trained using large datasets that represent the desired output domain. For example:
- Text Generation: Models are trained on books, articles, and web content.
- Image Generation: Models are trained on image repositories like ImageNet or LAION-5B.
- Audio Generation: Models are trained on speech, music, or environmental sound datasets. The training process involves:
- Data Preprocessing: Cleaning, normalization, and augmentation to improve model robustness.
- Model Architecture Design: Selecting the appropriate neural network structure (e.g., CNN for images, Transformer for text).
- Loss Function Optimization: Minimizing a loss that measures the difference between generated and real data (e.g., adversarial loss for GANs, cross-entropy for LLMs).
- Evaluation Metrics: Assessing quality using metrics like Inception Score (IS), Fréchet Inception Distance (FID), or human evaluation.
#Challenges in Generation Despite advancements, generative AI faces several challenges:
- Mode Collapse (GANs): The generator produces limited varieties of outputs, failing to capture the full data distribution.
- Training Instability: GANs can suffer from non-convergence or oscillating training dynamics.
- Data Hunger: High-quality generative models require massive, diverse datasets, which may be expensive or difficult to obtain.
- Bias and Fairness: Models can amplify biases present in training data, leading to unfair or harmful outputs.
- Interpretability: The "black box" nature of deep learning models makes it difficult to understand how outputs are generated.
#Important Facts
- Generative AI is not limited to text or images. It can produce music (e.g., AIVA, Soundraw), 3D models (e.g., NVIDIA’s GET3D), and even synthetic biological sequences for drug discovery.
- The term "generative AI" was popularized around 2016, coinciding with the rise of GANs and early transformer models.
- Generative models can be used for data augmentation, improving the performance of other AI systems by generating synthetic training examples.
- Ethical concerns include deepfake technology, which can be used to create convincing fake videos or audio for malicious purposes.
- Generative AI models often require significant computational resources, with training costs running into millions of dollars for state-of-the-art models.
- The first AI-generated artwork to win a fine art competition was "Portrait of Edmond de Belamy" in 2018, created by a GAN and sold at Christie’s for $432,500.
- Generative AI can assist in personalized education, creating tailored learning materials or interactive content based on student needs.
- The field intersects with reinforcement learning, where generative models are used to simulate environments for training agents.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is Generative AI?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is Generative AI? cover?
Explains What Is Generative AI, including the core definition, how it works, practical examples, and limitations.
Why is What Is Generative AI? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Generative AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Generative, AI, Machine Learning before using the ideas in real projects.
#References
- What Is Generative AI? terminology and background research
- What Is Generative AI? use cases, implementation examples, and limitations
- Generative AI best practices, standards, and risk guidance
- Generative case studies, benchmarks, and current industry analysis




Comments
No comments yet. Start the discussion with a useful note.