
#Short Answer
Covers generative ai for beginners: a friendly introduction, including core concepts, practical examples, benefits, limitations, and risks in Generative AI.
#Infobox
#History / Background
Early Foundations (1950s–2000s) The conceptual roots of generative AI trace back to early experiments in artificial intelligence and machine learning. In the 1950s, researchers like Alan Turing explored the idea of machines generating human-like responses, laying the groundwork for natural language processing (NLP). However, computational limitations restricted progress until the late 20th century. The 1980s and 1990s saw the development of probabilistic models and early neural networks, such as Boltzmann machines and restricted Boltzmann machines (RBMs), which could generate data by learning distributions. These models, while rudimentary by today’s standards, demonstrated the potential for machines to create new content.
The Deep Learning Revolution (2010s) The breakthrough in generative AI came with the rise of deep learning, particularly Generative Adversarial Networks (GANs), introduced by Ian Goodfellow and colleagues in 2014. GANs consist of two competing neural networks—a generator (which creates data) and a discriminator (which evaluates it)—engaged in a zero-sum game. This adversarial training process significantly improved the quality and realism of generated outputs, enabling applications like image synthesis and style transfer. Parallelly, Variational Autoencoders (VAEs) emerged as another powerful generative framework. Unlike GANs, VAEs focus on learning latent representations of data, allowing for controlled generation and interpolation between samples. These models became foundational for tasks like image generation and anomaly detection.
The Transformer Era (2017–Present) The introduction of the Transformer architecture by Vaswani et al. in 2017 marked a turning point for generative AI. Transformers, with their self-attention mechanisms, excel at processing sequential data, making them ideal for text generation. Models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) demonstrated unprecedented capabilities in understanding and generating human-like text. OpenAI’s GPT-3 (2020) and its successors, such as GPT-4, showcased the potential of large language models (LLMs) to generate coherent, contextually relevant text across diverse domains. Concurrently, diffusion models—a class of generative models that gradually denoise data—gained prominence for their ability to produce high-fidelity images (e.g., Stable Diffusion, DALL·E 2). Today, generative AI is a cornerstone of modern AI research, with applications spanning healthcare, entertainment, and education.
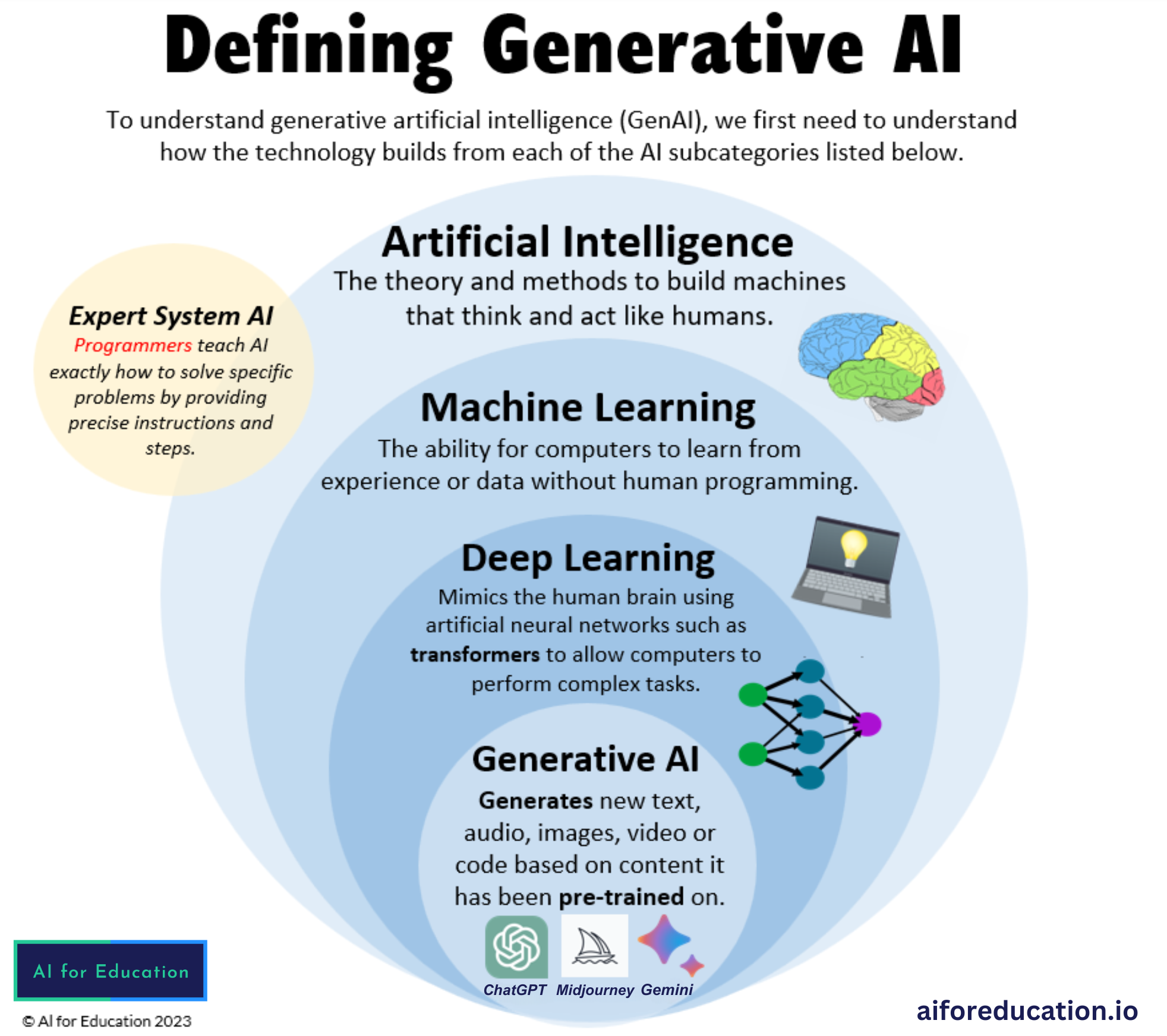
#How It Works
Core Principles Generative AI systems operate by learning the statistical distribution of a dataset and sampling from it to produce new data points. The process typically involves two key phases:
- Training: The model is exposed to a large dataset and learns to approximate its underlying distribution.
- Generation: The trained model samples from this distribution to create new, unseen data.
Key Architectures
- Generative Adversarial Networks (GANs)
- Generator: Creates synthetic data (e.g., images, text).
- Discriminator: Distinguishes between real and generated data.
- Training: The generator improves by fooling the discriminator, while the discriminator becomes better at detecting fakes.
- Applications: Image generation, super-resolution, data augmentation.
- Variational Autoencoders (VAEs)
- Encoder: Maps input data to a latent space (a compressed representation).
- Decoder: Reconstructs data from the latent space.
- Latent Space Sampling: New data is generated by sampling from the latent space and decoding it.
- Applications: Anomaly detection, image synthesis, data compression.
- Transformers and Large Language Models (LLMs)
- Self-Attention: Allows the model to weigh the importance of different parts of the input data.
- Pre-training: The model is trained on vast amounts of text data to learn language patterns.
- Fine-tuning: The model is adapted for specific tasks (e.g., chatbots, translation).
- Applications: Text generation, code completion, conversational AI.
- Diffusion Models
- Forward Process: Gradually adds noise to data over many steps.
- Reverse Process: A neural network learns to reverse the noise addition, generating data from pure noise.
- Applications: High-quality image generation, inpainting, text-to-image synthesis.
Training Data and Bias Generative AI models rely heavily on the quality and diversity of their training data. If the dataset contains biases (e.g., gender, racial, or cultural biases), the model may perpetuate or amplify these biases in its outputs. For example, a text-to-image model trained on biased datasets might generate stereotypical representations of certain professions or ethnicities. Addressing bias is a critical challenge in the development and deployment of generative AI systems.
#Important Facts
- Generative AI vs. Discriminative AI
- Generative AI: Learns to create new data (e.g., generating an image of a cat).
- Discriminative AI: Learns to classify or predict labels (e.g., identifying whether an image is a cat or a dog).
- Hallucinations in LLMs - Large language models can produce plausible-sounding but incorrect or nonsensical information, a phenomenon known as "hallucination." This occurs because the model generates text based on patterns in its training data rather than factual accuracy.
- Computational Costs - Training large generative models (e.g., LLMs) requires significant computational resources, often involving thousands of GPUs or TPUs and weeks of training time. This has led to concerns about the environmental impact of AI.
- Ethical and Legal Challenges
- Deepfakes: Generative AI can create hyper-realistic fake videos or audio, posing risks for misinformation and fraud.
- Intellectual Property: Generated content may inadvertently reproduce copyrighted material, raising legal questions about ownership and attribution.
- Job Displacement: Automation of creative tasks could disrupt industries like graphic design, writing, and music composition.
- Open-Source vs. Proprietary Models - Open-source models (e.g., Stable Diffusion, LLaMA) democratize access to generative AI but may lack the polish or safety features of proprietary alternatives (e.g., DALL·E, Midjourney).
#Timeline
- Foundational ideas
Core concepts and early methods shape Generative AI for Beginners: a Friendly Introduction.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Generative AI for Beginners: a Friendly Introduction cover?
Covers generative ai for beginners: a friendly introduction, including core concepts, practical examples, benefits, limitations, and risks in Generative AI.
Why is Generative AI for Beginners: a Friendly Introduction important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Generative AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Generative, AI, Machine Learning before using the ideas in real projects.
#References
- Generative AI for Beginners: a Friendly Introduction terminology and background research
- Generative AI for Beginners: a Friendly Introduction use cases, implementation examples, and limitations
- Generative AI best practices, standards, and risk guidance
- Generative case studies, benchmarks, and current industry analysis

.png)


Comments
No comments yet. Start the discussion with a useful note.