#Short Answer
Explains What Is a Validation Dataset, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
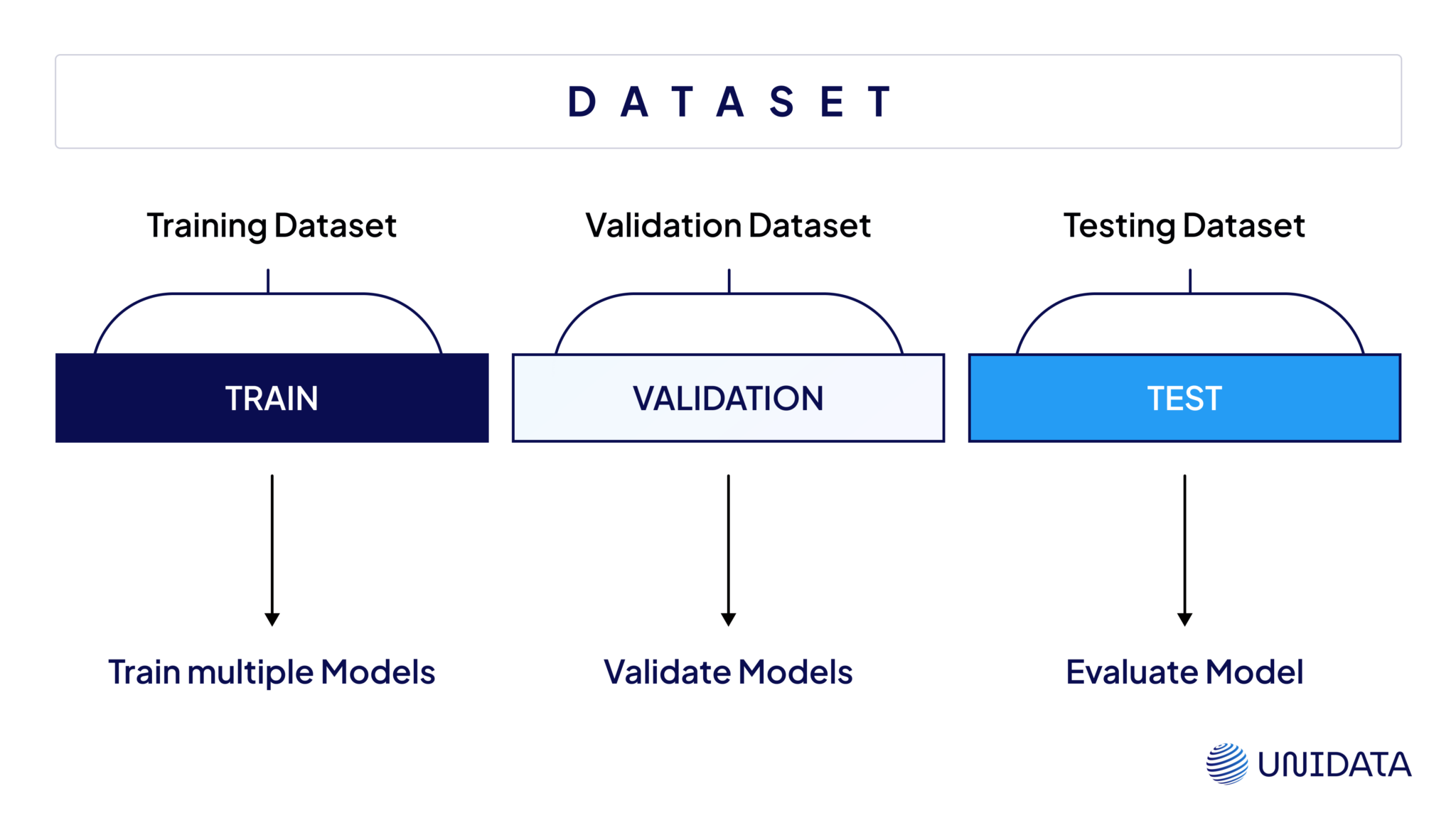
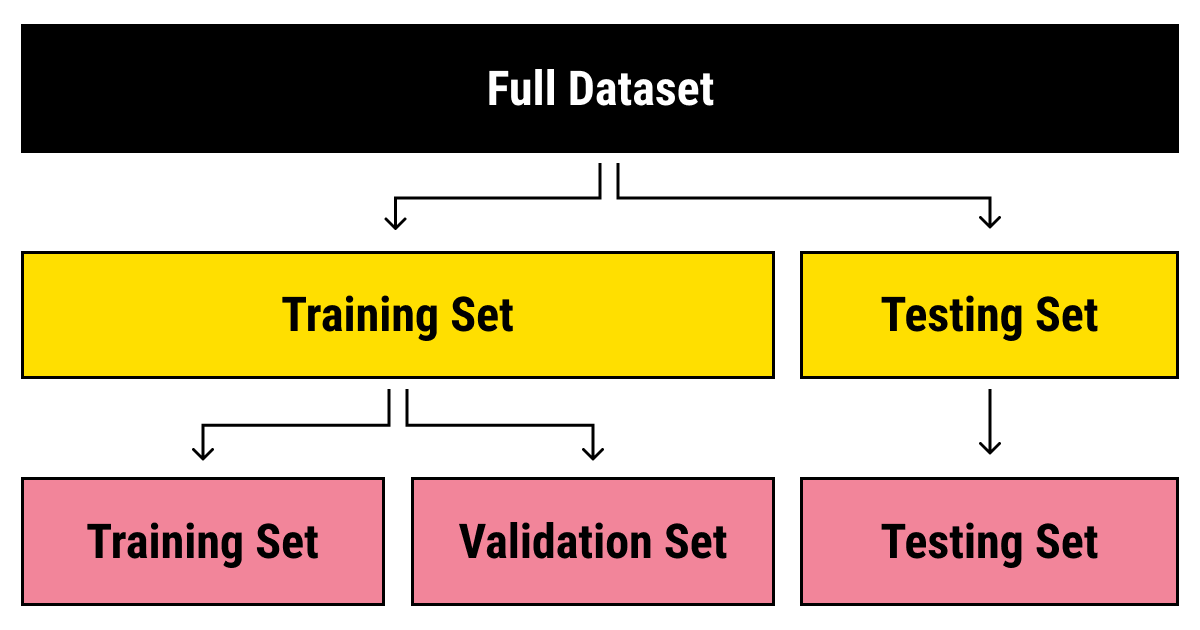
In machine learning, a validation dataset plays a critical role in the model development pipeline. It serves as an intermediary between the training and test datasets, providing a mechanism to evaluate the model’s performance during training without exposing it to the final test set. The primary goal of using a validation dataset is to ensure that the model generalizes well to new, unseen data rather than memorizing the training examples—a phenomenon known as overfitting. The validation dataset is typically derived from the original dataset by splitting it into three parts: the training set, the validation set, and the test set. The training set is used to fit the model’s parameters, the validation set is used to tune hyperparameters and monitor performance, and the test set is reserved for the final evaluation of the model’s generalization capability. This three-way split helps maintain an unbiased assessment of the model’s performance.
#History / Background
The concept of a validation dataset emerged alongside the development of statistical learning theory and the need for robust model evaluation methods. Early work in the 1960s and 1970s by statisticians like John Tukey and Leo Breiman laid the groundwork for modern validation techniques. The introduction of cross-validation in the 1970s, particularly k-fold cross-validation, provided a systematic way to use subsets of data for validation without requiring a separate validation set. In the 1990s, as machine learning gained prominence, researchers recognized the importance of validation datasets in preventing overfitting, especially in complex models like neural networks. The rise of deep learning in the 2000s further emphasized the need for validation datasets, as models with millions of parameters required careful tuning to avoid overfitting to the training data. The term "validation dataset" became widely adopted in academic and industry practices, with frameworks like scikit-learn and TensorFlow incorporating built-in functions to facilitate dataset splitting and validation.
#How It Works
#Dataset Splitting The validation dataset is created by partitioning the original dataset into three subsets:
- Training Set (e.g., 60-80%): Used to train the model by adjusting its parameters (e.g., weights in a neural network).
- Validation Set (e.g., 10-20%): Used to evaluate the model’s performance during training and tune hyperparameters (e.g., learning rate, number of layers).
- Test Set (e.g., 10-20%): Used only once at the end to assess the final performance of the model.
#Validation Process
- Model Training: The model is trained on the training set, adjusting its parameters to minimize the loss function (e.g., mean squared error, cross-entropy loss).
- Validation Evaluation: After each training epoch (or at regular intervals), the model is evaluated on the validation set. Metrics such as accuracy, precision, recall, or loss are computed.
- Hyperparameter Tuning: Based on the validation performance, hyperparameters are adjusted. For example, if the validation loss starts increasing while the training loss decreases, it may indicate overfitting, prompting changes like reducing model complexity or adding regularization.
- Early Stopping: A common technique where training is halted if the validation loss stops improving, preventing the model from overfitting to the training data.
#Common Validation Techniques
- Holdout Validation: A simple split of the dataset into training, validation, and test sets. Suitable for large datasets but may lead to high variance if the split is not representative.
- K-Fold Cross-Validation: The dataset is divided into k folds, and the model is trained k times, each time using a different fold as the validation set. The performance metrics are averaged across all folds. This method reduces variance and is useful for smaller datasets.
- Stratified Sampling: Ensures that each subset (training, validation, test) maintains the same class distribution as the original dataset, particularly important for imbalanced datasets.
- Time Series Validation: For time-dependent data, validation sets are created using chronological splits to preserve temporal order.
#Important Facts
- Purpose of Validation: The primary purpose of a validation dataset is to provide an unbiased evaluation of the model’s performance during training, guiding hyperparameter tuning and preventing overfitting.
- Avoiding Data Leakage: The validation set must be independent of the training set to ensure unbiased evaluation. Any overlap between training and validation data can lead to overly optimistic performance estimates.
- Role in Hyperparameter Tuning: Hyperparameters (e.g., learning rate, batch size, number of layers) are tuned based on validation performance. The test set should never be used for this purpose.
- Overfitting Detection: If the model performs well on the training set but poorly on the validation set, it indicates overfitting. Techniques like regularization (L1/L2), dropout, or early stopping can mitigate this.
- Validation vs. Test Set: The validation set is used iteratively during training, while the test set is used only once at the end to report the final performance.
- Impact of Dataset Size: In small datasets, techniques like k-fold cross-validation are preferred to maximize the use of available data for validation.
- Bias-Variance Tradeoff: The validation set helps balance the bias (underfitting) and variance (overfitting) of the model. A model with high variance may perform well on the training set but poorly on the validation set.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a Validation Dataset?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a Validation Dataset? cover?
Explains What Is a Validation Dataset, including the core definition, how it works, practical examples, and limitations.
Why is What Is a Validation Dataset? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Validation, Dataset, AI before using the ideas in real projects.
#References
- What Is a Validation Dataset? terminology and background research
- What Is a Validation Dataset? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Validation case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.