#Short Answer
Explains What Is a Test Dataset, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
A test dataset is a critical component in the machine learning pipeline, serving as an independent benchmark to evaluate a model's performance. Unlike the training dataset, which is used to teach the model, or the validation dataset, which helps tune hyperparameters, the test dataset remains untouched during model development. Its primary role is to simulate real-world conditions, providing an unbiased assessment of the model's predictive capabilities. The test dataset is typically derived from the same population as the training data but consists of unseen examples. By exposing the model to new data, developers can measure its ability to generalize beyond the training examples. This process is essential for identifying issues such as overfitting (where the model performs well on training data but poorly on unseen data) or underfitting (where the model fails to capture underlying patterns). In supervised learning, the test dataset includes both input features and corresponding labels (for classification or regression tasks). The model's predictions on this dataset are compared against the true labels to compute performance metrics. For unsupervised learning, the test dataset may be used to evaluate clustering quality or anomaly detection performance.
#History / Background
The concept of a test dataset emerged alongside the development of statistical learning theory and machine learning as a formal discipline. Early work in the mid-20th century, such as R.A. Fisher’s contributions to experimental design, laid the groundwork for separating data into distinct subsets for training and testing. However, the systematic use of test datasets became more prominent with the rise of computational statistics and artificial intelligence in the 1960s and 1970s. The holdout method, one of the earliest approaches, involved splitting data into training and test sets. This method gained traction in the 1980s and 1990s as computational resources became more accessible. Researchers like Leo Breiman and Jerome Friedman emphasized the importance of independent test sets to validate model performance, particularly in the context of decision trees and ensemble methods. The advent of cross-validation techniques, such as k-fold cross-validation, further refined the evaluation process by reducing variance in performance estimates. However, the test dataset remained a cornerstone for final model assessment, especially in high-stakes applications like healthcare, finance, and autonomous systems. In the 21st century, the proliferation of big data and deep learning has reinforced the necessity of robust test datasets. Large-scale datasets, such as those used in ImageNet or MNIST, rely on carefully curated test sets to benchmark state-of-the-art models. Additionally, the rise of reproducible research and open science has led to standardized test datasets being shared publicly, enabling fair comparisons across different models and approaches.
#How It Works
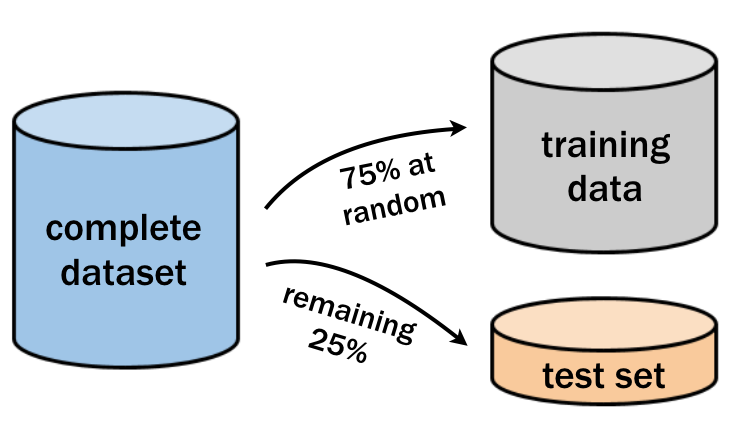
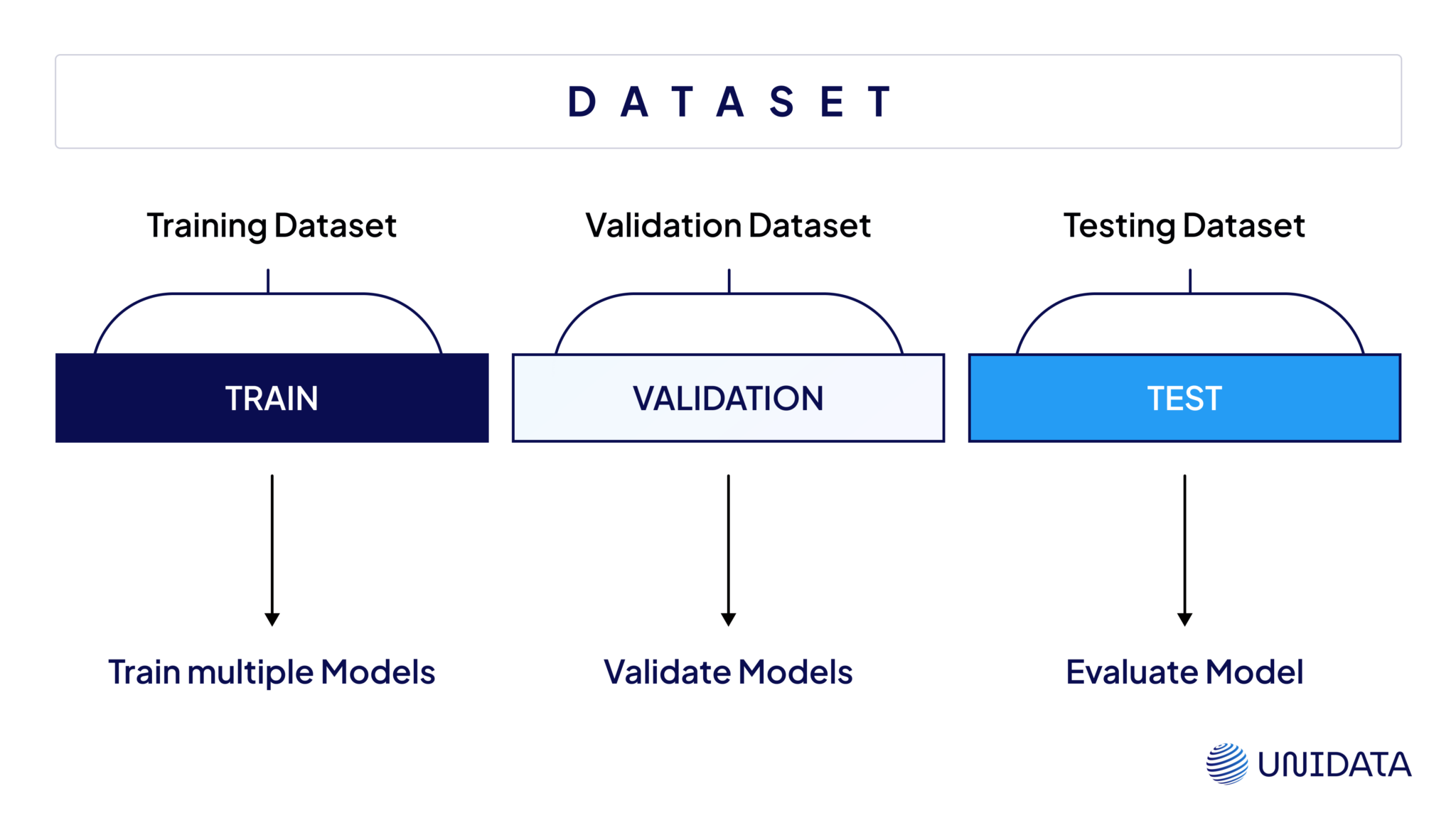
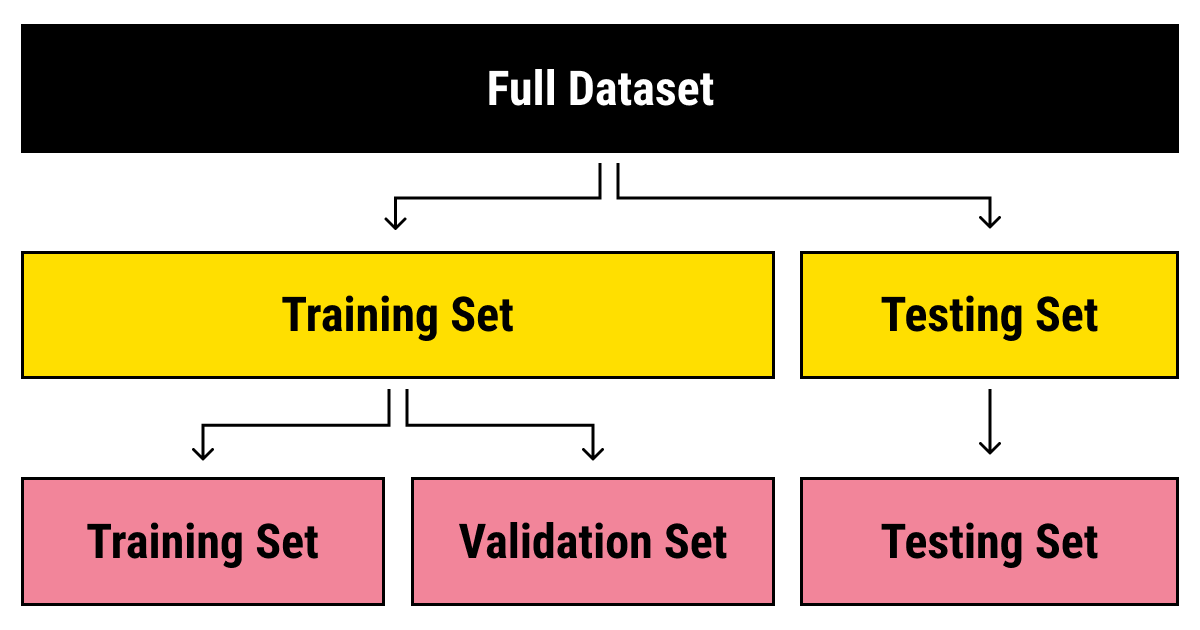
#Data Splitting The process of creating a test dataset begins with data splitting, where the original dataset is divided into three subsets:
- Training dataset (typically 60-80% of the data): Used to train the model.
- Validation dataset (10-20%): Used for hyperparameter tuning and model selection.
- Test dataset (10-20%): Used for final evaluation. The split is often performed randomly, though stratified sampling may be used to ensure class balance in classification tasks.
#Model Evaluation Once the model is trained, it is evaluated on the test dataset using predefined performance metrics:
- Classification Tasks: Accuracy, Precision, Recall, F1-Score, ROC-AUC, Confusion Matrix.
- Regression Tasks: Mean Absolute Error (MAE), Mean Squared Error (MSE), R² Score.
- Clustering Tasks: Silhouette Score, Davies-Bouldin Index. These metrics provide quantitative measures of the model's performance, helping developers identify strengths and weaknesses.
#Avoiding Data Leakage A critical aspect of using a test dataset is preventing data leakage, where information from the test set inadvertently influences the training process. Common sources of leakage include:
- Feature engineering that uses statistics from the entire dataset (e.g., mean normalization).
- Improper splitting where test data is included in training.
- Time-series data where future information is used to predict past events. To mitigate leakage, techniques such as time-based splitting or stratified sampling are employed.
#Model Deployment and Monitoring After evaluation, the test dataset's performance serves as a proxy for real-world performance. If the model meets the desired criteria, it may be deployed in production. However, continuous model monitoring is essential to detect concept drift, where the statistical properties of the data change over time, necessitating retraining or adjustments.
#Important Facts
- Purpose: The test dataset is the ultimate judge of a model's generalization ability, providing an unbiased estimate of its performance on unseen data.
- Independence: The test dataset must remain completely independent of the training and validation datasets to avoid biased results.
- Size: The size of the test dataset depends on the total dataset size and the problem's complexity. Larger datasets allow for more reliable performance estimates.
- Reproducibility: Standardized test datasets (e.g., CIFAR-10, IMDB Reviews) enable fair comparisons between different models.
- Ethical Considerations: In sensitive applications (e.g., healthcare, criminal justice), the test dataset must be representative of the target population to avoid biased outcomes.
- Dynamic Nature: In real-world scenarios, the test dataset may evolve over time, requiring periodic updates to reflect changing data distributions.
- Benchmarking: Test datasets are often used in machine learning competitions (e.g., Kaggle) to rank participants based on model performance.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a Test Dataset?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a Test Dataset? cover?
Explains What Is a Test Dataset, including the core definition, how it works, practical examples, and limitations.
Why is What Is a Test Dataset? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Test, Dataset, AI before using the ideas in real projects.
#References
- What Is a Test Dataset? terminology and background research
- What Is a Test Dataset? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Test case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.