#Short Answer
Explains What Is a Training Dataset, including the core definition, how it works, practical examples, and limitations.
#Infobox
#How It Works
Data Collection The first step in creating a training dataset is data collection, which involves gathering relevant information from various sources. This can include:
- Structured data: Databases, spreadsheets, or APIs (e.g., financial records, sensor readings).
- Unstructured data: Text documents, images, audio, or videos (e.g., social media posts, medical scans).
- Synthetic data: Artificially generated data to supplement real-world datasets (e.g., augmented reality simulations).
Data Preprocessing Raw data often contains noise, inconsistencies, or missing values. Data preprocessing techniques are applied to clean and standardize the dataset, including:
- Normalization: Scaling numerical features to a common range (e.g., 0 to 1).
- Encoding: Converting categorical data (e.g., "yes"/"no") into numerical formats (e.g., 1/0).
- Handling missing values: Imputing or removing incomplete entries.
- Feature engineering: Creating new features from existing data to improve model performance.
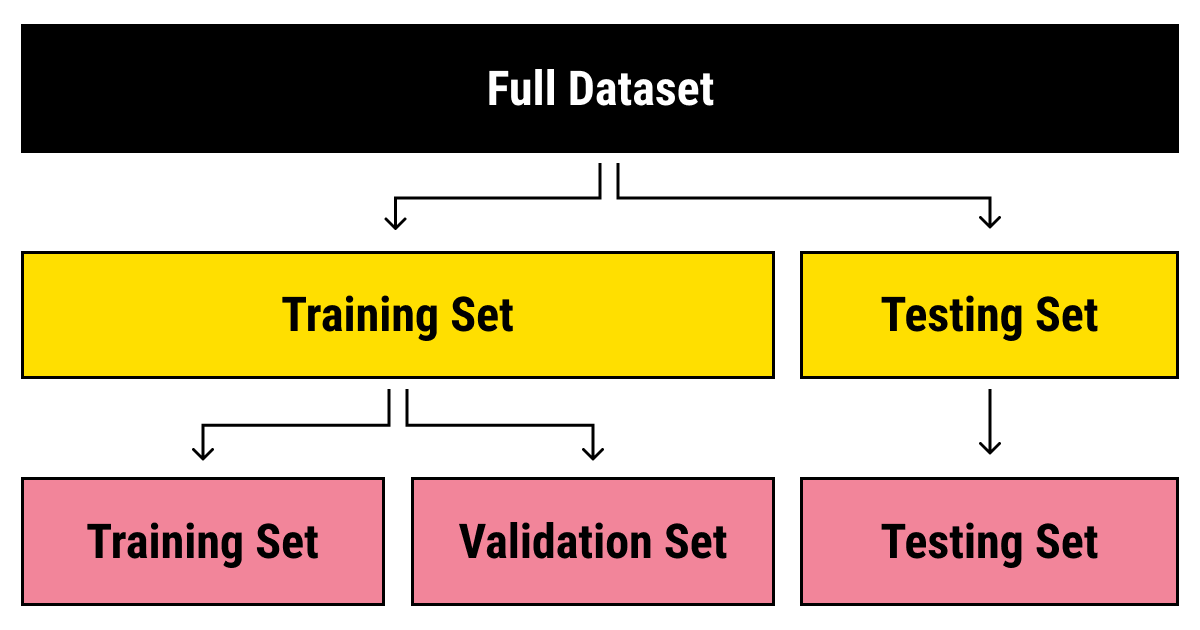
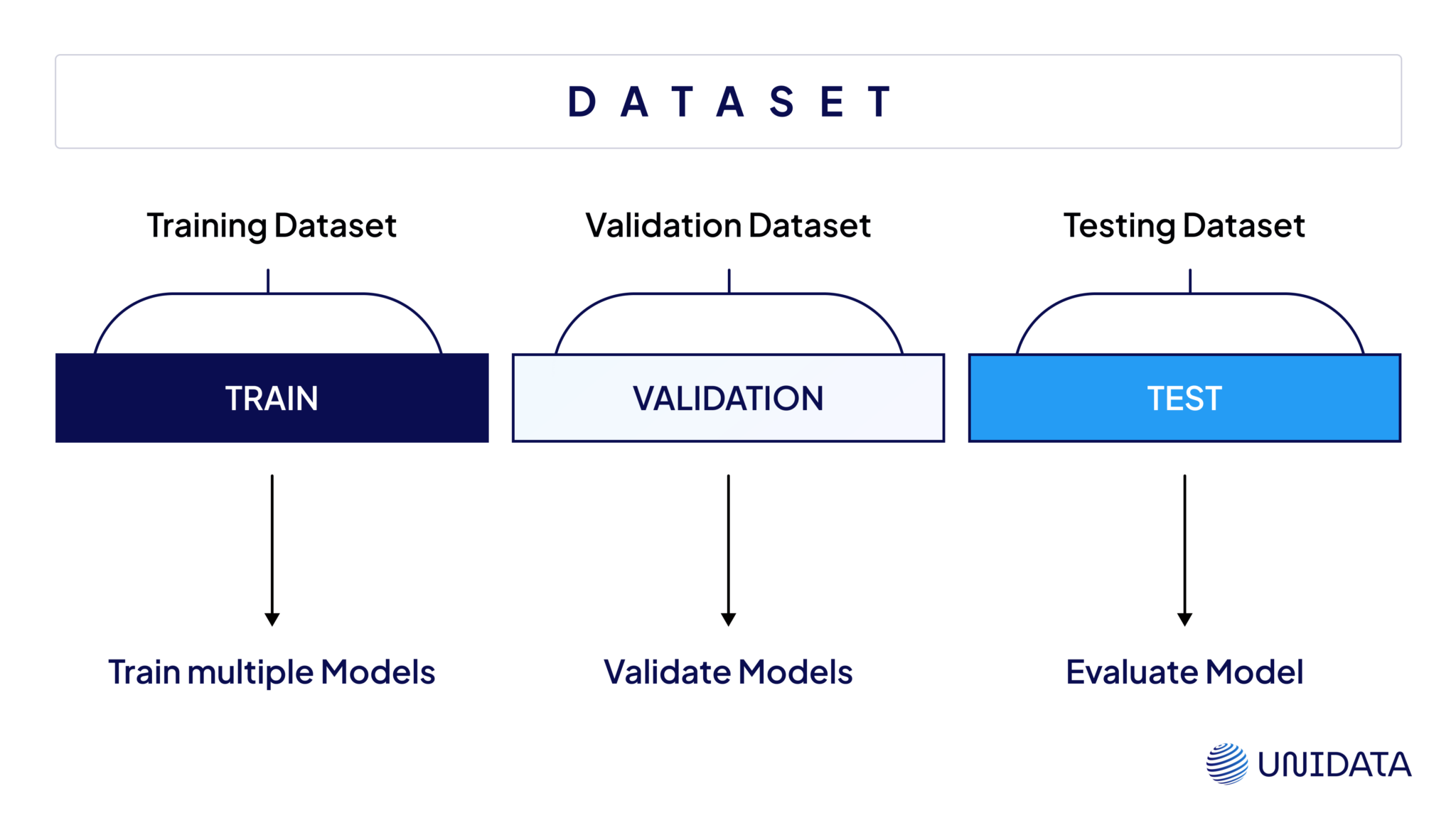
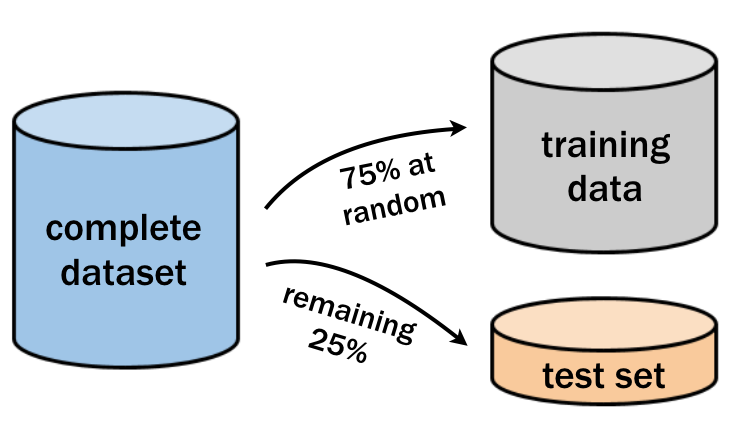
Data Splitting A training dataset is typically divided into three subsets:
- Training set: Used to train the model (usually 70–80% of the data).
- Validation set: Used to tune hyperparameters and prevent overfitting (10–15%).
- Test set: Used to evaluate the model’s performance on unseen data (10–15%).
Model Training The training dataset is fed into a machine learning algorithm, which learns patterns by adjusting its parameters (e.g., weights in a neural network). The goal is to minimize the loss function, which measures the difference between predicted and actual outputs.
Evaluation and Iteration After training, the model is evaluated using the test set. Metrics such as accuracy, precision, recall, and F1-score are used to assess performance. If the model underperforms, the training dataset may be refined, or the algorithm may be adjusted.
#Important Facts
- Bias in Training Data: - Datasets can inherit biases from their sources, leading to unfair or discriminatory outcomes (e.g., facial recognition systems performing poorly on darker-skinned individuals due to underrepresentation in training data). - Mitigation strategies include diverse sampling, bias audits, and fairness-aware algorithms.
- Overfitting vs. Underfitting:
- Overfitting: The model memorizes the training data but fails to generalize to new data. Often caused by a small or overly complex dataset.
- Underfitting: The model is too simple to capture underlying patterns. May result from insufficient training data or poor feature selection.
- Data Augmentation: - Techniques like rotation, flipping, or adding noise are used to artificially expand small datasets, particularly in computer vision and NLP.
- Transfer Learning: - Pre-trained models (e.g., BERT for NLP or ResNet for images) can be fine-tuned on smaller datasets, reducing the need for large-scale training data.
- Ethical Considerations: - Privacy concerns arise when datasets contain sensitive information (e.g., medical records). Anonymization and differential privacy are used to protect individual identities.
- Data Drift: - Real-world data distributions change over time, causing models to degrade in performance. Continuous monitoring and retraining are necessary to maintain accuracy.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a Training Dataset?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a Training Dataset? cover?
Explains What Is a Training Dataset, including the core definition, how it works, practical examples, and limitations.
Why is What Is a Training Dataset? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Training, Dataset, AI before using the ideas in real projects.
#References
- What Is a Training Dataset? terminology and background research
- What Is a Training Dataset? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Training case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.