
#Short Answer
Traces timeline of natural language processing, highlighting major milestones, context, examples, and future implications.
#Infobox
#Overview
Natural Language Processing (NLP) bridges the gap between human communication and computer understanding. It encompasses a range of techniques, from syntactic parsing to semantic analysis, enabling machines to process unstructured text data efficiently. NLP powers applications such as virtual assistants, automated customer service, and real-time translation services. Over the decades, NLP has evolved from rigid rule-based systems to adaptive, data-driven models capable of near-human language comprehension. The field’s growth has been fueled by advancements in computational power, the availability of large datasets, and breakthroughs in machine learning. Today, NLP is integral to industries like healthcare, finance, and education, where it facilitates tasks such as document summarization, fraud detection, and personalized learning.
#History / Background
#Early Foundations (Pre-1950s)
The conceptual roots of NLP trace back to ancient linguistic theories and the development of formal grammars. In the 17th century, philosophers like René Descartes explored the idea of a universal grammar, while 19th-century linguists such as Ferdinand de Saussure laid the groundwork for structural linguistics. These early ideas set the stage for later computational approaches to language.
#The Birth of NLP (1950s–1960s)
The modern era of NLP began in the 1950s with the advent of electronic computers. Key milestones include:
- 1950: Alan Turing proposed the Turing Test, a benchmark for machine intelligence based on language comprehension.
- 1954: The Georgetown-IBM experiment demonstrated the first machine translation system, translating Russian sentences into English.
- 1966: Joseph Weizenbaum developed ELIZA, an early natural language processing program that simulated conversation by using pattern matching and substitution methodologies.
#Rule-Based and Statistical Approaches (1970s–1990s)
During this period, NLP research focused on rule-based systems and statistical methods:
- 1970s: The SHRDLU program by Terry Winograd demonstrated how a computer could understand and manipulate objects in a virtual world using natural language commands.
- 1980s: The rise of corpus linguistics and statistical NLP introduced probabilistic models, such as Hidden Markov Models (HMMs), for tasks like speech recognition and part-of-speech tagging.
- 1990s: Projects like WordNet (a lexical database) and IBM’s statistical machine translation models laid the groundwork for modern NLP techniques.
#The Machine Learning Revolution (2000s–2010s)
The 21st century marked a paradigm shift with the integration of machine learning into NLP:
- 2001: The introduction of support vector machines (SVMs) improved text classification tasks.
- 2006: The development of Latent Dirichlet Allocation (LDA) enabled topic modeling, aiding in document analysis.
- 2013: The Word2Vec algorithm by Mikolov et al. revolutionized word embeddings, capturing semantic relationships between words.
- 2017: The Transformer architecture, introduced in the paper "Attention Is All You Need", became the foundation for models like BERT and GPT, enabling unprecedented accuracy in language tasks.
#The Era of Large Language Models (2020s–Present)
Recent years have seen the rise of large language models (LLMs) trained on vast datasets:
- 2020: GPT-3 by OpenAI demonstrated human-like text generation, sparking widespread interest in AI-driven language applications.
- 2021: BERT and its variants became industry standards for tasks like question answering and sentiment analysis.
- 2022–2023: Models like ChatGPT, PaLM, and Llama pushed the boundaries of conversational AI, enabling real-time interactions with near-human fluency.
- 2024: Ongoing research focuses on multimodal NLP, few-shot learning, and ethical AI, addressing challenges like bias, misinformation, and computational efficiency.
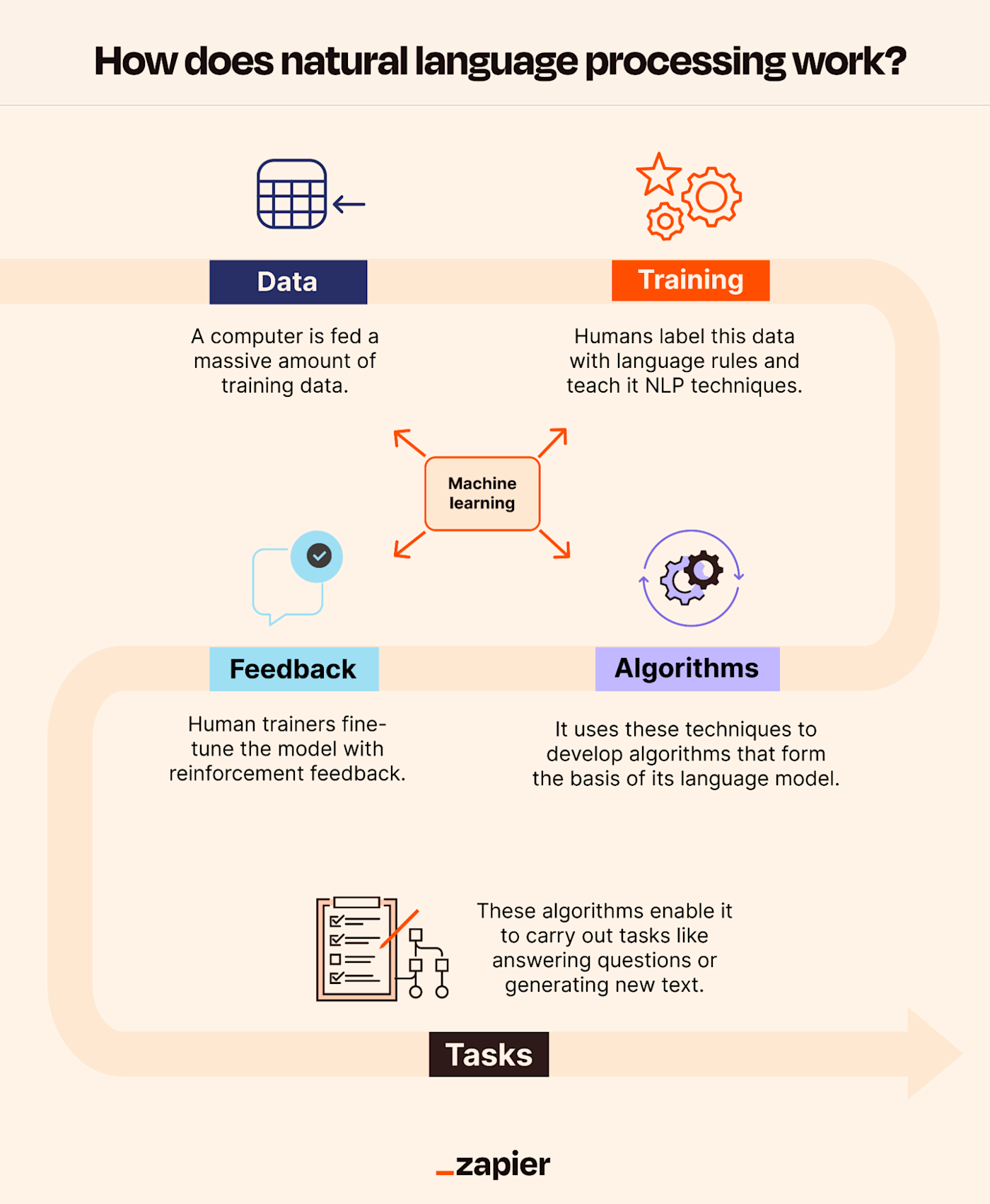
#How It Works
#Core Components of NLP NLP systems typically involve several key stages:
- Tokenization: Breaking text into smaller units (words, phrases, or sentences).
- Normalization: Converting text to a standard format (e.g., lowercasing, removing punctuation).
- Part-of-Speech (POS) Tagging: Identifying grammatical components (nouns, verbs, adjectives).
- Parsing: Analyzing sentence structure to determine relationships between words.
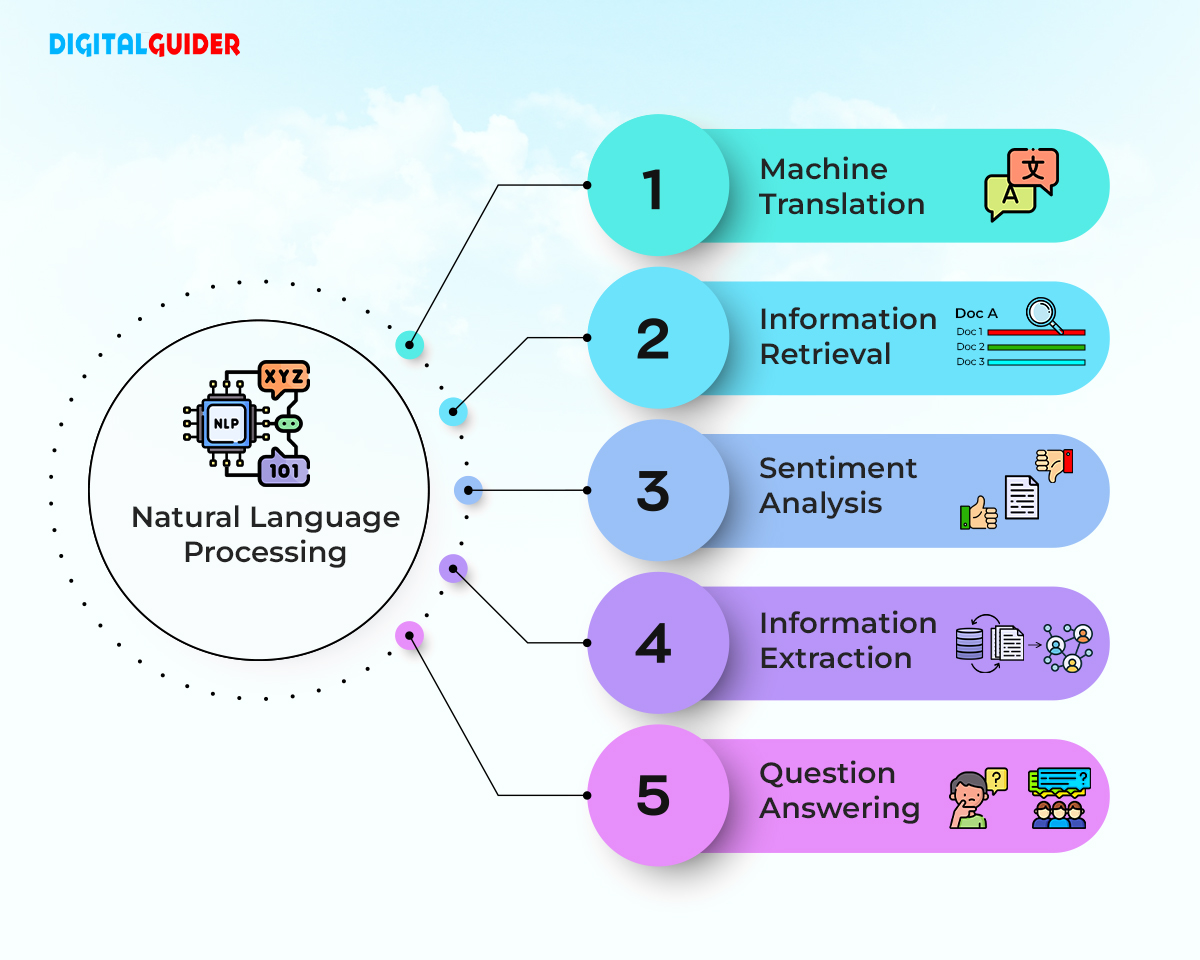
- Named Entity Recognition (NER): Identifying entities like people, places, and organizations.
- Sentiment Analysis: Determining the emotional tone of a text.
- Machine Translation: Converting text from one language to another.
- Text Generation: Producing coherent and contextually relevant text.
#Key Techniques
- Rule-Based Systems: Use predefined linguistic rules (e.g., ELIZA).
- Statistical NLP: Relies on probabilistic models (e.g., HMMs, n-grams).
- Machine Learning: Employs algorithms like SVMs, decision trees, and neural networks.
- Deep Learning: Uses architectures like Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Transformers for complex tasks.
- Transfer Learning: Leverages pre-trained models (e.g., BERT, GPT) for fine-tuning on specific tasks.
#Challenges in NLP
- Ambiguity: Words and sentences can have multiple meanings (e.g., "bank" as a financial institution vs. a riverbank).
- Contextual Understanding: Machines struggle with sarcasm, irony, and cultural nuances.
- Data Scarcity: High-quality annotated datasets are often limited for low-resource languages.
- Bias and Fairness: NLP models can perpetuate biases present in training data.
- Scalability: Large models require significant computational resources.
#Important Facts
- First NLP Program: ELIZA (1966) simulated a Rogerian psychotherapist, demonstrating early conversational AI.
- Machine Translation Milestone: The Georgetown-IBM experiment (1954) translated 60 Russian sentences into English using a dictionary and grammar rules.
- Word Embeddings Revolution: Word2Vec (2013) introduced dense vector representations of words, capturing semantic relationships (e.g., "king" - "man" + "woman" ≈ "queen").
- Transformer Breakthrough: The Transformer architecture (2017) replaced RNNs with self-attention mechanisms, enabling parallel processing and improved performance.
- BERT’s Impact: Bidirectional Encoder Representations from Transformers (BERT) (2018) achieved state-of-the-art results in 11 NLP tasks by pre-training on a large corpus.
- GPT-3’s Scale: With 175 billion parameters, GPT-3 (2020) demonstrated the potential of large-scale language models for generating human-like text.
- Multilingual NLP: Models like mBERT and XLM-R support over 100 languages, enabling cross-lingual applications.
- Ethical Concerns: NLP systems have been criticized for generating misinformation, deepfake text, and reinforcing societal biases.
#Timeline
- Foundational ideas
Core concepts and early methods shape Timeline of Natural Language Processing.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Timeline of Natural Language Processing cover?
Traces timeline of natural language processing, highlighting major milestones, context, examples, and future implications.
Why is Timeline of Natural Language Processing important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Timeline, Natural, Language before using the ideas in real projects.
#References
- Timeline of Natural Language Processing terminology and background research
- Timeline of Natural Language Processing use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Timeline case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.