#Short Answer
Covers natural language processing for dummies: a beginner’s overview, including core concepts, practical examples, benefits, limitations, and risks in Language AI.
#Infobox
#History / Background
Early Foundations (1950s–1960s) The origins of NLP can be traced back to the 1950s, when researchers began exploring the possibility of teaching computers to understand and generate human language. One of the earliest milestones was the Georgetown-IBM experiment in 1954, where a computer successfully translated 60 Russian sentences into English. This event sparked significant interest in machine translation, though early systems relied heavily on rule-based approaches and were limited in scope. In 1957, Noam Chomsky introduced the theory of generative grammar, which provided a formal framework for understanding the structure of language. This theoretical foundation influenced early NLP research, as linguists and computer scientists sought to encode grammatical rules into computational systems.
Rule-Based Systems (1970s–1980s) During the 1970s and 1980s, NLP research focused on rule-based systems, which used handcrafted linguistic rules to parse and generate language. Projects like SHRDLU, developed by Terry Winograd in 1972, demonstrated that computers could understand and respond to natural language commands in a constrained domain (e.g., a virtual blocks world). However, these systems were brittle and struggled with the complexity and variability of real-world language.
Statistical NLP (1990s–2000s) The 1990s marked a shift toward statistical NLP, driven by advances in machine learning and the availability of large text corpora. Researchers began using probabilistic models to analyze language patterns, enabling systems to make predictions based on data rather than rigid rules. Techniques such as hidden Markov models (HMMs) and n-gram models became popular for tasks like part-of-speech tagging and speech recognition. The rise of the internet in the late 1990s and early 2000s provided vast amounts of text data, fueling the development of more sophisticated statistical models. This era also saw the emergence of support vector machines (SVMs) and maximum entropy models, which improved the accuracy of tasks like text classification and named entity recognition.
Deep Learning Revolution (2010s–Present) The 2010s brought about a deep learning revolution in NLP, transforming the field with the advent of neural networks and large-scale language models. Key breakthroughs included:
- Word embeddings (e.g., Word2Vec, GloVe) that represented words as dense vectors, capturing semantic relationships.
- Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, which improved sequence modeling for tasks like machine translation and text generation.
- Attention mechanisms, introduced in the Transformer architecture (2017), which enabled models to focus on relevant parts of the input, leading to significant improvements in tasks like language understanding and generation.
- Large language models (LLMs) such as BERT, GPT, and T5, which leverage massive datasets and billions of parameters to achieve human-like performance in a wide range of NLP tasks. Today, NLP continues to evolve rapidly, with ongoing research in areas like multimodal learning (combining text and other modalities like images or audio), low-resource language processing, and ethical AI, ensuring that the field remains at the forefront of technological innovation.
#How It Works
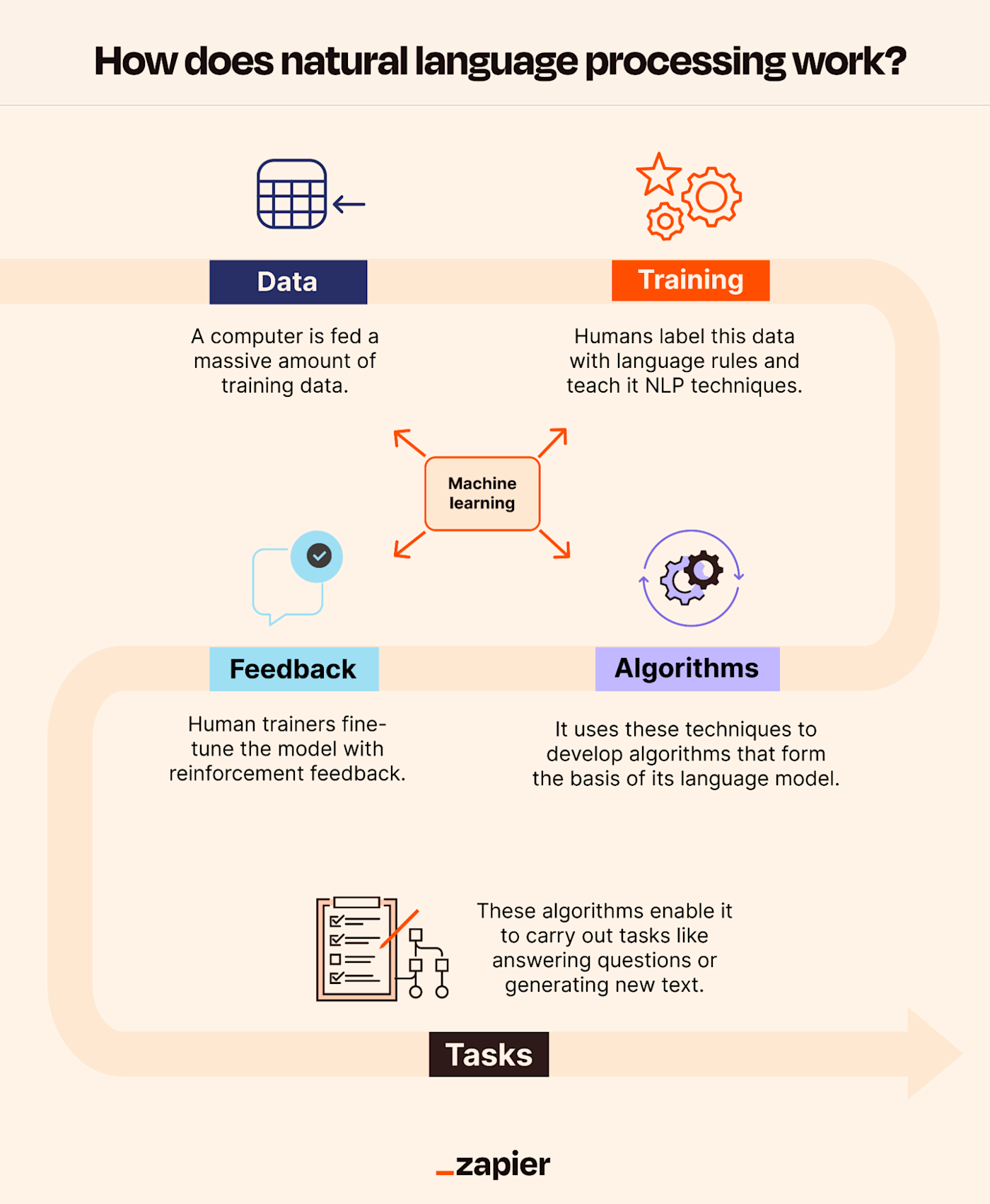
Core Components of NLP NLP systems typically consist of several key components that work together to process and understand language:
- Tokenization The process of breaking down text into smaller units called tokens, which can be words, phrases, or sentences. For example, the sentence "Natural language processing is fascinating" might be tokenized into ["Natural", "language", "processing", "is", "fascinating"].
- Text Normalization Techniques like lowercasing, stemming (reducing words to their root form, e.g., "running" → "run"), and lemmatization (reducing words to their dictionary form, e.g., "better" → "good") are used to standardize text and reduce variability.
- Part-of-Speech (POS) Tagging Assigning grammatical labels (e.g., noun, verb, adjective) to each token in a sentence. For example, in the sentence "She runs quickly," "She" is tagged as a pronoun, "runs" as a verb, and "quickly" as an adverb.
- Parsing Analyzing the syntactic structure of a sentence to determine relationships between words. Dependency parsing identifies the grammatical structure, while constituency parsing breaks sentences into hierarchical phrases (e.g., noun phrases, verb phrases).
- Named Entity Recognition (NER) Identifying and classifying named entities in text, such as people, organizations, locations, dates, and monetary values. For example, in the sentence "Apple Inc. is based in Cupertino, California," "Apple Inc." is recognized as an organization, and "Cupertino, California" as a location.
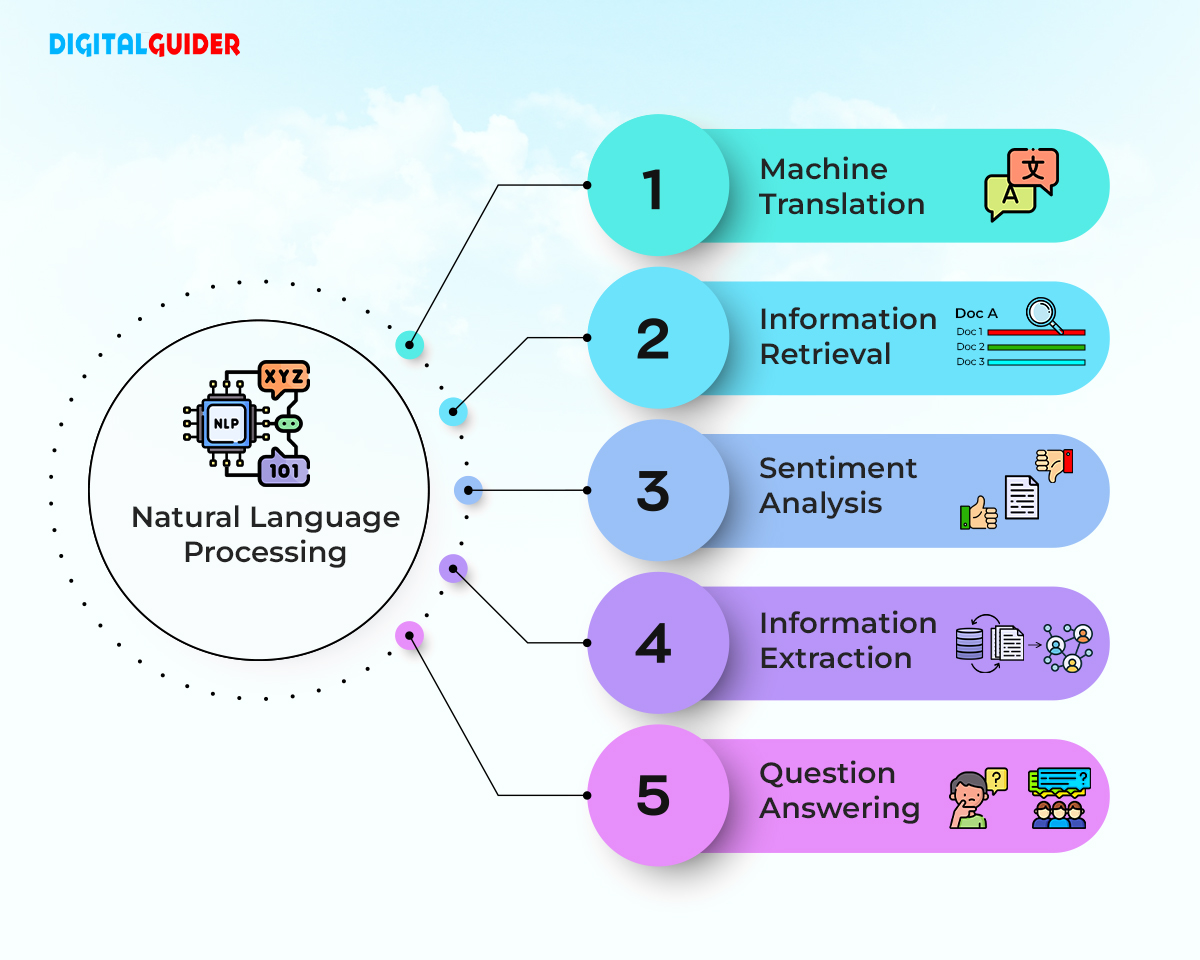
- Sentiment Analysis Determining the emotional tone of a piece of text, whether it is positive, negative, or neutral. This is widely used in social media monitoring, customer feedback analysis, and brand reputation management.
- Machine Translation Automatically translating text from one language to another. Modern systems, such as those based on the Transformer architecture, use deep learning to produce high-quality translations by modeling the context and semantics of the source text.
- Text Generation Generating human-like text based on a given prompt or context. Applications include chatbots, content creation, and automated storytelling. Models like GPT-3 and GPT-4 are capable of generating coherent and contextually relevant text.
Key Techniques and Models Modern NLP relies on a variety of techniques and models to achieve its goals:
- Traditional Machine Learning Models Algorithms like Naive Bayes, Support Vector Machines (SVMs), and Random Forests are used for tasks such as text classification and sentiment analysis. These models require feature engineering, where human experts define relevant features (e.g., word frequencies, n-grams) to train the model.
- Neural Networks Deep learning models, particularly Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), have become dominant in NLP due to their ability to learn patterns from raw text data. RNNs, including LSTMs and GRUs, are particularly effective for sequence modeling tasks like language translation and text generation.
- Attention Mechanisms Introduced in the Transformer architecture, attention mechanisms allow models to dynamically focus on different parts of the input text, improving their ability to handle long-range dependencies and context. This innovation led to the development of models like BERT, RoBERTa, and T5, which have set new benchmarks in NLP tasks.
- Pretrained Language Models Models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pretrained Transformer) are pretrained on massive amounts of text data using unsupervised learning. These models can then be fine-tuned for specific tasks, such as question answering, text classification, or named entity recognition, with relatively small amounts of task-specific data.
- Multimodal NLP Combining text with other modalities, such as images or audio, to enable more comprehensive understanding. For example, Visual Question Answering (VQA) systems use both image and text inputs to answer questions about visual content.
#Important Facts
- NLP is Everywhere NLP is embedded in numerous technologies we use daily, including search engines (e.g., Google), virtual assistants (e.g., Siri, Alexa), email filters (e.g., spam detection), and social media platforms (e.g., sentiment analysis, content moderation).
- Languages and Dialects NLP systems are increasingly capable of handling multiple languages, though performance varies significantly across languages due to differences in linguistic structure, available training data, and computational resources.
- Bias and Fairness NLP models can inherit biases present in their training data, leading to unfair or discriminatory outcomes. Addressing bias in NLP is an active area of research, with efforts focused on creating more diverse and representative datasets and developing fairness-aware algorithms.
- Explainability Many advanced NLP models, particularly deep learning-based ones, are often considered "black boxes" due to their complexity. Research in explainable AI (XAI) aims to make these models more transparent and interpretable.
- Ethical Considerations NLP raises ethical concerns related to privacy (e.g., processing sensitive text data), misinformation (e.g., deepfake text generation), and the potential for misuse in applications like automated propaganda or harassment.
- Performance Metrics Evaluating NLP systems involves metrics like accuracy, precision, recall, F1-score, and BLEU score (for machine translation). Human evaluation is also critical for assessing the quality of generated text or conversational agents.
- Hardware Requirements Training large NLP models requires significant computational resources, including high-performance GPUs or TPUs and large-scale storage for datasets. This has led to the rise of cloud-based NLP services, which provide access to powerful models without requiring extensive local infrastructure.
#Timeline
- Foundational ideas
Core concepts and early methods shape Natural Language Processing for Dummies: a Beginner’s Overview.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Natural Language Processing for Dummies: a Beginner’s Overview cover?
Covers natural language processing for dummies: a beginner’s overview, including core concepts, practical examples, benefits, limitations, and risks in Language AI.
Why is Natural Language Processing for Dummies: a Beginner’s Overview important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Natural, Language, Processing before using the ideas in real projects.
#References
- Natural Language Processing for Dummies: a Beginner’s Overview terminology and background research
- Natural Language Processing for Dummies: a Beginner’s Overview use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Natural case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.