
#Short Answer
Traces timeline of deep learning, highlighting major milestones, context, examples, and future implications.
#Infobox
#Overview
Deep learning, a subset of machine learning, relies on artificial neural networks with multiple layers to model and solve complex problems. Unlike traditional machine learning, which often requires manual feature extraction, deep learning automatically learns hierarchical representations from raw data. This capability has revolutionized fields such as computer vision, natural language processing (NLP), and autonomous systems. The Timeline of Deep Learning documents the theoretical, algorithmic, and computational advancements that enabled the field to progress from rudimentary models to state-of-the-art systems capable of surpassing human performance in specific tasks. The evolution of deep learning can be segmented into distinct phases:
- Foundational Theories (1940s–1960s): Early work on neural networks and cybernetics.
- First Wave (1960s–1980s): Development of perceptrons and early backpropagation.
- Second Wave (1980s–2000s): Revival of neural networks with improved hardware and algorithms.
- Modern Era (2010s–Present): Breakthroughs in deep neural networks, large-scale training, and real-world applications.
#History / Background
#Early Foundations (Pre-1950s)
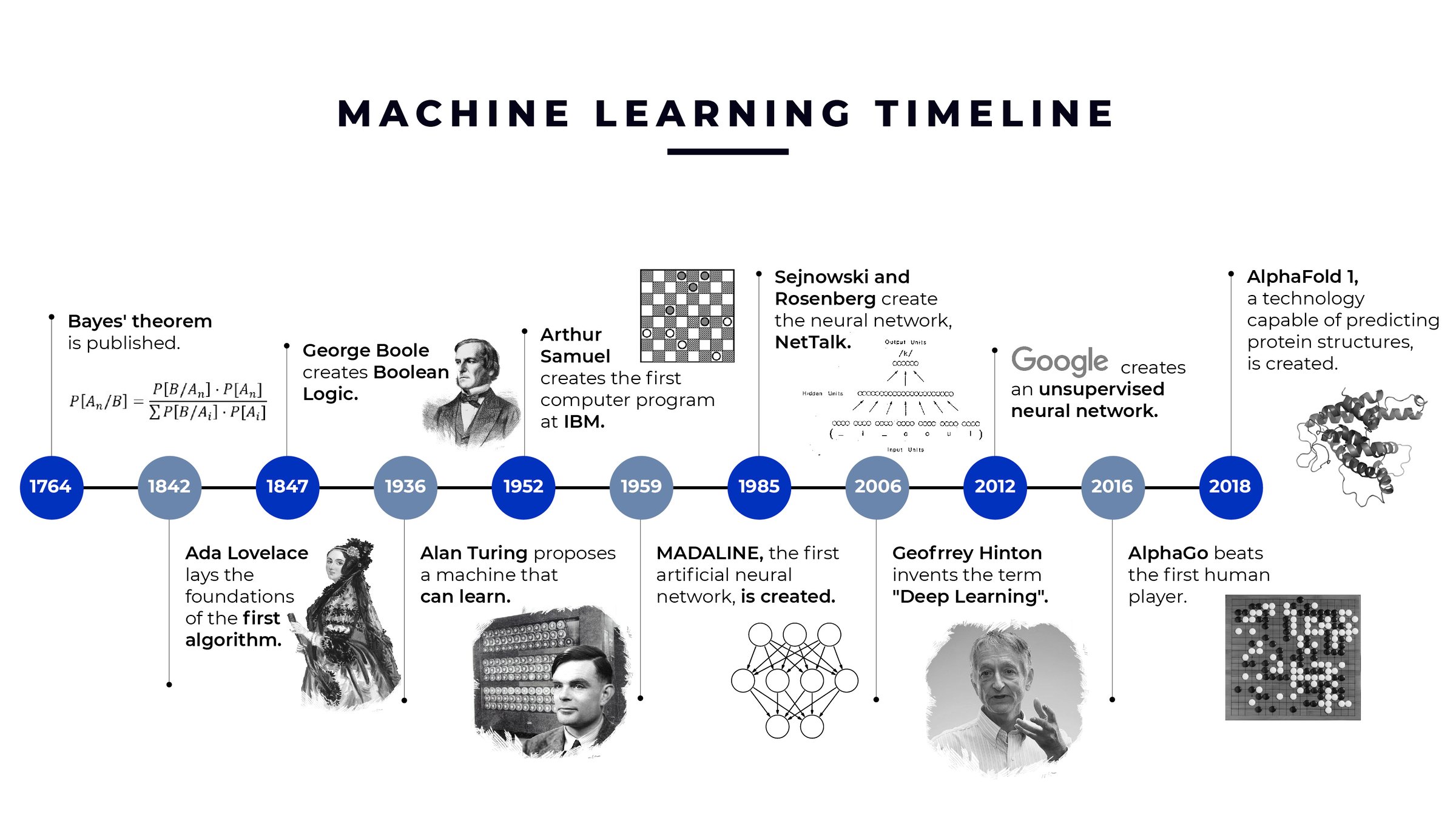
The conceptual roots of deep learning trace back to the 1940s, with the work of Warren McCulloch and Walter Pitts, who proposed the first mathematical model of a neuron in 1943. Their model, inspired by biological neural networks, laid the groundwork for artificial neural networks (ANNs). In 1949, Donald Hebb introduced the concept of synaptic plasticity, now known as Hebbian learning, which posits that neural connections strengthen with repeated activation.
#The Perceptron Era (1950s–1960s)
The first practical neural network model, the Perceptron, was introduced by Frank Rosenblatt in 1958. The Perceptron was a single-layer neural network capable of binary classification, trained using a learning algorithm that adjusted weights based on input data. However, its limitations were exposed in 1969 when Marvin Minsky and Seymour Papert published Perceptrons, demonstrating that single-layer networks could not solve linearly inseparable problems. This critique temporarily stifled research in neural networks.
#The AI Winter and Revival (1970s–1980s)
During the AI Winter (a period of reduced funding and interest in AI research), neural networks received little attention. However, key developments continued:
- 1974: Paul Werbos proposed the backpropagation algorithm, a method for training multi-layer neural networks by propagating errors backward through the network. This work was largely overlooked at the time.
- 1982: John Hopfield introduced Hopfield networks, a type of recurrent neural network (RNN) used for associative memory tasks.
- 1986: Geoffrey Hinton, David Rumelhart, and Ronald Williams popularized backpropagation in their seminal paper, demonstrating its effectiveness in training multi-layer networks. This marked the beginning of the second wave of neural network research.
#The 1990s: Advancements and Challenges The 1990s saw incremental progress but also persistent challenges:
- 1990: Yann LeCun and colleagues developed LeNet-5, a convolutional neural network (CNN) for handwritten digit recognition, which became a foundational model for computer vision.
- 1997: Sepp Hochreiter and Jürgen Schmidhuber introduced the Long Short-Term Memory (LSTM) network, a type of RNN designed to overcome the vanishing gradient problem, enabling better performance in sequential data tasks like speech recognition.
- 1998: Yoshua Bengio and others published foundational work on training deep neural networks, emphasizing the importance of unsupervised pre-training.
#The Deep Learning Revolution (2000s–2010s)
The 2000s witnessed a deep learning renaissance, driven by three key factors:
- Increased Computing Power: The advent of GPUs (graphics processing units) in the mid-2000s enabled efficient parallel computation, crucial for training large neural networks.
- Big Data: The explosion of digital data (e.g., images, text, speech) provided the raw material for training deep models.
- Algorithmic Innovations: Breakthroughs in optimization, regularization, and network architectures improved performance and scalability.
Key Milestones:
- 2006: Geoffrey Hinton and Ruslan Salakhutdinov demonstrated that deep belief networks (DBNs) could be trained effectively using greedy layer-wise unsupervised pre-training, followed by fine-tuning with labeled data.
- 2012: Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton developed AlexNet, a deep CNN that won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) with a significant margin, showcasing the power of deep learning in computer vision.
- 2014: Ian Goodfellow introduced Generative Adversarial Networks (GANs), a framework for training generative models by pitting two neural networks against each other.
- 2016: DeepMind’s AlphaGo defeated Lee Sedol, a world champion Go player, using a combination of deep neural networks and reinforcement learning, marking a historic milestone in AI.
#The Modern Era (2020s–Present)
The 2020s have seen deep learning permeate nearly every aspect of technology:
- Transformers and Attention Mechanisms: Introduced in the 2017 paper "Attention Is All You Need" by Vaswani et al., the Transformer architecture revolutionized NLP and beyond, enabling models like BERT, GPT-3, and DALL·E.
- Self-Supervised Learning: Techniques like contrastive learning and masked language modeling have reduced reliance on labeled data, expanding the applicability of deep learning.
- Multimodal Models: Models such as CLIP and Stable Diffusion integrate vision and language, enabling cross-modal understanding.
- Ethical and Regulatory Challenges: As deep learning systems become more powerful, concerns about bias, privacy, and accountability have gained prominence, leading to calls for responsible AI development.
#How It Works
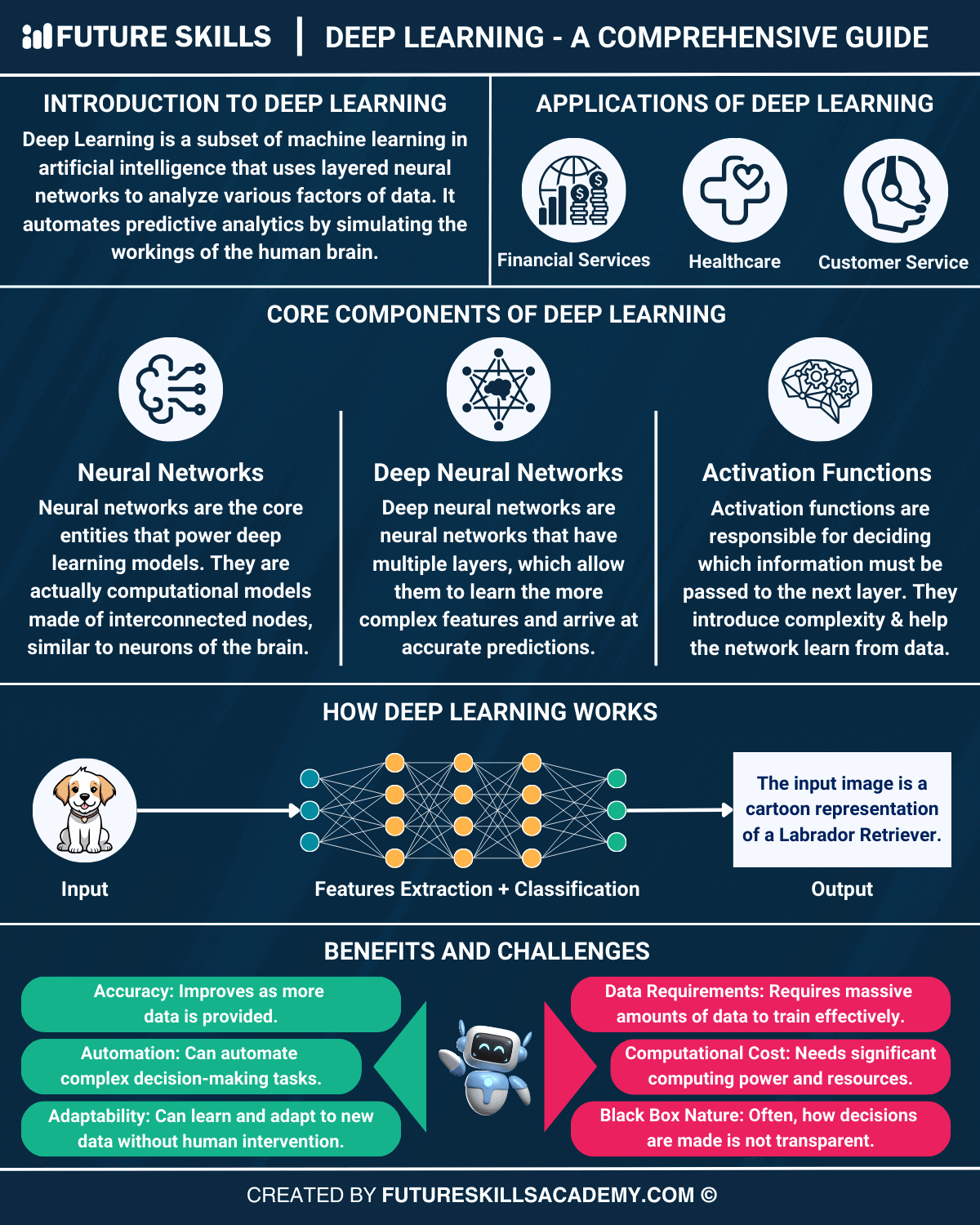
#Core Principles Deep learning models are inspired by the structure and function of the human brain, comprising interconnected layers of artificial neurons (nodes). Each layer transforms its input into a more abstract representation, enabling the network to learn complex patterns.
#Key Components
- Neural Networks:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Intermediate layers that apply transformations using weights and activation functions (e.g., ReLU, sigmoid).
- Output Layer: Produces the final prediction or classification.
- Activation Functions: - Introduce non-linearity, allowing the network to model complex relationships. Common functions include:
- ReLU (Rectified Linear Unit):
f(x) = max(0, x) - Sigmoid:
f(x) = 1 / (1 + e^(-x)) - Tanh:
f(x) = (e^x - e^(-x)) / (e^x + e^(-x))
- Loss Functions: - Measure the difference between predicted and actual outputs, guiding the optimization process. Examples:
- Mean Squared Error (MSE): Used for regression tasks.
- Cross-Entropy Loss: Used for classification tasks.
- Optimization Algorithms: - Adjust the weights of the network to minimize the loss function. Popular methods include:
- Stochastic Gradient Descent (SGD)
- Adam: An adaptive learning rate optimizer.
- RMSprop: Combines the benefits of SGD and momentum.
- Backpropagation: - A supervised learning algorithm that computes the gradient of the loss function with respect to each weight, enabling efficient weight updates via gradient descent.
#Types of Deep Learning Models
- Feedforward Neural Networks (FNNs): - The simplest form, where data flows in one direction from input to output.
- Convolutional Neural Networks (CNNs): - Specialized for grid-like data (e.g., images), using convolutional layers to detect local patterns (e.g., edges, textures).
- Recurrent Neural Networks (RNNs): - Designed for sequential data (e.g., time series, text), with loops that allow information to persist across time steps. Variants include:
- LSTM (Long Short-Term Memory)
- GRU (Gated Recurrent Unit)
- Transformer Networks: - Rely on self-attention mechanisms to weigh the importance of different parts of the input, enabling parallel processing of sequences. Foundational to models like BERT and GPT.
- Generative Models:
- GANs (Generative Adversarial Networks): Comprise a generator and discriminator competing in a zero-sum game.
- VAEs (Variational Autoencoders): Learn to encode and decode data probabilistically.
- Diffusion Models: Generate data by gradually denoising a random input.
- Reinforcement Learning (RL): - Combines deep learning with reinforcement learning to train agents to make sequences of decisions (e.g., AlphaGo, DQN).
#Important Facts
- Moore’s Law and GPUs: The exponential growth in computing power, driven by Moore’s Law and the adoption of GPUs, has been critical to training deep neural networks.
- Big Data: The availability of large datasets (e.g., ImageNet, Common Crawl) has enabled deep learning models to achieve human-level performance in tasks like image classification and language understanding.
- Transfer Learning: Pre-trained models (e.g., ResNet, BERT) can be fine-tuned for specific tasks, reducing the need for large labeled datasets.
- Explainability: Deep learning models are often criticized for their "black box" nature, leading to research in explainable AI (XAI) to interpret model decisions.
- Energy Consumption: Training large deep learning models (e.g., GPT-3) requires significant computational resources, raising concerns about environmental impact.
- Bias and Fairness: Deep learning models can inherit biases present in training data, necessitating techniques like fairness-aware training and debiasing.
#Timeline
- Foundational ideas
Core concepts and early methods shape Timeline of Deep Learning.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Timeline of Deep Learning cover?
Traces timeline of deep learning, highlighting major milestones, context, examples, and future implications.
Why is Timeline of Deep Learning important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Timeline, Deep, Learning before using the ideas in real projects.
#References
- Timeline of Deep Learning terminology and background research
- Timeline of Deep Learning use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Timeline case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.