
#Short Answer
Covers understanding deep learning: a comprehensive guide, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Deep learning represents a transformative paradigm in artificial intelligence (AI), enabling systems to learn from vast amounts of data through layered neural networks. Unlike traditional machine learning models, which rely on handcrafted features, deep learning algorithms automatically extract hierarchical representations from raw input, making them exceptionally powerful for tasks such as image recognition, natural language processing (NLP), and predictive analytics. Understanding Deep Learning: A Comprehensive Guide for Tech Enthusiasts serves as an accessible entry point for individuals seeking to grasp the core principles of deep learning. The guide demystifies complex concepts such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers, while emphasizing their practical applications in modern technology. By bridging the gap between theoretical foundations and real-world implementations, the resource empowers readers to apply deep learning techniques in projects ranging from chatbots to autonomous vehicles. The guide also addresses common misconceptions, such as the belief that deep learning requires extensive mathematical expertise. While a foundational understanding of linear algebra and calculus is beneficial, the resource simplifies explanations to ensure accessibility for non-experts. Additionally, it highlights the ethical considerations surrounding AI, including bias in datasets and the environmental impact of training large models.
#History / Background
#Early Foundations (1940s–1980s)
The conceptual roots of deep learning trace back to the 1940s with the work of Warren McCulloch and Walter Pitts, who proposed the first mathematical model of a neural network. Their "threshold logic unit" laid the groundwork for artificial neurons, mimicking the biological processes of the human brain. In 1958, Frank Rosenblatt developed the Perceptron, an early form of a neural network capable of binary classification. However, limitations in computational power and algorithmic complexity restricted its practical applications. The 1980s marked a resurgence of interest in neural networks, driven by the backpropagation algorithm, which enabled efficient training of multi-layer networks. Geoffrey Hinton, David Rumelhart, and Ronald Williams demonstrated its effectiveness in 1986, proving that neural networks could learn hierarchical representations. Despite these advances, the field faced skepticism due to the "AI winter" of the 1990s, a period marked by reduced funding and diminished public interest in AI research.
#The Deep Learning Renaissance (2000s–Present)
The turn of the 21st century witnessed a revival of deep learning, fueled by three key developments:
- Increased Computational Power: The advent of graphics processing units (GPUs) accelerated the training of large neural networks.
- Big Data: The proliferation of digital data provided the necessary fuel for training complex models.
- Algorithmic Innovations: Breakthroughs such as the rectified linear unit (ReLU) activation function and dropout regularization improved model performance and generalization. In 2012, a landmark achievement occurred when a deep learning model, AlexNet, won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) by a significant margin. This victory demonstrated the superiority of deep neural networks in image classification tasks and catalyzed widespread adoption across industries. Subsequent milestones included Google’s AlphaGo defeating world champion Go players in 2016, and the development of large language models (LLMs) like OpenAI’s GPT series, which revolutionized natural language understanding. Today, deep learning underpins many cutting-edge technologies, from facial recognition systems to generative AI tools like DALL·E and Stable Diffusion. The field continues to evolve, with ongoing research focused on improving model efficiency, interpretability, and ethical deployment.
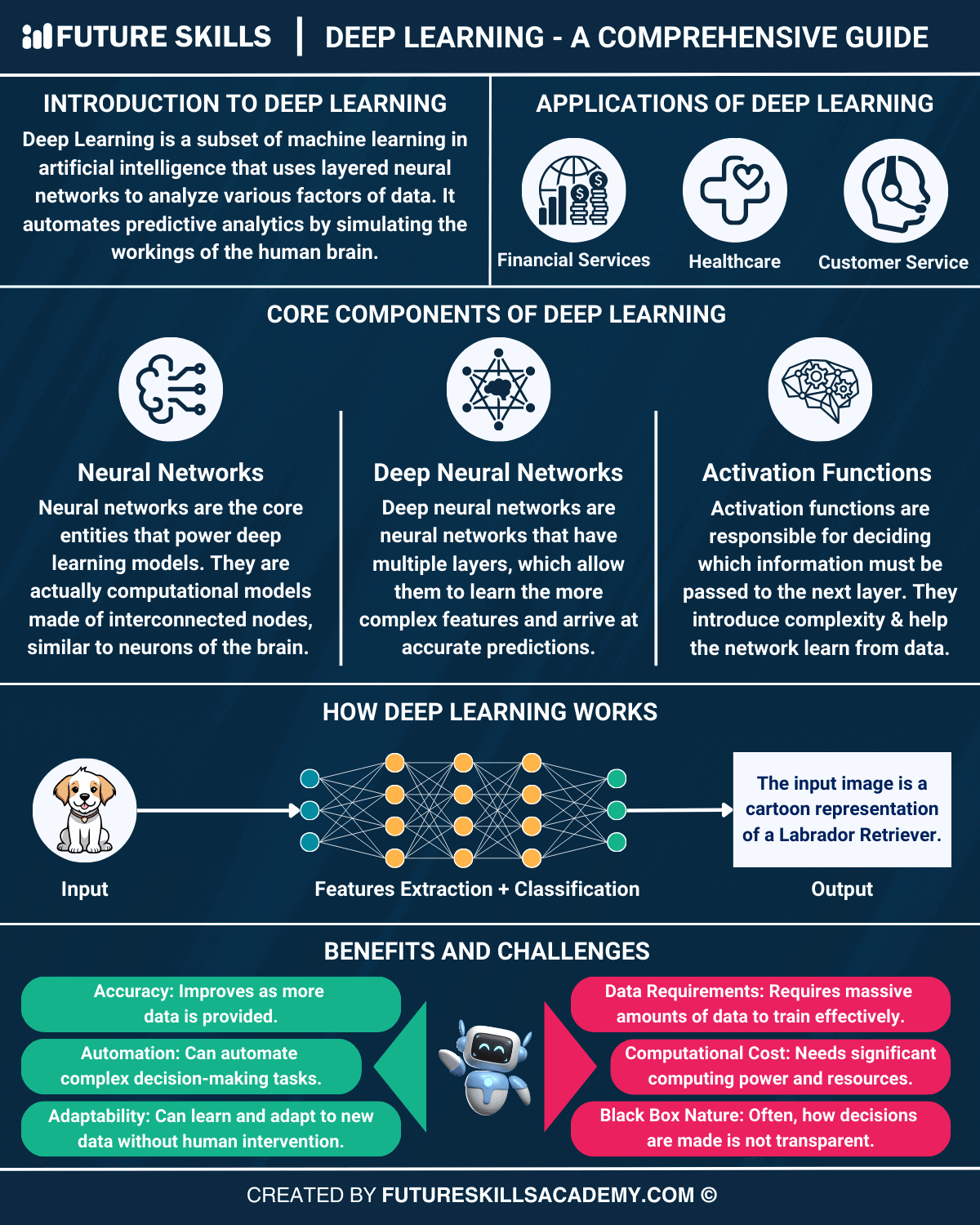
#How It Works
#Neural Networks: The Building Blocks At the heart of deep learning are artificial neural networks (ANNs), computational models inspired by the structure and function of biological neural networks. An ANN consists of interconnected layers of nodes (neurons), each performing simple mathematical operations. The three primary types of layers are:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Intermediate layers where data is processed through weighted connections and activation functions. Deep learning models typically feature multiple hidden layers, enabling them to learn intricate patterns.
- Output Layer: Produces the final prediction or classification (e.g., identifying an object in an image or generating text).
#Key Components
- Weights and Biases: Parameters adjusted during training to minimize prediction errors. Weights determine the strength of connections between neurons, while biases allow for shifting the activation function.
- Activation Functions: Non-linear functions (e.g., ReLU, sigmoid, tanh) introduced to enable neural networks to model complex relationships. ReLU (Rectified Linear Unit) is widely used due to its simplicity and effectiveness in mitigating the vanishing gradient problem.
- Loss Functions: Metrics (e.g., mean squared error, cross-entropy loss) that quantify the difference between predicted and actual outputs, guiding the optimization process.
- Optimization Algorithms: Techniques like stochastic gradient descent (SGD) and its variants (e.g., Adam, RMSprop) that iteratively adjust weights to minimize loss.
#Training a Deep Learning Model The training process involves the following steps:
- Data Preparation: Raw data is preprocessed (e.g., normalized, augmented) to improve model performance.
- Forward Propagation: Input data is passed through the network, generating predictions.
- Loss Calculation: The difference between predictions and ground truth is computed using the loss function.
- Backpropagation: The gradient of the loss function is calculated with respect to each weight, and weights are updated via the optimization algorithm.
- Iteration: Steps 2–4 are repeated over multiple epochs (training cycles) until the model achieves satisfactory accuracy.
#Types of Deep Learning Models
- Feedforward Neural Networks (FNNs): The simplest form, where data flows in one direction from input to output. Suitable for tabular data and basic classification tasks.
- Convolutional Neural Networks (CNNs): Specialized for grid-like data (e.g., images), using convolutional layers to detect local patterns such as edges and textures.
- Recurrent Neural Networks (RNNs): Designed for sequential data (e.g., time series, text), featuring loops that allow information to persist across time steps. Variants like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs) address the vanishing gradient problem in long sequences.
- Transformers: Introduced in the 2017 paper "Attention Is All You Need", transformers rely on self-attention mechanisms to process sequential data efficiently. They power modern NLP models like BERT and GPT.
- Generative Adversarial Networks (GANs): Comprising a generator and discriminator, GANs are used for generating realistic data (e.g., images, music) by pitting two networks against each other in a competitive training process.
#Challenges and Solutions
- Overfitting: When a model performs well on training data but poorly on unseen data. Mitigated through techniques like regularization (L1/L2), dropout, and early stopping.
- Vanishing/Exploding Gradients: Issues in training deep networks where gradients become too small or too large, hindering learning. Addressed via batch normalization, gradient clipping, and residual connections (e.g., in ResNet architectures).
- Computational Cost: Training large models requires significant resources. Solutions include distributed training, model pruning, and leveraging cloud-based platforms like Google’s TensorFlow and NVIDIA’s CUDA.
#Important Facts
- Deep learning models often require massive datasets to achieve high accuracy. For example, ImageNet, a benchmark dataset for image classification, contains over 14 million labeled images.
- The term "deep" refers to the number of hidden layers in a neural network. While traditional neural networks may have 1–2 hidden layers, deep networks can have dozens or even hundreds.
- Deep learning has surpassed human performance in specific tasks, such as image recognition (e.g., identifying objects in photos) and playing complex games (e.g., Go, chess).
- Transfer learning allows pre-trained models to be fine-tuned for new tasks with minimal data, reducing training time and computational costs.
- Explainable AI (XAI) is an emerging field focused on making deep learning models more interpretable, addressing concerns about "black box" decision-making.
- The carbon footprint of training large models is a growing concern. For instance, training a single large language model can emit as much CO₂ as five cars over their lifetimes, according to some estimates.
- Deep learning is not a silver bullet; it excels in pattern recognition but struggles with tasks requiring common sense, abstract reasoning, or causal understanding.
#Timeline
- Foundational ideas
Core concepts and early methods shape Understanding Deep Learning: a Comprehensive Guide.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Understanding Deep Learning: a Comprehensive Guide cover?
Covers understanding deep learning: a comprehensive guide, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Understanding Deep Learning: a Comprehensive Guide important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Understanding, Deep, Learning before using the ideas in real projects.
#References
- Understanding Deep Learning: a Comprehensive Guide terminology and background research
- Understanding Deep Learning: a Comprehensive Guide use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Understanding case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.