
#Short Answer
Covers the ultimate guide to ai algorithms, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
AI algorithms are the cornerstone of artificial intelligence, enabling machines to mimic human-like cognitive functions such as learning, problem-solving, and decision-making. These algorithms are structured sequences of instructions that process input data to produce meaningful outputs, often improving their performance over time through exposure to more data. The field of AI algorithms encompasses a broad spectrum of techniques, ranging from traditional statistical methods to cutting-edge deep learning models. At their core, AI algorithms rely on mathematical models and computational techniques to identify patterns, make predictions, and optimize outcomes. They are categorized based on their learning paradigms: supervised learning, where models are trained on labeled data; unsupervised learning, where models identify hidden patterns in unlabeled data; and reinforcement learning, where models learn through trial and error by interacting with an environment. Additionally, algorithms may be designed for specific tasks such as classification, regression, clustering, or dimensionality reduction. The versatility of AI algorithms has led to their widespread adoption across industries, including healthcare, finance, transportation, and entertainment. For instance, convolutional neural networks (CNNs) power image recognition systems, while recurrent neural networks (RNNs) and transformers enable natural language processing (NLP) applications like chatbots and translation services. The continuous evolution of these algorithms, driven by advances in computational power and data availability, has accelerated the progress of AI, making it one of the most transformative technologies of the 21st century.
#History / Background
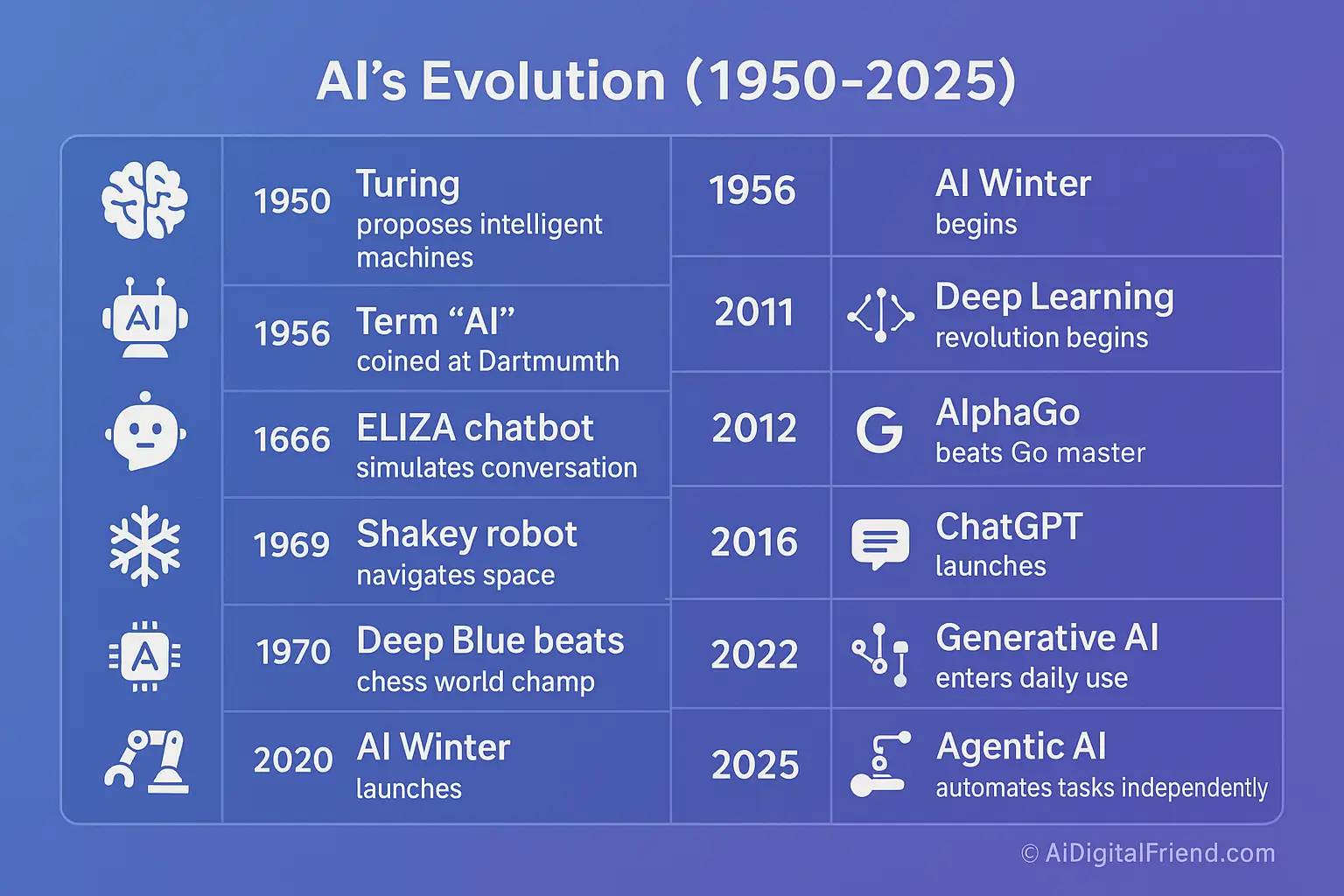
The development of AI algorithms traces back to the mid-20th century, with foundational work in mathematics, computer science, and cognitive psychology laying the groundwork for modern artificial intelligence. The concept of algorithms capable of learning from data emerged alongside early computing machines, though the term "artificial intelligence" was not coined until 1956 at the Dartmouth Conference.
#Early Foundations (1940s–1950s)
The theoretical underpinnings of AI algorithms were established by pioneers such as Alan Turing, who proposed the concept of a universal machine capable of performing any computable task in his 1936 paper "On Computable Numbers". Turing’s work on the Turing Test (1950) further emphasized the importance of machine intelligence. Around the same time, Claude Shannon’s information theory provided a mathematical framework for processing and transmitting data, while Norbert Wiener’s cybernetics explored the parallels between machines and biological systems. The first practical AI algorithm was developed in 1952 by Arthur Samuel, who created a program that could play checkers and improve its performance through self-play. This marked the beginning of machine learning, a subset of AI focused on algorithms that learn from experience. Samuel’s work demonstrated that machines could adapt their strategies based on feedback, a principle that remains central to modern AI.
#The Golden Age (1956–1974)
The period from 1956 to 1974 is often referred to as the "Golden Age" of AI, characterized by optimism and rapid progress. Key milestones during this era included:
- 1956: The Dartmouth Conference, organized by John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon, officially coined the term "artificial intelligence" and set ambitious goals for the field.
- 1958: Frank Rosenblatt developed the Perceptron, an early neural network model inspired by biological neurons. The Perceptron could learn to classify data linearly, though its limitations were later exposed by Marvin Minsky and Seymour Papert in 1969.
- 1966: Joseph Weizenbaum created ELIZA, an early natural language processing program that simulated conversation by using pattern matching and substitution techniques. ELIZA demonstrated the potential of AI to interact with humans in a seemingly intelligent manner.
#The AI Winter (1974–1980) and Revival (1980–1990s)
Despite early enthusiasm, AI research faced significant challenges, including limited computational power and unrealistic expectations. The AI Winter (1974–1980) was marked by reduced funding and skepticism toward the field. However, the 1980s saw a resurgence with the advent of expert systems, which used rule-based algorithms to mimic human decision-making in specific domains. Key developments during this period included:
- 1981: Japan’s Fifth Generation Computer Systems project aimed to create AI-powered computers capable of reasoning and natural language processing, though it ultimately fell short of its goals.
- 1986: Backpropagation, a method for training neural networks, was popularized by David Rumelhart, Geoffrey Hinton, and Ronald Williams. This algorithm enabled neural networks to learn from errors, paving the way for deep learning.
- 1997: IBM’s Deep Blue defeated world chess champion Garry Kasparov, showcasing the power of AI in complex decision-making tasks.
#The Modern Era (2000s–Present)
The 21st century has witnessed an explosion in AI algorithm development, driven by three key factors:
- Big Data: The availability of vast datasets enabled algorithms to learn from diverse and extensive information.
- Computational Power: Advances in hardware, particularly GPUs and TPUs, accelerated the training of complex models.
- Algorithmic Innovations: Breakthroughs such as deep learning, transformers, and reinforcement learning have revolutionized AI capabilities. Notable milestones in this era include:
- 2012: AlexNet, a deep convolutional neural network, achieved unprecedented accuracy in the ImageNet competition, sparking the deep learning revolution.
- 2016: AlphaGo, developed by DeepMind, defeated the world champion Go player, demonstrating the power of reinforcement learning in complex strategy games.
- 2020: GPT-3, a transformer-based language model, showcased the potential of large-scale NLP models, enabling human-like text generation.
- 2022: Stable Diffusion and DALL·E 2 introduced AI-generated art, highlighting the creative applications of generative algorithms.
#How It Works
AI algorithms operate through a series of structured steps that transform input data into actionable insights or decisions. The specific mechanics vary depending on the algorithm type, but the general process involves data preprocessing, model training, evaluation, and deployment.
#Core Components of AI Algorithms
- Data Collection and Preprocessing
- Data Collection: Algorithms require high-quality data to learn effectively. This data can be structured (e.g., spreadsheets) or unstructured (e.g., text, images, audio).
- Preprocessing: Raw data is cleaned, normalized, and transformed to remove noise, handle missing values, and ensure consistency. Techniques include:
- Normalization: Scaling data to a standard range (e.g., 0 to 1).
- Feature Extraction: Identifying relevant attributes (features) from raw data.
- Encoding: Converting categorical data (e.g., text labels) into numerical formats (e.g., one-hot encoding).
- Model Selection and Training
- Algorithm Choice: The selection of an algorithm depends on the problem type (e.g., classification, regression, clustering) and data characteristics. Common algorithms include:
- Supervised Learning: Linear regression, logistic regression, support vector machines (SVMs), decision trees, and neural networks.
- Unsupervised Learning: K-means clustering, hierarchical clustering, principal component analysis (PCA), and autoencoders.
- Reinforcement Learning: Q-learning, deep Q-networks (DQN), and policy gradient methods.
- Training: The model learns from the training data by adjusting its internal parameters to minimize an objective function (e.g., loss function). For example: - In neural networks, weights are updated using backpropagation and optimization techniques like gradient descent. - In decision trees, the algorithm splits data based on feature values to maximize information gain.
- Evaluation and Validation
- Performance Metrics: The model’s effectiveness is measured using metrics such as:
- Accuracy: The proportion of correct predictions.
- Precision and Recall: Used in classification tasks to evaluate true positives and false positives.
- Mean Squared Error (MSE): Measures the average squared difference between predicted and actual values in regression tasks.
- F1 Score: The harmonic mean of precision and recall, useful for imbalanced datasets.
- Validation Techniques: Techniques like cross-validation and holdout validation ensure the model generalizes well to unseen data.
- Deployment and Monitoring
- Deployment: The trained model is integrated into applications or systems (e.g., chatbots, recommendation engines, autonomous vehicles).
- Monitoring: Continuous evaluation of the model’s performance in real-world scenarios helps identify drift (changes in data distribution) or degradation over time. Techniques like A/B testing and online learning are used to adapt to new data.
#Key Algorithm Types and Their Mechanics
| Algorithm Type | Description | Example Use Cases | |--------------------------|---------------------------------------------------------------------------------|-----------------------------------------------| | Linear Regression | Models the relationship between a dependent variable and one or more independent variables using a linear equation. | Predicting house prices, sales forecasting. | | Logistic Regression | A classification algorithm that predicts binary outcomes using the logistic function. | Spam detection, medical diagnosis. | | Decision Trees | A tree-like model that splits data based on feature values to make decisions. | Customer segmentation, risk assessment. | | Support Vector Machines (SVMs) | Finds the optimal hyperplane to separate data points into classes. | Image classification, text categorization. | | K-Means Clustering | Partitions data into k clusters based on similarity. | Customer grouping, anomaly detection. | | Neural Networks | Mimics the human brain’s structure with interconnected layers of neurons. | Image recognition, speech synthesis. | | Convolutional Neural Networks (CNNs) | Specialized for processing grid-like data (e.g., images) using convolutional layers. | Facial recognition, medical imaging. | | Recurrent Neural Networks (RNNs) | Designed for sequential data (e.g., time series, text) using loops to retain memory. | Language translation, stock price prediction. | | Transformers | Uses self-attention mechanisms to process sequential data efficiently. | Chatbots, text generation (e.g., GPT models).| | Q-Learning | A reinforcement learning algorithm that learns optimal actions through rewards. | Game AI (e.g., AlphaGo), robotics. |
#Important Facts
- Bias-Variance Tradeoff: AI algorithms must balance bias (error due to overly simplistic assumptions) and variance (error due to excessive complexity). High bias leads to underfitting, while high variance causes overfitting.
- Curse of Dimensionality: As the number of features in a dataset increases, the data becomes sparse, making it harder for algorithms to learn meaningful patterns. Techniques like PCA and feature selection mitigate this issue.
- Overfitting vs. Underfitting:
- Overfitting: The model performs well on training data but poorly on unseen data due to memorization.
- Underfitting: The model is too simple to capture the underlying patterns in the data.
- Explainability: Many advanced AI algorithms (e.g., deep neural networks) are "black boxes," making it difficult to interpret their decisions. Techniques like SHAP values and LIME aim to improve explainability.
- Ethical Considerations: AI algorithms can perpetuate biases present in training data, leading to unfair outcomes. Ethical AI practices emphasize fairness, transparency, and accountability.
- Hardware Acceleration: Training complex models often requires specialized hardware like GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units) to handle large-scale computations efficiently.
- Transfer Learning: Pre-trained models (e.g., BERT, ResNet) can be fine-tuned for specific tasks, reducing the need for extensive training data and computational resources.
- Federated Learning: A decentralized approach where models are trained across multiple devices without sharing raw data, enhancing privacy.
#Timeline
- Foundational ideas
Core concepts and early methods shape The Ultimate Guide to AI Algorithms.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does The Ultimate Guide to AI Algorithms cover?
Covers the ultimate guide to ai algorithms, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is The Ultimate Guide to AI Algorithms important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Ultimate, AI, Algorithms before using the ideas in real projects.
#References
- The Ultimate Guide to AI Algorithms terminology and background research
- The Ultimate Guide to AI Algorithms use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Ultimate case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.