#Short Answer
Traces the rise of natural language processing: a historical perspective, highlighting major milestones, context, examples, and future implications.
#Infobox
#Overview
Natural Language Processing (NLP) represents a pivotal intersection between linguistics, computer science, and artificial intelligence. Its primary goal is to bridge the gap between human communication and machine understanding, allowing computers to process and analyze vast amounts of natural language data efficiently. NLP systems are designed to perform tasks such as language translation, text summarization, sentiment analysis, and conversational AI, making them indispensable in modern digital ecosystems. The field has evolved from rule-based systems to sophisticated deep learning models capable of generating human-like text and comprehending complex linguistic structures. Today, NLP underpins technologies like virtual assistants (e.g., Siri, Alexa), automated customer service bots, and real-time translation tools (e.g., Google Translate). Its applications extend across industries, including healthcare, finance, education, and social media, where it enhances decision-making, automates workflows, and improves user experiences.
#History / Background
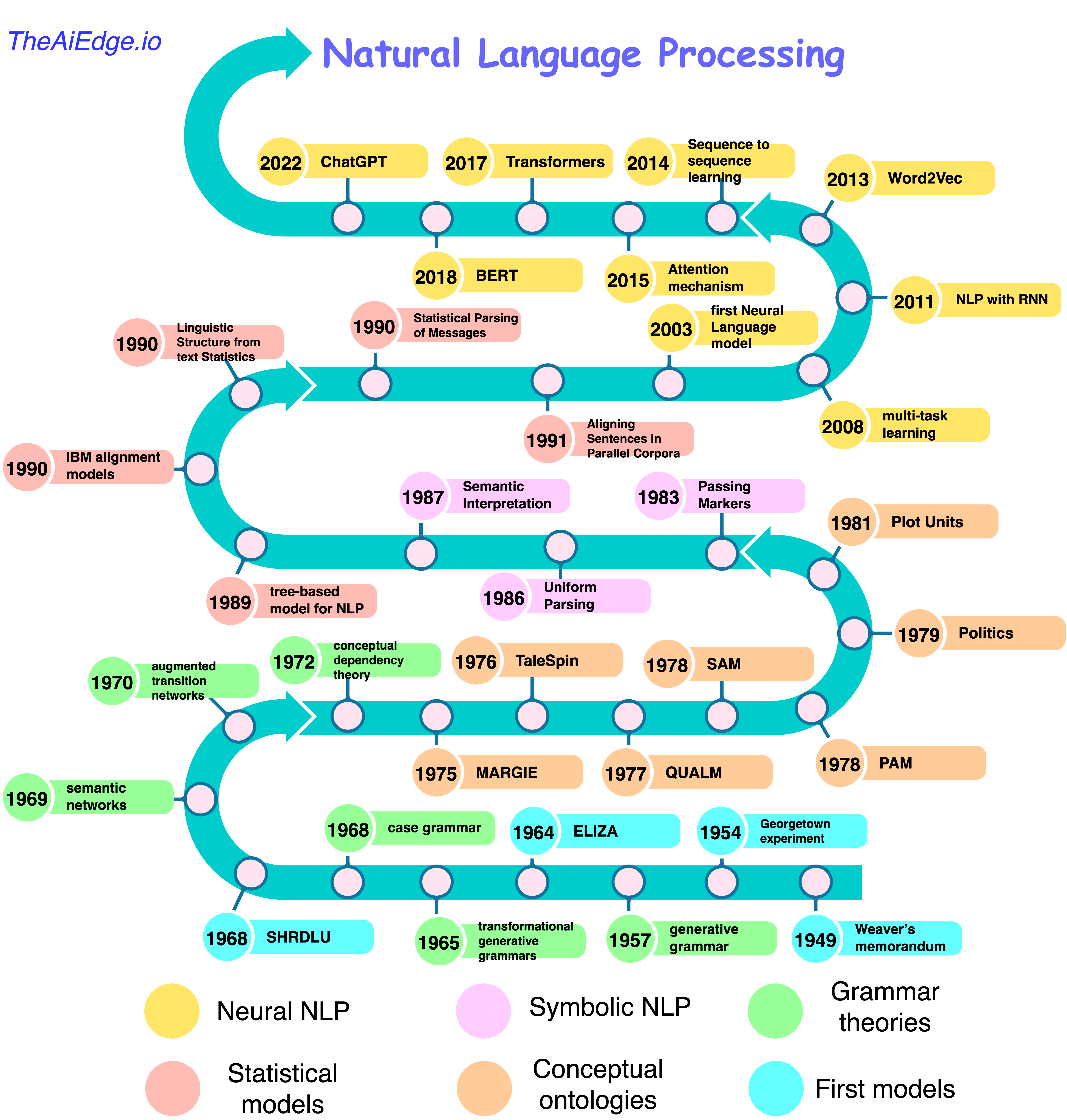
#Early Foundations (1950s–1960s)
The origins of NLP trace back to the 1950s, when researchers began exploring the possibility of machines understanding human language. In 1950, Alan Turing proposed the Imitation Game (later known as the Turing Test), a benchmark for evaluating a machine's ability to exhibit intelligent behavior indistinguishable from that of a human. This laid the conceptual groundwork for NLP by questioning whether machines could process and respond to language meaningfully. In 1954, IBM and Georgetown University demonstrated the first machine translation system, translating 60 Russian sentences into English. This early experiment sparked interest in computational linguistics, though its success was limited by the lack of linguistic resources and computational power. By the late 1960s, the field saw the development of ELIZA (1966), an early natural language processing program created by Joseph Weizenbaum at MIT. ELIZA simulated conversation by using pattern matching and substitution methodologies, mimicking a Rogerian psychotherapist. While rudimentary, it demonstrated the potential for machines to engage in dialogue.
#Rule-Based and Statistical Approaches (1970s–1990s)
During the 1970s and 1980s, NLP research focused on rule-based systems, where linguists manually encoded grammatical rules and lexicons into computer programs. Projects like SHRDLU (1972), developed by Terry Winograd, showcased how a computer could understand and manipulate language in a constrained environment (e.g., a virtual blocks world). However, these systems struggled with scalability and adaptability to real-world language variability. The 1990s marked a shift toward statistical methods, driven by advances in computational power and the availability of large text corpora. Researchers began using probabilistic models to analyze language patterns, leading to improvements in machine translation (e.g., IBM's statistical machine translation models) and speech recognition. The introduction of the Penn Treebank (1993), a corpus of parsed English sentences, provided a standardized dataset for training and evaluating NLP models.
#The Machine Learning Revolution (2000s–2010s)
The 2000s witnessed a paradigm shift with the adoption of machine learning techniques in NLP. Algorithms such as Support Vector Machines (SVMs) and Hidden Markov Models (HMMs) were used for tasks like part-of-speech tagging, named entity recognition, and sentiment analysis. The rise of the internet and social media generated massive amounts of unstructured text data, fueling the need for automated language processing tools. A major breakthrough came in 2011 with IBM Watson, a question-answering system that defeated human champions on the quiz show Jeopardy!. Watson demonstrated the power of combining NLP with large-scale data processing and machine learning. Around the same time, the introduction of word embeddings (e.g., Word2Vec in 2013) revolutionized how machines represented words, capturing semantic relationships in vector space.
#The Deep Learning Era (2010s–Present)
The mid-2010s marked the advent of deep learning in NLP, driven by the success of neural networks in image and speech recognition. Recurrent Neural Networks (RNNs), particularly Long Short-Term Memory (LSTM) networks, became the standard for sequence modeling tasks such as machine translation and text generation. However, RNNs faced limitations in handling long-range dependencies and parallelization. In 2017, the Transformer architecture was introduced in the paper "Attention Is All You Need" by Vaswani et al. Transformers replaced RNNs with self-attention mechanisms, enabling models to process entire sequences simultaneously and capture contextual relationships more effectively. This innovation led to the development of large language models (LLMs) such as BERT (2018), GPT (2018), and their successors, which achieved state-of-the-art performance across a wide range of NLP tasks. Today, NLP continues to advance with the integration of multimodal models (e.g., combining text and images), reinforcement learning for dialogue systems, and ethical considerations around bias and fairness in language models.
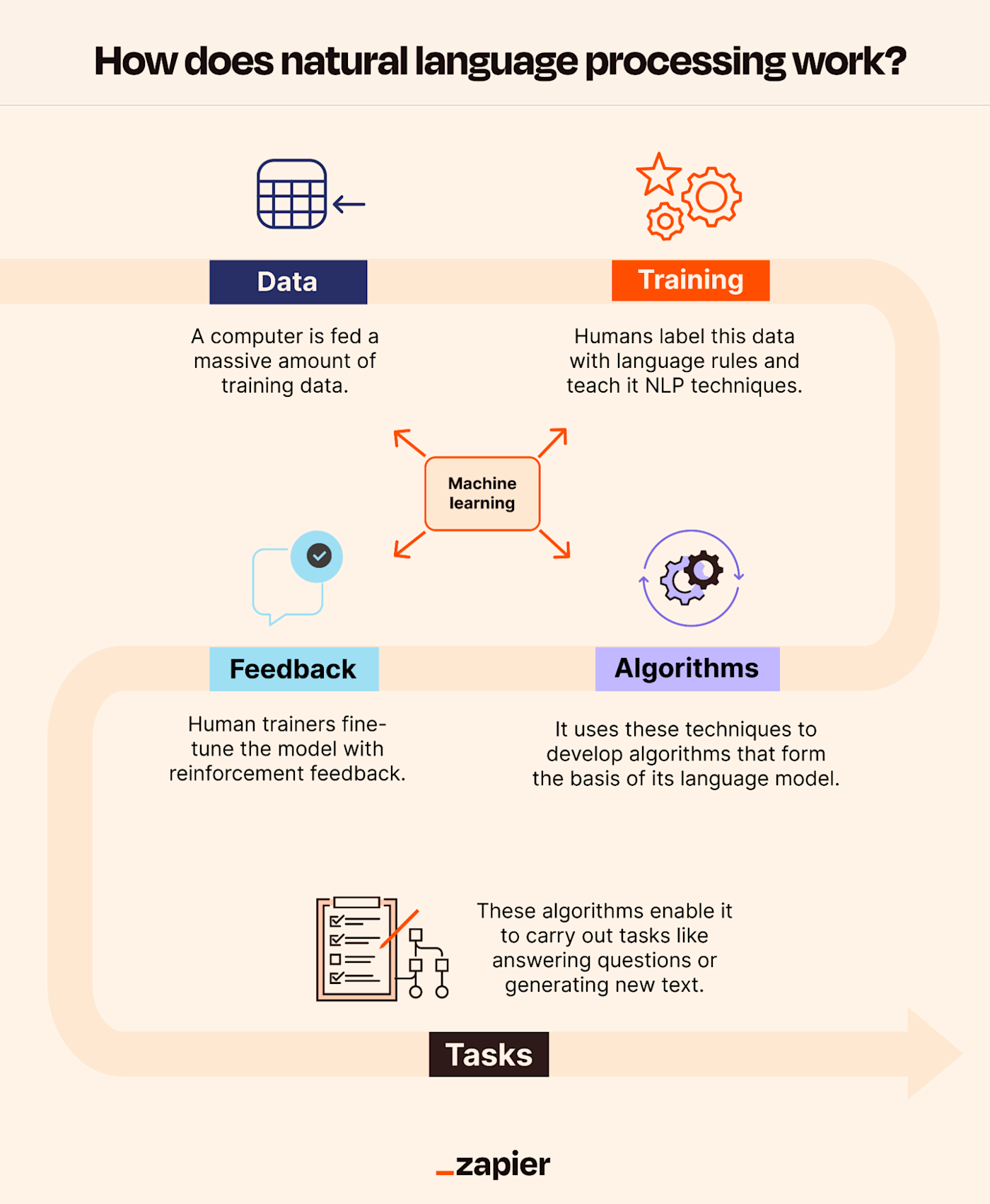
#How It Works
#Core Components of NLP NLP systems rely on several foundational components to process and understand human language:
- Tokenization: The process of breaking down text into smaller units (tokens), such as words, phrases, or sentences. For example, the sentence "Natural Language Processing is fascinating" might be tokenized into ["Natural", "Language", "Processing", "is", "fascinating"].
- Morphological Analysis: Involves analyzing the structure of words, including prefixes, suffixes, and roots. This helps in tasks like stemming (reducing words to their base form) and lemmatization (grouping different inflected forms of a word).
- Syntax Analysis: Examines the grammatical structure of sentences using parsing techniques such as constituency parsing and dependency parsing. This helps machines understand the relationships between words (e.g., subject-verb-object).
- Semantic Analysis: Focuses on the meaning of words and sentences. Techniques include word sense disambiguation (determining the correct meaning of a word in context) and semantic role labeling (identifying the roles of words in a sentence).
- Pragmatic Analysis: Considers the context in which language is used, including discourse analysis and speech act theory. This is crucial for understanding implied meanings, sarcasm, and conversational implicatures.
#Key Techniques
and Models
- Bag-of-Words (BoW): Represents text as the frequency of words, ignoring grammar and word order. Commonly used in early text classification tasks.
- TF-IDF (Term Frequency-Inverse Document Frequency): A statistical measure that evaluates the importance of a word in a document relative to a collection of documents.
- Word Embeddings: Dense vector representations of words that capture semantic relationships (e.g., Word2Vec, GloVe, FastText). Words with similar meanings have similar vector representations.
- Recurrent Neural Networks (RNNs): Neural networks designed to process sequential data, such as text. Variants like LSTMs and GRUs address the vanishing gradient problem in long sequences.
- Transformer Models: Deep learning architectures that use self-attention mechanisms to process input sequences in parallel. Models like BERT and GPT are built on Transformers and have achieved remarkable performance in NLP tasks.
- Attention Mechanisms: Allow models to focus on relevant parts of the input sequence when generating output, improving performance in tasks like machine translation.
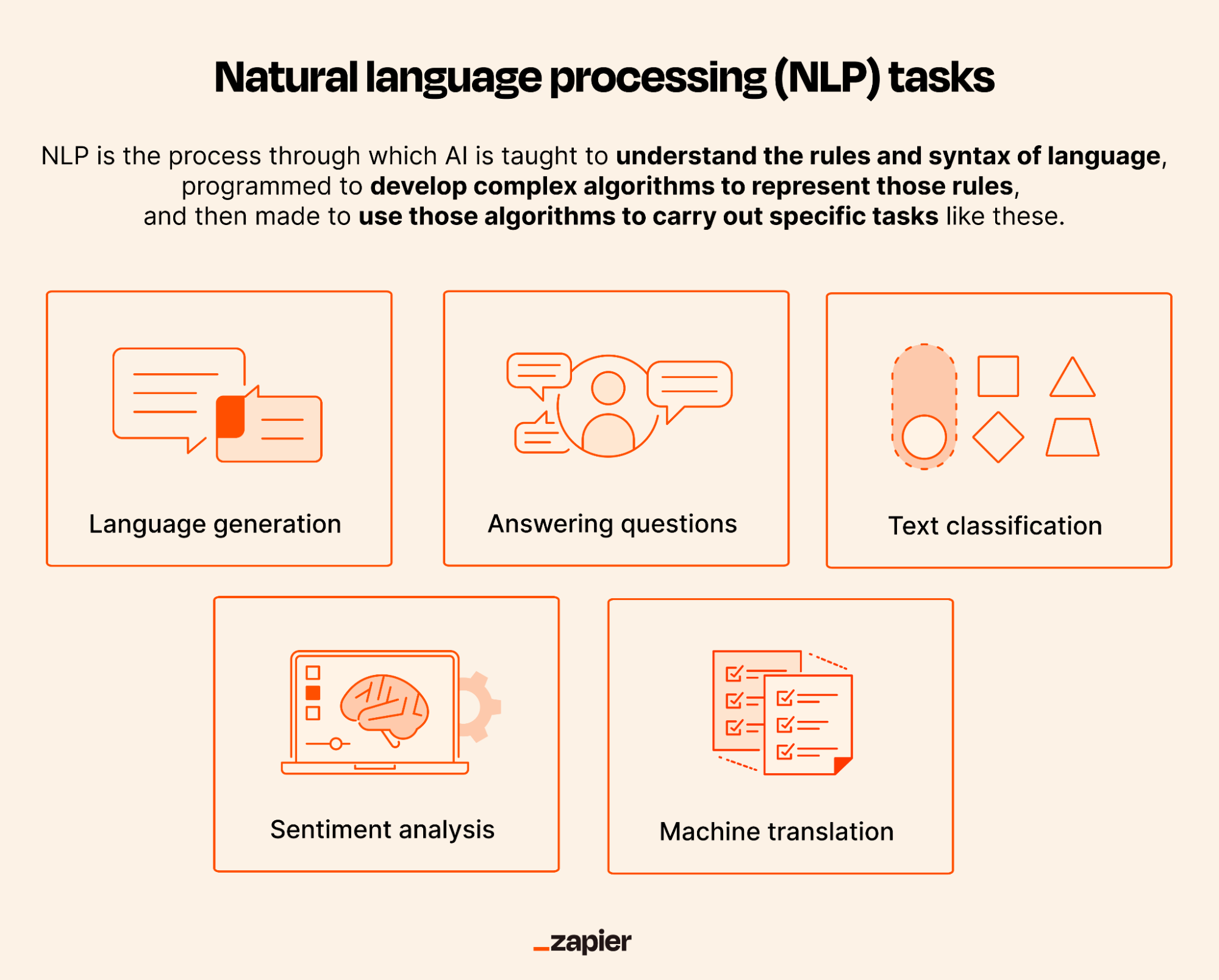
#Applications of NLP
- Machine Translation: Automatically translating text from one language to another (e.g., Google Translate, DeepL).
- Sentiment Analysis: Determining the emotional tone of a text (e.g., positive, negative, neutral) for applications in customer feedback and social media monitoring.
- Named Entity Recognition (NER): Identifying and classifying named entities (e.g., people, organizations, locations) in text.
- Text Summarization: Generating concise summaries of long documents (e.g., news articles, research papers).
- Chatbots and Virtual Assistants: Enabling human-like conversations through natural language understanding and generation (e.g., Siri, Alexa).
- Speech Recognition: Converting spoken language into written text (e.g., voice-to-text applications).
- Question Answering: Providing precise answers to user queries based on large text corpora (e.g., IBM Watson, Google Search).
#Important Facts
- NLP is a Multidisciplinary Field: It combines elements of linguistics, computer science, statistics, and artificial intelligence.
- Data Dependency: NLP models require large amounts of high-quality, labeled data for training. The quality and diversity of data significantly impact model performance.
- Bias in NLP: Language models can inherit biases present in training data, leading to unfair or discriminatory outcomes (e.g., gender or racial biases in sentiment analysis).
- Multilingual NLP: While English dominates NLP research, there is growing focus on developing models for low-resource languages to ensure linguistic diversity and inclusivity.
- Ethical Considerations: Issues such as privacy, misinformation, and the misuse of NLP (e.g., deepfake text, automated propaganda) are critical concerns in the field.
- Energy Consumption: Training large language models (e.g., GPT-3) requires significant computational resources, raising environmental and cost-related challenges.
- Explainability: Many advanced NLP models (e.g., deep neural networks) operate as "black boxes," making it difficult to interpret their decisions. Research in explainable AI (XAI) aims to address this issue.
#Timeline
- Foundational ideas
Core concepts and early methods shape The Rise of Natural Language Processing: a Historical Perspective.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does The Rise of Natural Language Processing: a Historical Perspective cover?
Traces the rise of natural language processing: a historical perspective, highlighting major milestones, context, examples, and future implications.
Why is The Rise of Natural Language Processing: a Historical Perspective important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Rise, Natural, Language before using the ideas in real projects.
#References
- The Rise of Natural Language Processing: a Historical Perspective terminology and background research
- The Rise of Natural Language Processing: a Historical Perspective use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Rise case studies, benchmarks, and current industry analysis
Comments
No comments yet. Start the discussion with a useful note.