#Short Answer
Explains how does natural language processing work?, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
Natural Language Processing (NLP) is a multidisciplinary field that combines computer science, artificial intelligence, and linguistics to enable machines to process and analyze human language. Unlike traditional programming, which relies on structured data, NLP deals with unstructured or semi-structured text and speech, making it one of the most challenging areas in AI. The primary goal of NLP is to allow computers to understand context, semantics, and intent behind human language, rather than just recognizing patterns. This capability is essential for applications such as virtual assistants (e.g., Siri, Alexa), automated customer service, and real-time translation services. NLP systems can perform tasks like text classification, named entity recognition, part-of-speech tagging, and language generation, all of which require a deep understanding of linguistic structures. Modern NLP relies heavily on machine learning and deep learning models, particularly neural networks like Transformers, which have revolutionized the field by achieving state-of-the-art performance in tasks such as language translation and sentiment analysis. The integration of NLP into everyday technology has made it a cornerstone of the digital transformation era.
#History / Background
#Early Foundations (1950s–1960s)
The origins of NLP can be traced back to the 1950s, when researchers began exploring the possibility of machines understanding human language. One of the earliest milestones was the Turing Test (1950), proposed by Alan Turing, which evaluated a machine's ability to exhibit intelligent behavior indistinguishable from that of a human. This laid the groundwork for AI-driven language processing. In 1954, IBM and Georgetown University demonstrated the first machine translation system, which translated Russian sentences into English. This event marked the beginning of computational linguistics. During this period, rule-based systems dominated NLP, relying on predefined grammatical rules and dictionaries to parse and generate language.
#The AI Winter and Rule-Based Systems (1970s–1980s)
The 1970s and 1980s saw a decline in AI research funding, known as the AI Winter, which slowed progress in NLP. However, rule-based systems continued to evolve, with projects like SHRDLU (1970) demonstrating how computers could understand and manipulate language in constrained environments. Linguists such as Noam Chomsky contributed significantly to NLP by developing formal grammars and syntactic theories, which became foundational for rule-based approaches. Despite their limitations, these systems were crucial for early applications in text processing and information retrieval.
#The Rise of Statistical NLP (1990s–2000s)
The 1990s brought a paradigm shift with the introduction of statistical NLP, which used probabilistic models to analyze language. This approach relied on large datasets to infer patterns rather than rigid rules. Key advancements included:
- Hidden Markov Models (HMMs) for speech recognition.
- n-gram models for text prediction and language modeling.
- Support Vector Machines (SVMs) for text classification. During this era, the Penn Treebank (1993) became a benchmark dataset for syntactic parsing, enabling researchers to train and evaluate models more effectively. The rise of the internet also provided vast amounts of text data, fueling the development of more sophisticated NLP techniques.
#The Deep Learning Revolution (2010s–Present)
The 2010s marked a turning point for NLP with the advent of deep learning, particularly neural networks. Key breakthroughs included:
- Word embeddings (e.g., Word2Vec, GloVe) that represented words as dense vectors, capturing semantic relationships.
- Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks for sequence modeling.
- Attention mechanisms and Transformers (e.g., BERT, GPT), which revolutionized language understanding by enabling models to focus on relevant parts of input text. The introduction of BERT (Bidirectional Encoder Representations from Transformers) by Google in 2018 set new benchmarks for NLP tasks, demonstrating the power of pre-trained language models. Today, NLP is deeply integrated into technologies like search engines, virtual assistants, and automated content generation.
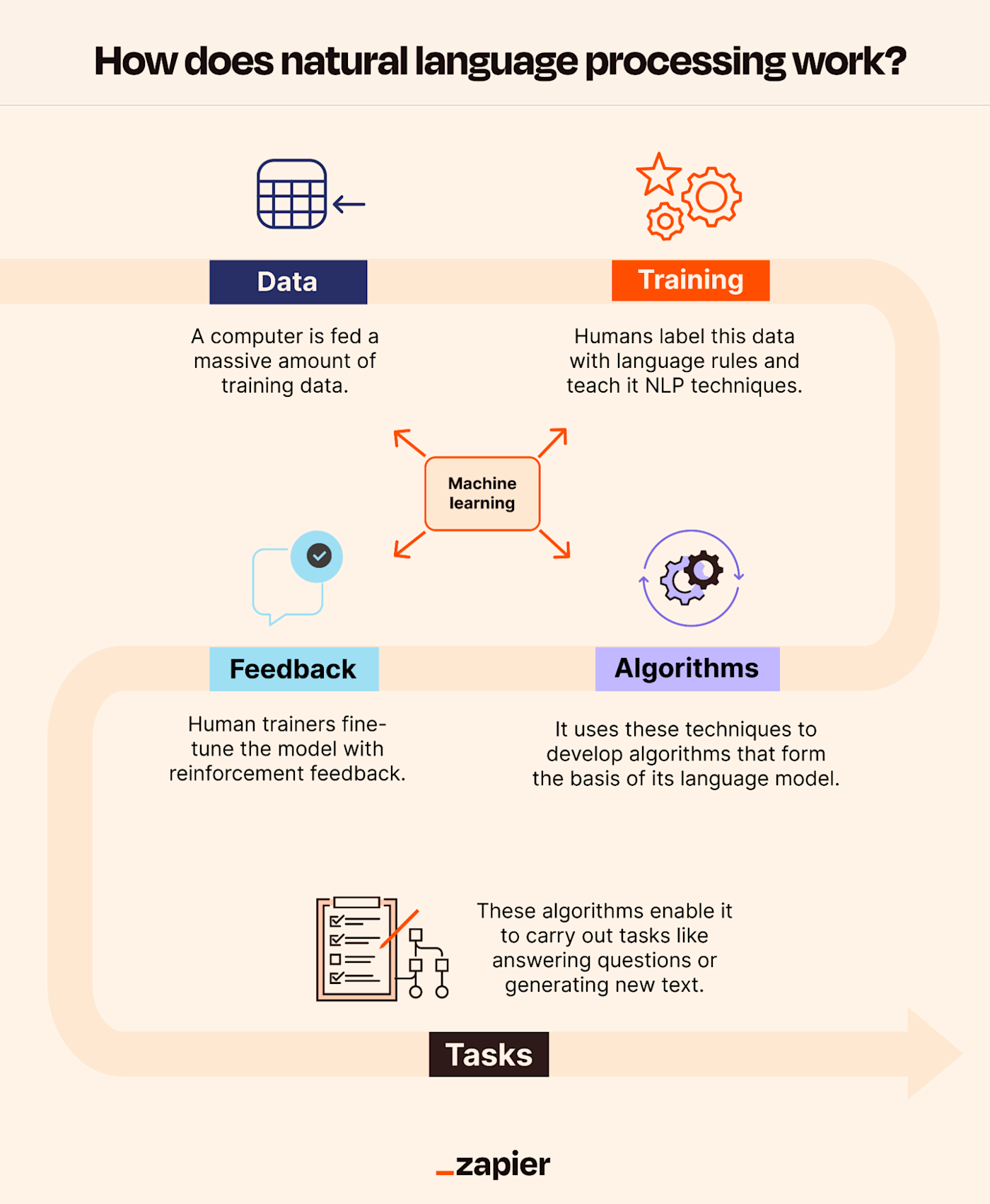
#How It Works
Natural Language Processing operates through a series of interconnected steps, from raw text input to meaningful output. The process can be broadly divided into text preprocessing, feature extraction, and model training/inference.
#1. Text Preprocessing Before any analysis, raw text must be cleaned and standardized to improve model performance. Common preprocessing steps include:
- Tokenization: Splitting text into individual words, phrases, or sentences (e.g., "Hello world" → ["Hello", "world"]).
- Normalization: Converting text to a consistent format (e.g., lowercase conversion, removing punctuation).
- Stopword Removal: Eliminating common words (e.g., "the", "is") that add little semantic value.
- Stemming/Lemmatization: Reducing words to their base forms (e.g., "running" → "run").
- Part-of-Speech (POS) Tagging: Labeling words with their grammatical roles (e.g., noun, verb).
- Named Entity Recognition (NER): Identifying entities like people, places, and organizations in text.
#2. Feature Extraction Once preprocessed, text data must be converted into numerical representations that machine learning models can process. Techniques include:
- Bag-of-Words (BoW): Represents text as a frequency vector of words, ignoring grammar and word order.
- TF-IDF (Term Frequency-Inverse Document Frequency): Weighs words based on their importance in a document relative to a corpus.
- Word Embeddings: Dense vector representations where semantically similar words are closer in vector space (e.g., Word2Vec, GloVe, FastText).
- Contextual Embeddings: Advanced embeddings like those from BERT or RoBERTa, which capture contextual meaning (e.g., "bank" as a financial institution vs. riverbank).
#3. Model Training and Inference NLP models are trained on large datasets to learn patterns and relationships in language. The choice of model depends on the task:
- Rule-Based Models: Use predefined linguistic rules (e.g., for simple chatbots).
- Machine Learning Models: Include Naive Bayes, SVM, and Random Forests for tasks like text classification.
- Deep Learning Models:
- Recurrent Neural Networks (RNNs): Suitable for sequence tasks like language modeling.
- Convolutional Neural Networks (CNNs): Effective for text classification and sentiment analysis.
- Transformers: State-of-the-art models like BERT, GPT, and T5, which use self-attention mechanisms to understand context.
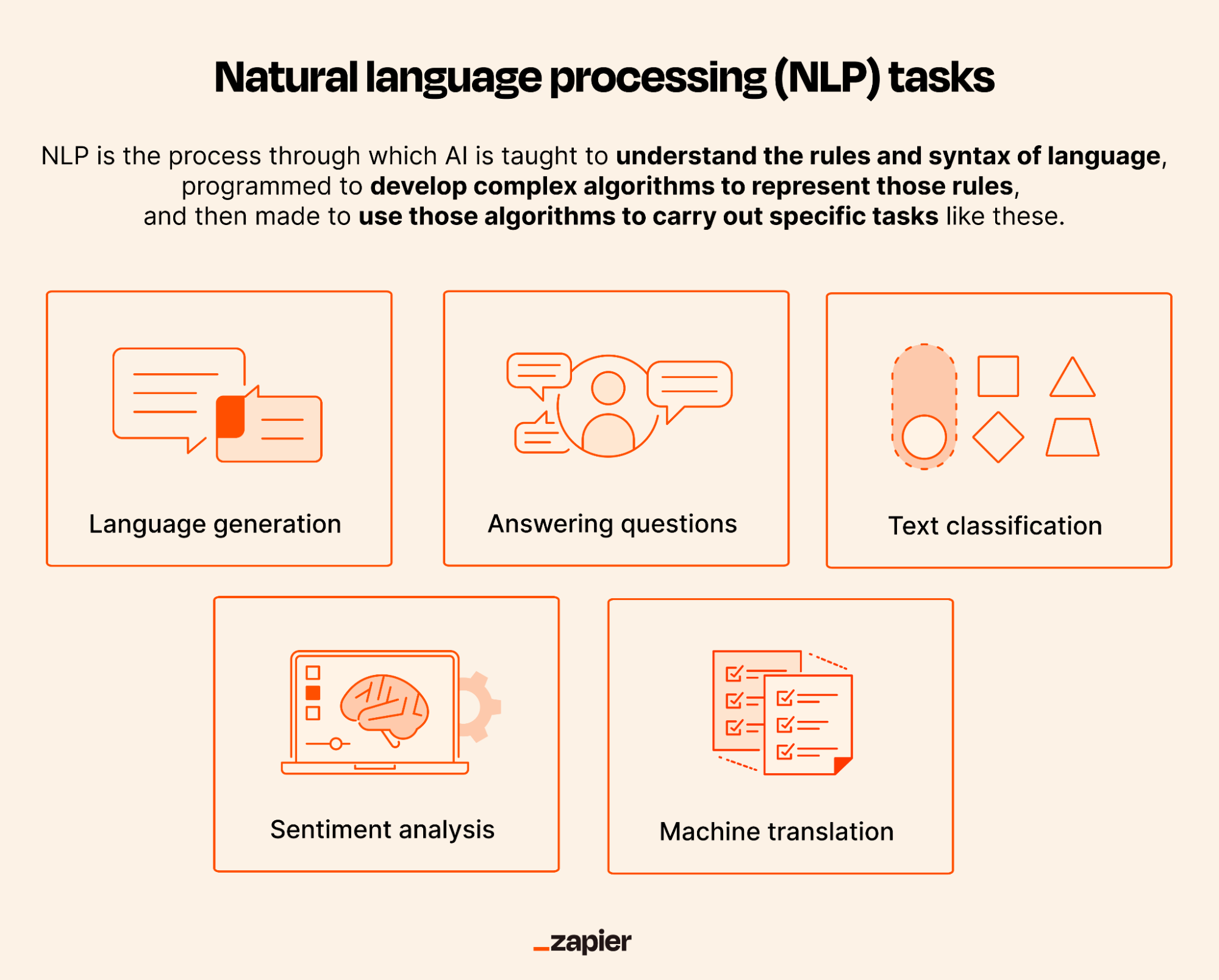
Key NLP Tasks:
- Text Classification: Categorizing text into predefined classes (e.g., spam detection).
- Machine Translation: Translating text between languages (e.g., Google Translate).
- Sentiment Analysis: Determining the emotional tone of text (e.g., positive, negative, neutral).
- Named Entity Recognition (NER): Identifying entities in text (e.g., "Apple Inc." as an organization).
- Question Answering: Providing answers to questions based on a given context (e.g., IBM Watson).
- Text Generation: Creating human-like text (e.g., chatbots, content generation).
#4. Post-Processing and Output After model inference, the output may require further processing to ensure coherence and usability. For example:
- Response Generation: Formatting a chatbot's reply into natural language.
- Error Correction: Fixing grammatical or factual errors in generated text.
- Human-in-the-Loop: Incorporating human feedback to refine model outputs.
#Important Facts
- NLP is not perfect: Despite advancements, NLP systems still struggle with ambiguity, sarcasm, and cultural nuances in language.
- Data dependency: NLP models require vast amounts of high-quality data for training. Biases in training data can lead to biased outputs.
- Multilingual NLP: While English dominates NLP research, efforts are ongoing to improve language support for low-resource languages.
- Ethical concerns: NLP applications like deepfake text and biased algorithms raise ethical questions about privacy and fairness.
- Real-time processing: Modern NLP systems, such as those powering voice assistants, must process language in real-time with minimal latency.
- Explainability: Many NLP models, especially deep learning-based ones, operate as "black boxes," making it difficult to interpret their decisions.
- Energy consumption: Training large language models (e.g., GPT-3) requires significant computational resources, contributing to environmental concerns.
#Timeline
- Foundational ideas
Core concepts and early methods shape How Does Natural Language Processing Work?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How Does Natural Language Processing Work? cover?
Explains how does natural language processing work?, including the main process, tools, examples, risks, and practical implementation steps.
Why is How Does Natural Language Processing Work? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Does, Natural, Language before using the ideas in real projects.
#References
- How Does Natural Language Processing Work? terminology and background research
- How Does Natural Language Processing Work? use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Does case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.