#Short Answer
Covers natural language processing: everything you need to know, including core concepts, practical examples, benefits, limitations, and risks in Language AI.
#Infobox
#Overview
Natural Language Processing (NLP) is a transformative technology that allows computers to process and analyze large volumes of human language data. By leveraging algorithms, statistical models, and deep learning techniques, NLP systems can perform tasks such as text classification, named entity recognition, and language generation. The primary goal of NLP is to enable machines to understand human language in a way that is both accurate and nuanced, facilitating seamless communication between humans and computers. NLP is divided into two main categories:
- Natural Language Understanding (NLU) – Focuses on interpreting the meaning of text or speech, including intent detection and entity extraction.
- Natural Language Generation (NLG) – Involves generating human-like text from structured data, such as summarizing reports or composing emails. The field has seen exponential growth due to advancements in machine learning, particularly with the advent of transformer models like BERT and GPT, which have significantly improved the accuracy and efficiency of NLP systems.
#History / Background
The origins of NLP can be traced back to the 1950s, when researchers began exploring the possibility of machines understanding human language. One of the earliest milestones was the Georgetown-IBM experiment in 1954, where a computer successfully translated 60 Russian sentences into English. This event marked the beginning of machine translation research, though early systems relied heavily on rule-based approaches and had limited success. In the 1960s and 1970s, NLP research shifted toward symbolic AI, where linguists and computer scientists developed formal grammars and rule-based systems to parse and generate language. Projects like SHRDLU, an early natural language understanding program, demonstrated that computers could follow simple commands in a constrained environment. The 1980s and 1990s saw the rise of statistical NLP, which introduced probabilistic models to improve language processing. Techniques such as Hidden Markov Models (HMMs) and n-gram models became foundational for tasks like speech recognition and part-of-speech tagging. The introduction of the Penn Treebank in the 1990s provided annotated corpora that enabled large-scale training of statistical models. The 2000s brought about a paradigm shift with the adoption of machine learning in NLP. Algorithms like Support Vector Machines (SVMs) and Conditional Random Fields (CRFs) were used for tasks such as named entity recognition and sentiment analysis. However, the most transformative development occurred in the 2010s with the introduction of deep learning and neural networks. Key breakthroughs included:
- Word2Vec (2013) – A technique for generating word embeddings that capture semantic relationships.
- Sequence-to-Sequence Models (2014) – Enabled machine translation by using encoder-decoder architectures.
- Attention Mechanisms (2015) – Improved the ability of models to focus on relevant parts of input data.
- Transformers (2017) – Introduced in the paper "Attention Is All You Need", transformers revolutionized NLP by enabling parallel processing of sequences and capturing long-range dependencies. The release of BERT (Bidirectional Encoder Representations from Transformers) by Google in 2018 further advanced the field by introducing pre-trained language models that could be fine-tuned for various downstream tasks. This was followed by models like GPT (Generative Pre-trained Transformer) and T5 (Text-to-Text Transfer Transformer), which expanded the capabilities of NLP systems to include text generation, question answering, and more.
#How It Works
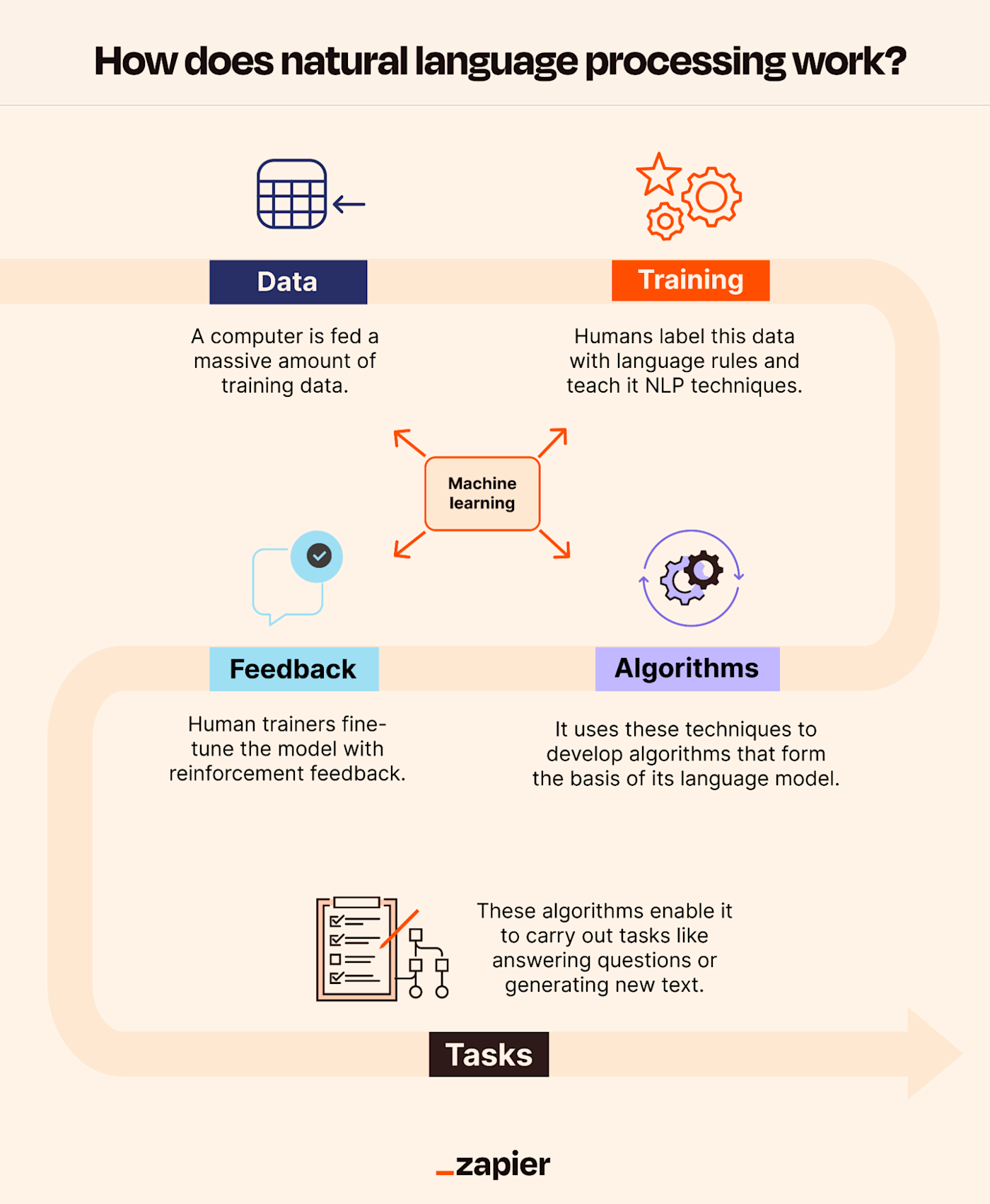
Natural Language Processing operates through a combination of computational techniques and linguistic principles. The process typically involves several stages:
#
- Text Preprocessing Before analysis, raw text data must be cleaned and standardized. Common preprocessing steps include:
- Tokenization – Splitting text into individual words, phrases, or sentences.
- Normalization – Converting text to lowercase, removing punctuation, and expanding contractions (e.g., "don't" to "do not").
- Stop Word Removal – Filtering out common words (e.g., "the," "is") that may not contribute to meaning.
- Stemming/Lemmatization – Reducing words to their base or root form (e.g., "running" to "run").
- Part-of-Speech (POS) Tagging – Assigning grammatical labels (e.g., noun, verb) to each word.
#
- Feature Extraction Traditional NLP systems relied on handcrafted features such as:
- Bag-of-Words (BoW) – Representing text as a frequency distribution of words.
- TF-IDF (Term Frequency-Inverse Document Frequency) – Weighting words based on their importance in a document relative to a corpus.
- Word Embeddings – Dense vector representations of words that capture semantic relationships (e.g., Word2Vec, GloVe, FastText). Modern NLP systems, however, leverage deep learning models that automatically learn features from raw text. Techniques like:
- Convolutional Neural Networks (CNNs) – Effective for capturing local patterns in text.
- Recurrent Neural Networks (RNNs) – Suitable for sequential data but limited by vanishing gradients.
- Long Short-Term Memory (LSTM) Networks – A type of RNN that mitigates the vanishing gradient problem.
- Transformers – Utilize self-attention mechanisms to process entire sequences in parallel, enabling superior performance in tasks like machine translation and text generation.
#
- Model Training NLP models are trained on large datasets using supervised, unsupervised, or semi-supervised learning:
- Supervised Learning – Requires labeled data (e.g., sentiment analysis with labeled reviews).
- Unsupervised Learning – Uses unlabeled data to discover patterns (e.g., topic modeling with Latent Dirichlet Allocation).
- Semi-Supervised Learning – Combines small labeled datasets with large unlabeled datasets for improved performance.
- Transfer Learning – Pre-trained models (e.g., BERT, RoBERTa) are fine-tuned on specific tasks, reducing the need for extensive labeled data.
#
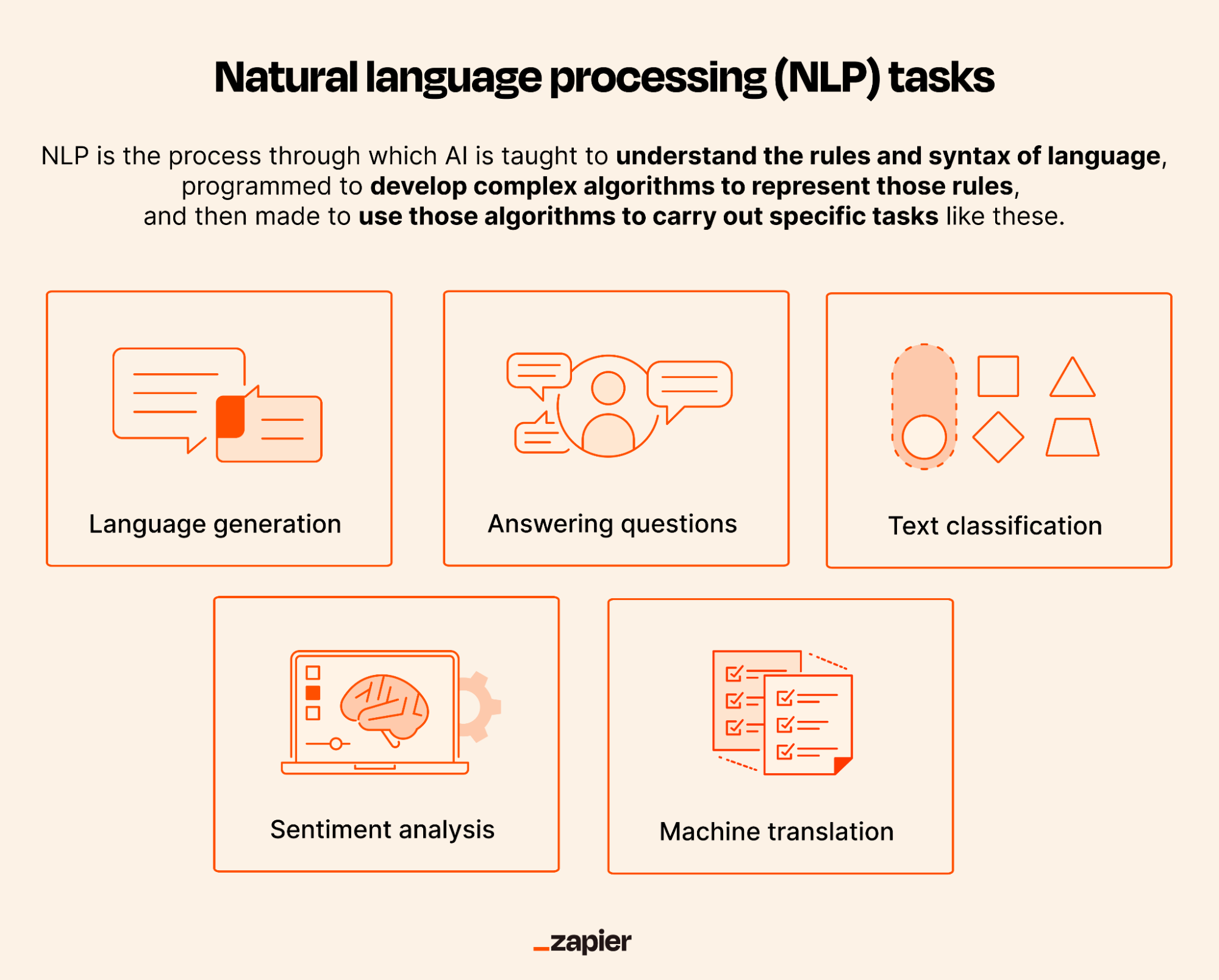
- Task-Specific Applications Once trained, NLP models can perform various tasks:
- Text Classification – Categorizing text into predefined classes (e.g., spam detection, sentiment analysis).
- Named Entity Recognition (NER) – Identifying and classifying entities (e.g., people, organizations, locations) in text.
- Machine Translation – Converting text from one language to another (e.g., Google Translate).
- Question Answering – Providing answers to questions based on a given context (e.g., IBM Watson).
- Text Summarization – Generating concise summaries of longer documents.
- Speech Recognition – Converting spoken language into text (e.g., Siri, Alexa).
- Chatbots & Virtual Assistants – Simulating human-like conversations (e.g., customer service bots).
#
- Post-Processing & Evaluation After generating outputs, NLP systems may apply post-processing techniques to improve readability or correctness. Evaluation metrics vary by task:
- Accuracy, Precision, Recall, F1-Score – For classification tasks.
- BLEU, ROUGE – For machine translation and summarization.
- Perplexity – For language modeling tasks.
#Important Facts
- NLP is Everywhere: From search engines (Google) to virtual assistants (Siri, Alexa), NLP is integrated into daily digital interactions.
- Multilingual Support: Modern NLP systems can process over 100 languages, though performance varies based on language complexity and available training data.
- Bias in NLP: Models can inherit biases from training data, leading to skewed results in applications like hiring tools or facial recognition.
- Computational Power: Training large NLP models (e.g., GPT-3) requires significant computational resources, often necessitating GPUs or TPUs.
- Ethical Concerns: Issues like deepfake text, misinformation spread via NLP, and privacy violations in voice data collection are growing concerns.
- Human-in-the-Loop: Many NLP systems require human oversight to correct errors, especially in high-stakes applications like healthcare or legal document analysis.
- Open-Source Advancements: Tools like Hugging Face’s Transformers library and spaCy have democratized NLP, enabling researchers and developers to build and deploy models without extensive expertise.
#Timeline
- Foundational ideas
Core concepts and early methods shape Natural Language Processing: Everything You Need to Know.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Natural Language Processing: Everything You Need to Know cover?
Covers natural language processing: everything you need to know, including core concepts, practical examples, benefits, limitations, and risks in Language AI.
Why is Natural Language Processing: Everything You Need to Know important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Natural, Language, Processing before using the ideas in real projects.
#References
- Natural Language Processing: Everything You Need to Know terminology and background research
- Natural Language Processing: Everything You Need to Know use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Natural case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.