
#Short Answer
Covers machine learning for dummies: a beginner’s overview, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
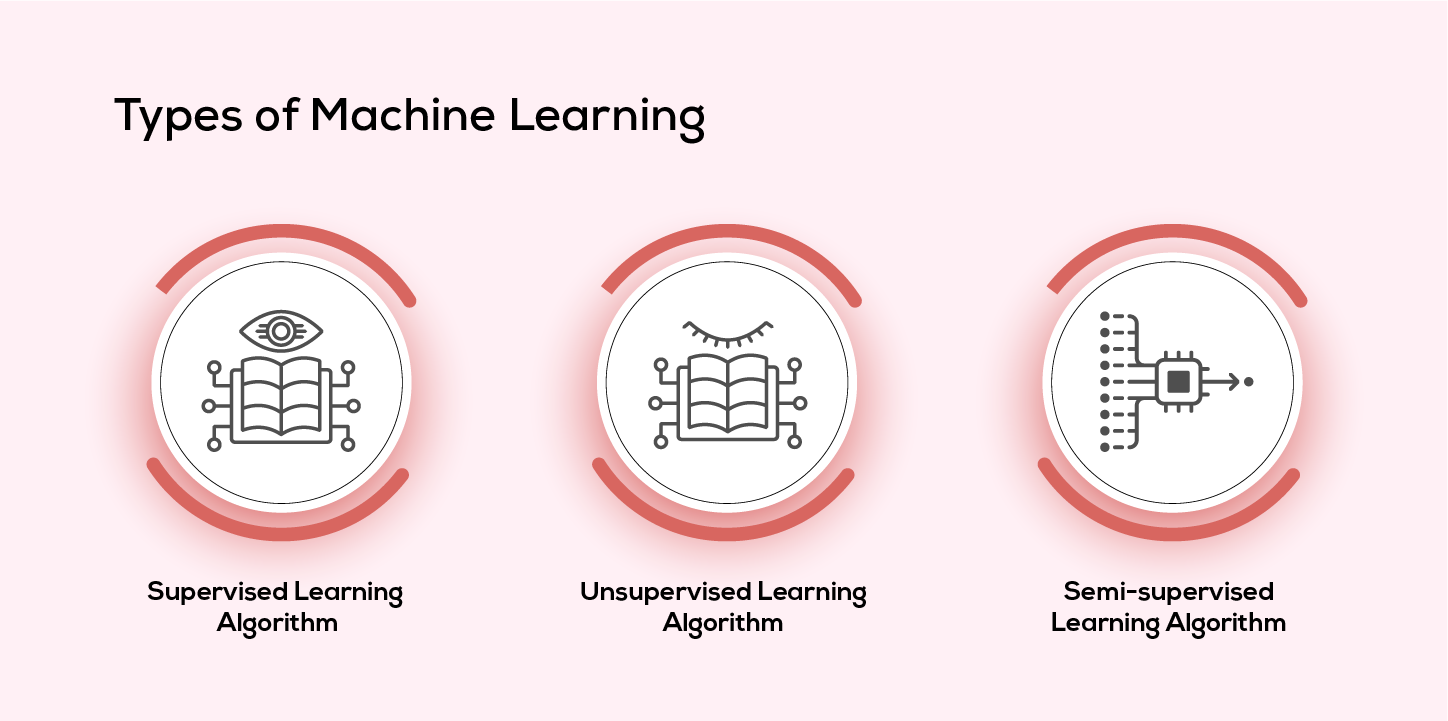
Machine learning (ML) is a transformative technology that allows computers to learn from experience. Unlike traditional programming, where rules are explicitly defined, ML systems derive patterns from data, enabling them to generalize and make decisions in new situations. This capability has revolutionized industries by automating complex tasks, enhancing accuracy, and uncovering insights from vast datasets. At its core, ML relies on data as the primary fuel. The quality, quantity, and relevance of data directly impact the performance of ML models. These models are trained using algorithms that adjust their internal parameters to minimize errors, a process known as training. Once trained, the model can make predictions or classifications on unseen data, a phase called inference. ML is broadly categorized into three types:
- Supervised Learning: Uses labeled data (input-output pairs) to train models for tasks like classification and regression.
- Unsupervised Learning: Identifies patterns in unlabeled data, such as clustering or dimensionality reduction.
- Reinforcement Learning: Trains models through trial-and-error interactions with an environment, optimizing for rewards (e.g., robotics, gaming).
#History / Background
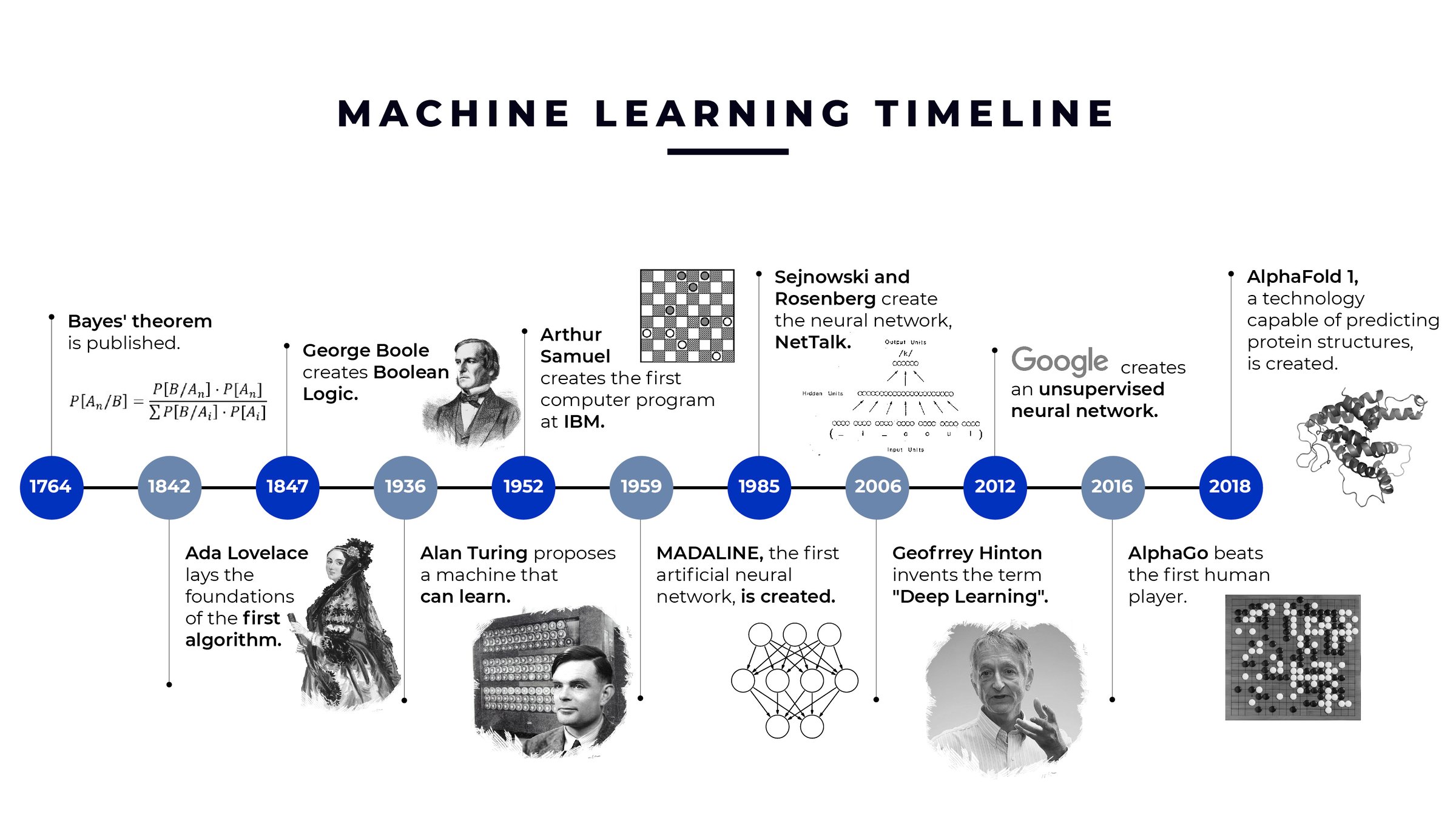
The roots of machine learning trace back to the mid-20th century, intertwined with advancements in statistics, computer science, and neuroscience.
- 1943: Warren McCulloch and Walter Pitts proposed the first mathematical model of a neural network, inspired by biological neurons.
- 1950: Alan Turing introduced the concept of machine learning in his paper "Computing Machinery and Intelligence," posing the question: "Can machines think?"
- 1952: Arthur Samuel developed the first self-learning program, a checkers-playing AI that improved with experience.
- 1958: Frank Rosenblatt invented the Perceptron, an early neural network model capable of binary classification.
- 1967: The Nearest Neighbor algorithm was introduced, laying groundwork for pattern recognition.
- 1980s: The rise of backpropagation (Rumelhart, Hinton, Williams) enabled training of multi-layer neural networks, reviving interest in deep learning.
- 1997: IBM’s Deep Blue defeated world chess champion Garry Kasparov, showcasing AI’s potential in complex decision-making.
- 2011: Google’s AlphaGo (later AlphaGo Zero) demonstrated superhuman performance in the board game Go, leveraging deep reinforcement learning.
- 2010s–Present: The explosion of big data, cloud computing, and GPUs accelerated ML adoption, leading to breakthroughs in computer vision (e.g., AlexNet, 2012) and natural language processing (e.g., BERT, 2018). The field has evolved from rule-based systems to data-driven models, with modern ML now underpinning technologies like virtual assistants, autonomous vehicles, and personalized medicine.
#How It Works
Machine learning operates through a structured pipeline involving data preparation, model selection, training, evaluation, and deployment. Below is a step-by-step breakdown:
#
- Data Collection and Preprocessing
- Data Sources: Structured (databases, spreadsheets) or unstructured (text, images, audio).
- Cleaning: Handling missing values, removing duplicates, and correcting inconsistencies.
- Feature Engineering: Selecting relevant variables (features) and transforming them (e.g., normalization, encoding categorical data).
- Splitting Data: Dividing datasets into training (70–80%), validation (10–15%), and test (10–15%) sets to evaluate model performance.
#
- Model Selection
- Algorithm Choice: Depends on the problem type:
- Classification: Logistic regression, Support Vector Machines (SVM), Random Forests.
- Regression: Linear regression, Ridge/Lasso regression.
- Clustering: K-Means, DBSCAN.
- Deep Learning: Convolutional Neural Networks (CNNs) for images, Recurrent Neural Networks (RNNs) for sequences.
- Hyperparameter Tuning: Adjusting parameters (e.g., learning rate, tree depth) to optimize performance, often using techniques like grid search or random search.
#
- Training - The model learns from the training data by adjusting its internal parameters to minimize a loss function (e.g., mean squared error for regression, cross-entropy for classification).
- Optimization Algorithms: Gradient descent variants (e.g., Adam, SGD) update parameters iteratively.
- Overfitting vs. Underfitting:
- Overfitting: Model memorizes training data but fails on new data (high variance).
- Underfitting: Model is too simple to capture patterns (high bias).
- Solutions: Regularization (L1/L2), dropout (in neural networks), early stopping.
#
- Evaluation
- Metrics:
- Classification: Accuracy, Precision, Recall, F1-score, ROC-AUC.
- Regression: Mean Absolute Error (MAE), Root Mean Squared Error (RMSE).
- Clustering: Silhouette score, Davies-Bouldin index.
- Cross-Validation: Techniques like k-fold cross-validation ensure robustness by testing the model on multiple data subsets.
#
- Deployment and Monitoring
- Deployment: Integrating the model into applications via APIs (e.g., Flask, FastAPI) or embedded systems.
- Monitoring: Tracking performance drift, data drift, and retraining models periodically to maintain accuracy.
#Important Facts
- Bias-Variance Tradeoff: A fundamental challenge where reducing bias (underfitting) may increase variance (overfitting), and vice versa.
- Curse of Dimensionality: As the number of features grows, the data becomes sparse, making it harder to train accurate models.
- Explainability: Many ML models (e.g., deep neural networks) are "black boxes," leading to research in explainable AI (XAI) to interpret decisions.
- Ethical Concerns: Bias in training data can lead to discriminatory outcomes (e.g., facial recognition inaccuracies for certain demographics).
- Hardware Acceleration: GPUs and TPUs (Tensor Processing Units) significantly speed up training, especially for deep learning.
- AutoML: Tools like Google AutoML and H2O.ai automate model selection, hyperparameter tuning, and deployment, democratizing ML for non-experts.
#Timeline
- Foundational ideas
Core concepts and early methods shape Machine Learning for Dummies: a Beginner’s Overview.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Machine Learning for Dummies: a Beginner’s Overview cover?
Covers machine learning for dummies: a beginner’s overview, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Machine Learning for Dummies: a Beginner’s Overview important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Machine, Learning, Beginner before using the ideas in real projects.
#References
- Machine Learning for Dummies: a Beginner’s Overview terminology and background research
- Machine Learning for Dummies: a Beginner’s Overview use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Machine case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.