#Short Answer
Covers machine learning explained: a simple guide, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Machine learning is a transformative technology that bridges the gap between raw data and actionable insights. At its core, ML involves training models on datasets to recognize patterns, classify information, or predict outcomes without explicit programming for each task. This adaptability makes it a cornerstone of modern AI systems, enabling applications across industries such as healthcare, finance, retail, and entertainment. The field operates on the principle that computers can autonomously improve their performance by analyzing data. For instance, a spam filter learns to distinguish between legitimate emails and junk by processing thousands of labeled examples. Similarly, a self-driving car uses ML to interpret sensor data and navigate complex environments. The versatility of ML stems from its ability to handle diverse data types, including text, images, and numerical records, through specialized algorithms.
#History / Background
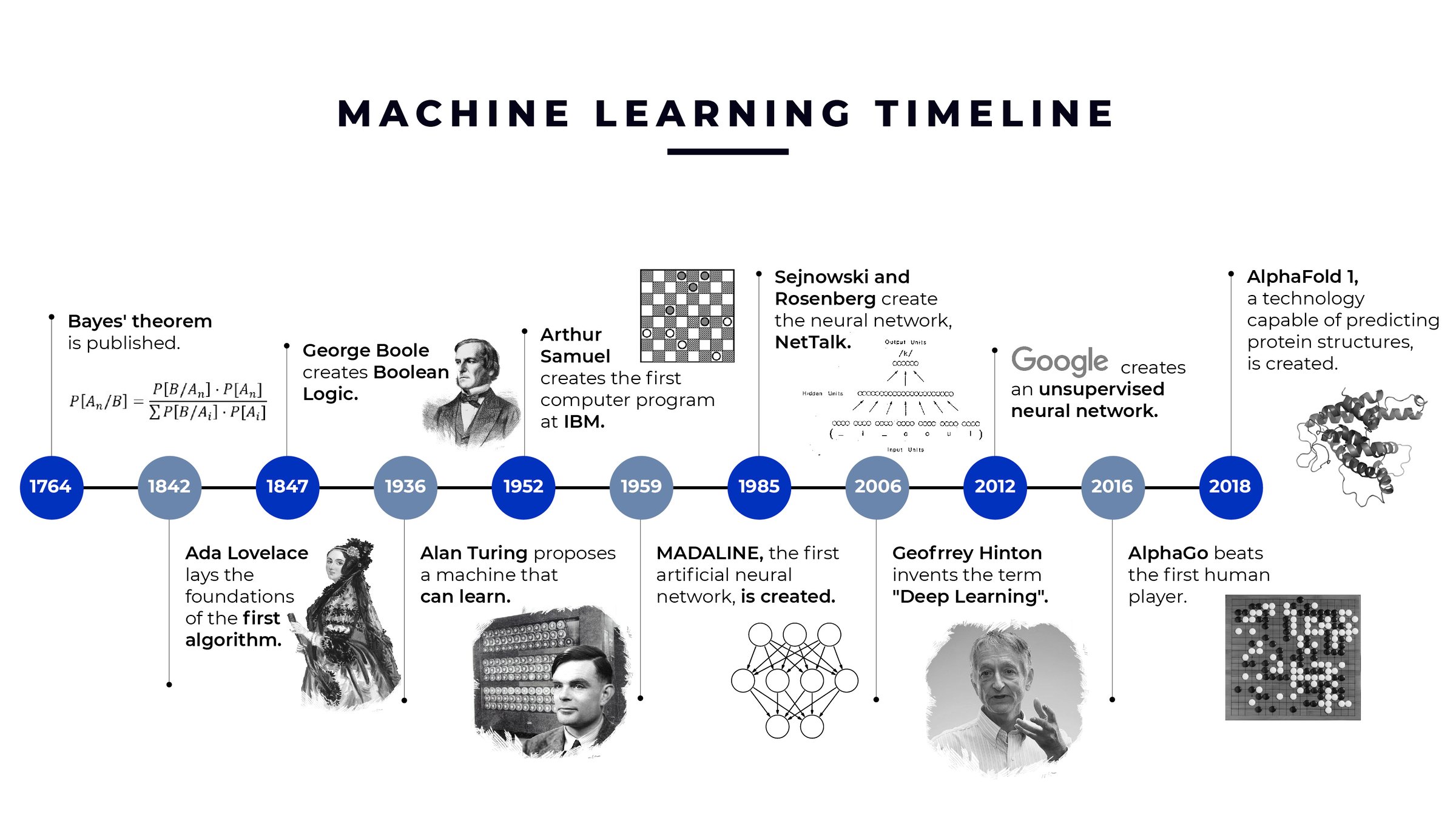
#Early Foundations (1940s–1950s)
The conceptual roots of machine learning trace back to the mid-20th century, with early work in cybernetics and neural networks. In 1943, Warren McCulloch and Walter Pitts proposed a mathematical model of artificial neurons, laying the groundwork for neural networks. By 1950, Alan Turing introduced the concept of machines that could learn, famously posing the question, "Can machines think?" in his seminal paper "Computing Machinery and Intelligence."
#The Birth of AI and ML (1956–1970s)
The term "artificial intelligence" was coined in 1956 during the Dartmouth Conference, where researchers like John McCarthy and Marvin Minsky envisioned machines capable of human-like reasoning. The 1950s and 1960s saw the development of early ML algorithms, such as the perceptron (Frank Rosenblatt, 1958), a simple neural network for binary classification. However, limitations in computing power and data availability constrained progress.
#The AI Winter and Revival (1970s–1990s)
The 1970s and 1980s marked the first "AI winter," a period of reduced funding and interest due to unmet expectations. Research shifted toward symbolic AI, which relied on rule-based systems rather than learning from data. The revival of ML began in the late 1980s with the introduction of backpropagation (David Rumelhart et al., 1986), enabling deeper neural networks to train effectively. Support Vector Machines (SVMs) and decision trees also emerged as powerful tools.
#The Deep Learning Revolution (2000s–Present)
The 2000s witnessed a paradigm shift with the rise of deep learning, driven by advances in computational power (GPUs) and the availability of big data. Key milestones include:
- 2012: AlexNet, a deep convolutional neural network, achieved breakthrough performance in image recognition.
- 2016: AlphaGo defeated a world champion Go player, demonstrating the potential of reinforcement learning.
- 2020s: Large language models (LLMs) like GPT-3 and diffusion models for image generation have pushed the boundaries of generative AI. Today, ML is ubiquitous, powering everything from virtual assistants to drug discovery, and continues to evolve with innovations like federated learning and explainable AI.
#How It Works
#Core Principles Machine learning operates on three fundamental components:
- Data: The fuel for training models. High-quality, representative data is essential for accurate predictions.
- Model: A mathematical representation of the learning process, such as a neural network or decision tree.
- Algorithm: The method used to optimize the model, such as gradient descent or genetic algorithms.
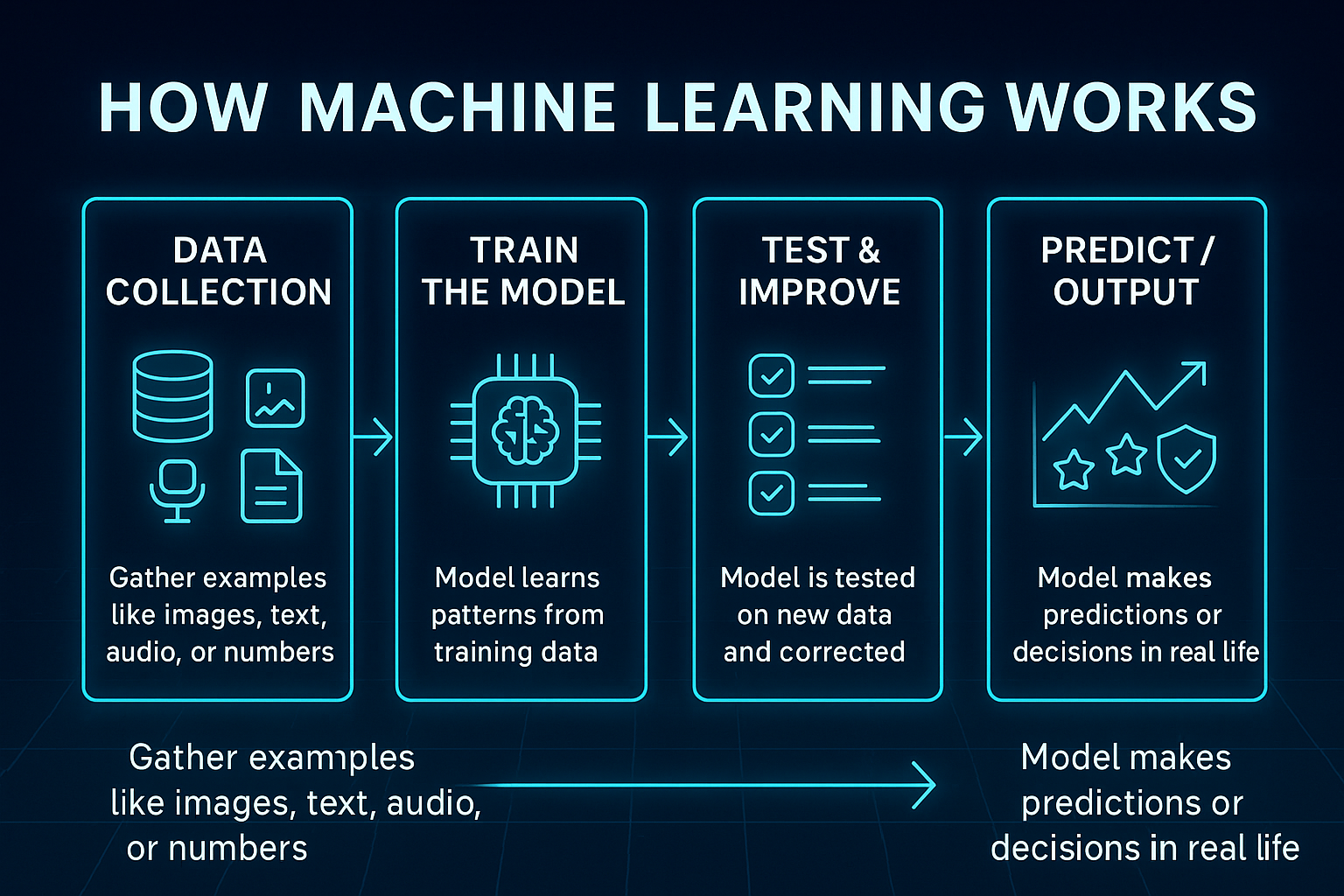
#The Learning Process ML models undergo a training phase where they adjust their internal parameters to minimize errors. This process typically involves:
- Data Collection: Gathering relevant datasets (e.g., images, text, or numerical records).
- Data Preprocessing: Cleaning, normalizing, and transforming data to improve model performance.
- Feature Extraction: Identifying key attributes (features) that influence the output (e.g., pixel values in images or word frequencies in text).
- Model Selection: Choosing an appropriate algorithm based on the problem type (e.g., classification, regression, clustering).
- Training: Feeding the model with labeled data (supervised learning) or unlabeled data (unsupervised learning) to learn patterns.
- Evaluation: Assessing the model’s performance using metrics like accuracy, precision, or F1-score.
- Deployment: Integrating the trained model into real-world applications (e.g., recommendation systems or chatbots).
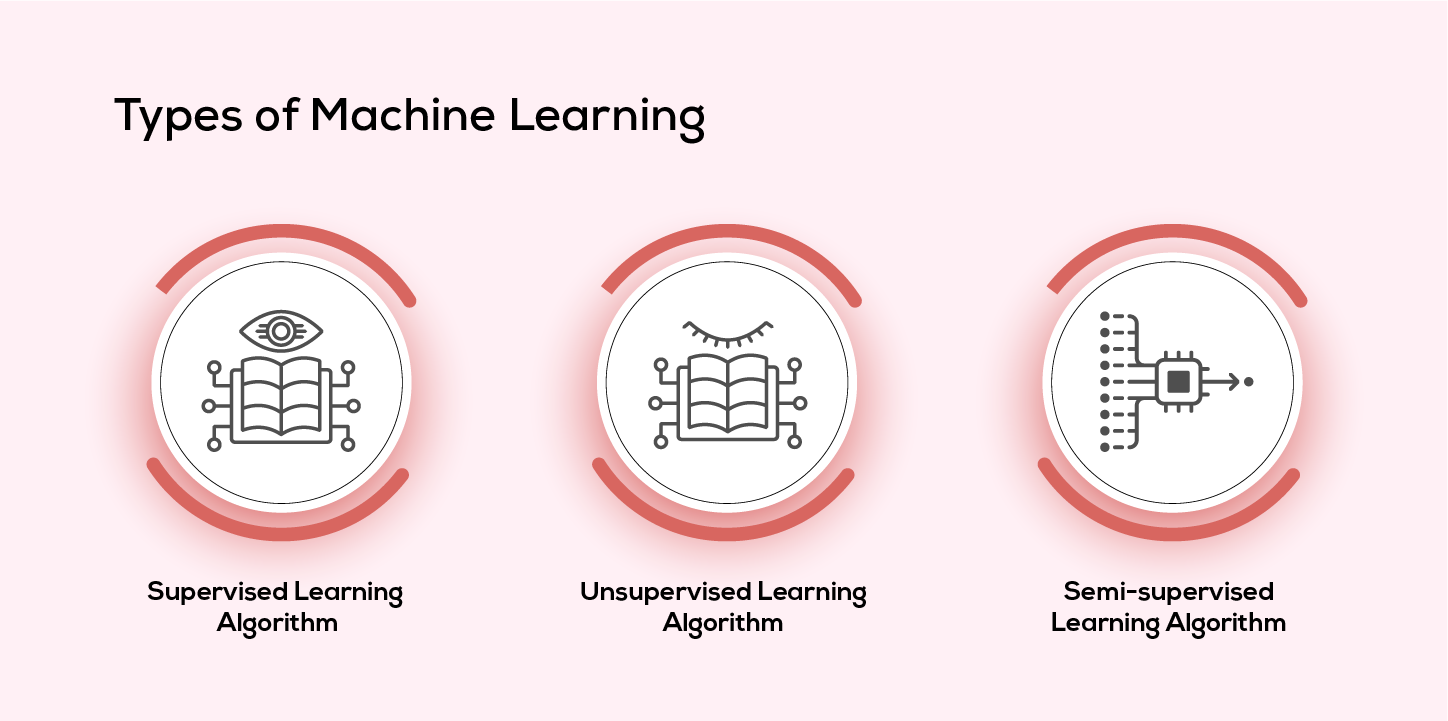
#Types of Machine Learning
- Supervised Learning: The model is trained on labeled data, where input-output pairs are provided. Examples include:
- Classification: Predicting discrete labels (e.g., spam vs. not spam).
- Regression: Predicting continuous values (e.g., house prices).
- Unsupervised Learning: The model identifies patterns in unlabeled data. Examples include:
- Clustering: Grouping similar data points (e.g., customer segmentation).
- Dimensionality Reduction: Simplifying data (e.g., PCA for visualization).
- Reinforcement Learning: The model learns by interacting with an environment and receiving rewards or penalties. Examples include:
- Robotics: Teaching a robot to walk.
- Game AI: Training agents to play chess or video games.
#Key Algorithms
- Linear Regression: Predicts continuous outcomes.
- Logistic Regression: Classifies binary outcomes.
- Decision Trees: Splits data based on feature thresholds.
- Neural Networks: Mimics the human brain with interconnected layers.
- k-Nearest Neighbors (k-NN): Classifies data based on proximity to training examples.
- Support Vector Machines (SVM): Finds optimal hyperplanes to separate classes.
#Important Facts
- Data Quality Matters: Garbage in, garbage out (GIGO). Poor-quality data leads to inaccurate models.
- Overfitting vs. Underfitting: - Overfitting: The model memorizes training data but fails to generalize. - Underfitting: The model is too simple to capture patterns.
- Bias-Variance Tradeoff: Balancing bias (error due to overly simplistic assumptions) and variance (error due to excessive complexity).
- Transfer Learning: Leveraging pre-trained models (e.g., BERT for NLP) to reduce training time and data requirements.
- Explainability: Techniques like SHAP (SHapley Additive exPlanations) help interpret model decisions.
- Ethical Concerns: Bias in training data can lead to discriminatory outcomes (e.g., facial recognition inaccuracies for certain demographics).
#Timeline
- Foundational ideas
Core concepts and early methods shape Machine Learning Explained: a Simple Guide.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Machine Learning Explained: a Simple Guide cover?
Covers machine learning explained: a simple guide, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Machine Learning Explained: a Simple Guide important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Machine, Learning, Explained before using the ideas in real projects.
#References
- Machine Learning Explained: a Simple Guide terminology and background research
- Machine Learning Explained: a Simple Guide use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Machine case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.