
#Short Answer
Explains how to get started with neural networks, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
Neural networks are computational models inspired by the structure and function of biological neural networks in the brain. They consist of interconnected nodes (neurons) organized into layers that process input data to produce an output. These networks excel at recognizing patterns, making predictions, and solving complex problems in fields such as computer vision, natural language processing, and robotics. The advent of deep learning—a subset of machine learning utilizing neural networks with multiple hidden layers—has revolutionized artificial intelligence by enabling breakthroughs in tasks like image classification, speech recognition, and autonomous driving. Frameworks such as Keras and TensorFlow have democratized access to neural network development, allowing practitioners to build and deploy models with minimal low-level coding.
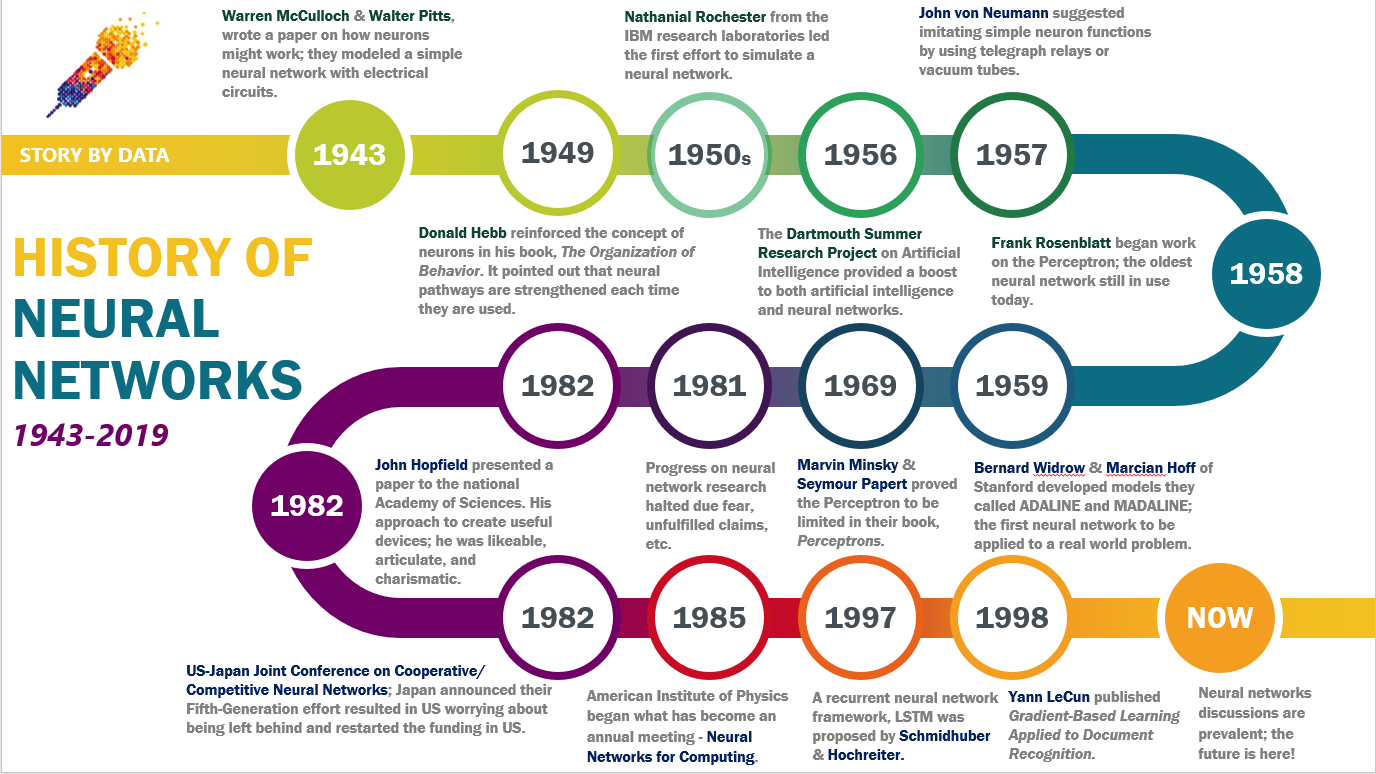
#History / Background
#Early Foundations (1940s–1960s)
The concept of neural networks traces back to the 1943 work of Warren McCulloch and Walter Pitts, who proposed a mathematical model of artificial neurons. In 1958, Frank Rosenblatt developed the Perceptron, the first algorithm capable of learning from data. However, limitations in computational power and theoretical understanding led to the first "AI winter" in the 1970s.
#Revival and Backpropagation (1980s–1990s)
Geoffrey Hinton and others revived interest in neural networks by introducing backpropagation, a method for training multi-layer networks. Despite progress, practical applications remained constrained by hardware limitations and the complexity of training deep networks.
#Deep Learning Revolution (2000s–Present)
The breakthrough came in 2012 when Alex Krizhevsky’s AlexNet won the ImageNet competition, demonstrating the power of deep convolutional neural networks (CNNs). This event catalyzed widespread adoption of deep learning. Concurrently, frameworks like TensorFlow (2015) and Keras (2015) simplified model development, making neural networks accessible to a broader audience.
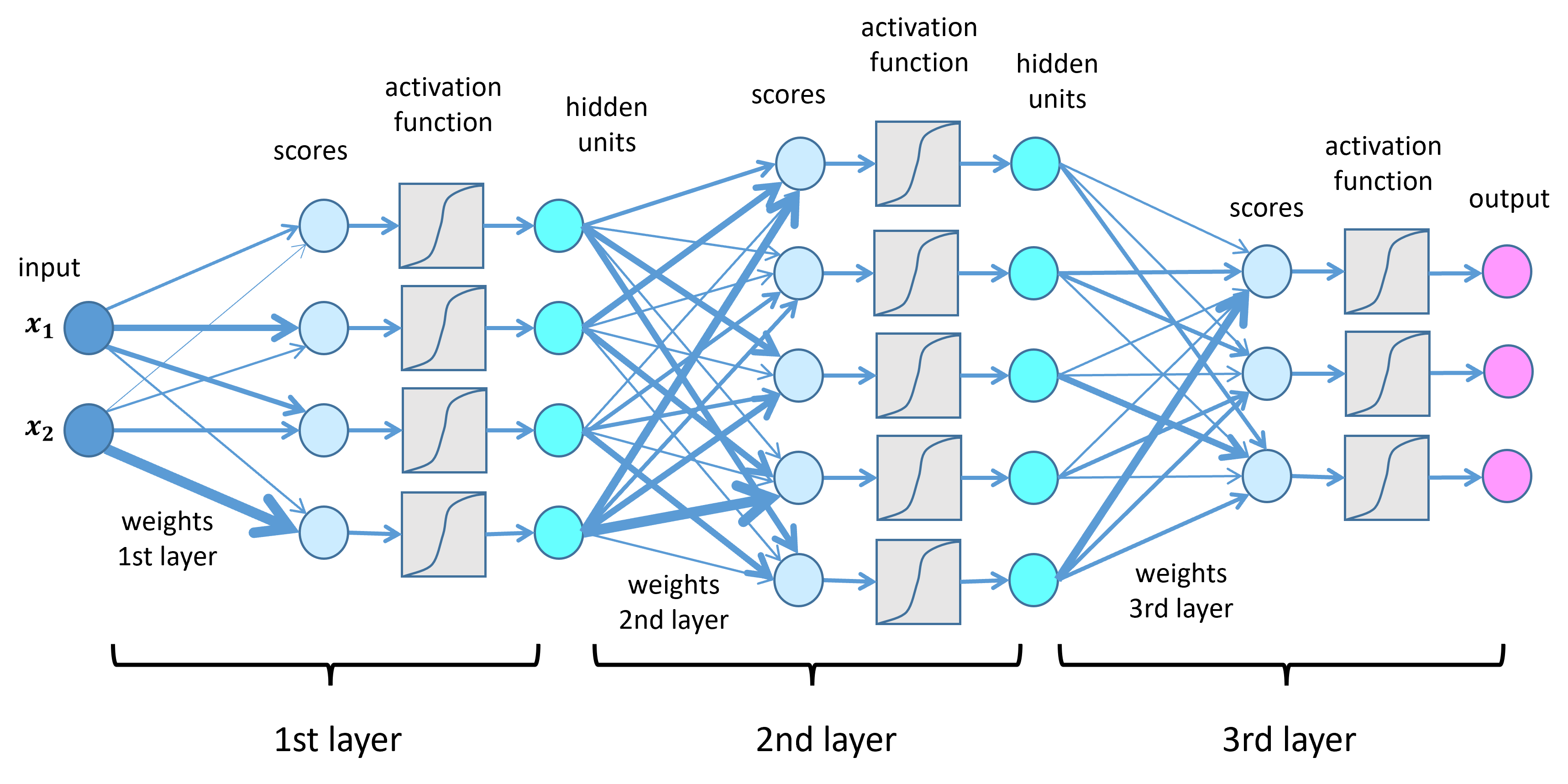
#How It Works
#Basic Structure A neural network comprises three primary types of layers:
- Input Layer: Receives the initial data (e.g., pixel values of an image).
- Hidden Layers: Perform computations using weights and activation functions (e.g., ReLU, Sigmoid).
- Output Layer: Produces the final prediction (e.g., class probabilities).
#Key Components
- Neurons: Basic units that apply a weighted sum of inputs followed by an activation function.
- Weights and Biases: Parameters adjusted during training to minimize prediction errors.
- Activation Functions: Introduce non-linearity (e.g., ReLU, Tanh), enabling the network to learn complex patterns.
- Loss Function: Measures the difference between predicted and actual outputs (e.g., Mean Squared Error, Cross-Entropy).
- Optimizer: Adjusts weights to reduce loss (e.g., Stochastic Gradient Descent, Adam).
#Training Process
- Forward Propagation: Input data passes through the network to generate predictions.
- Loss Calculation: The loss function quantifies prediction errors.
- Backpropagation: Gradients of the loss are computed with respect to each weight, and the optimizer updates the weights to minimize loss.
- Iteration: The process repeats over multiple epochs until the model converges to an acceptable performance level.
#Example: Image Classification A CNN processes an input image by: - Applying convolutional filters to extract features (edges, textures). - Pooling layers reduce spatial dimensions. - Fully connected layers combine features for classification.
#Important Facts
- Universal Approximation Theorem: A neural network with a single hidden layer can approximate any continuous function, given sufficient neurons.
- Overfitting: Occurs when a model memorizes training data but fails to generalize to unseen data. Techniques like dropout and regularization mitigate this.
- Transfer Learning: Leverages pre-trained models (e.g., ResNet, BERT) to adapt to new tasks, reducing training time and data requirements.
- Hardware Acceleration: Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) significantly speed up training.
- Ethical Considerations: Bias in training data can lead to discriminatory outcomes, necessitating careful dataset curation and model evaluation.
#Timeline
- Foundational ideas
Core concepts and early methods shape How to Get Started with Neural Networks.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How to Get Started with Neural Networks cover?
Explains how to get started with neural networks, including the main process, tools, examples, risks, and practical implementation steps.
Why is How to Get Started with Neural Networks important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Get, Started, Neural before using the ideas in real projects.
#References
- How to Get Started with Neural Networks terminology and background research
- How to Get Started with Neural Networks use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Get case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.