#Short Answer
Traces timeline of neural networks, highlighting major milestones, context, examples, and future implications.
#Infobox
#Overview
Neural networks are a subset of machine learning algorithms designed to recognize patterns in data by mimicking the interconnected structure of neurons in the brain. They consist of layers of artificial neurons (nodes) that process input data, learn from it through training, and produce outputs such as classifications or predictions. The field has undergone significant transformations, from early linear models to complex deep learning architectures capable of handling vast datasets and solving intricate problems. Neural networks excel in tasks requiring pattern recognition, such as image and speech recognition, natural language processing, and decision-making in autonomous systems. Their adaptability stems from their ability to adjust weights between neurons during training, optimizing performance through iterative feedback. This adaptability has led to breakthroughs in fields like computer vision, healthcare diagnostics, and financial forecasting.
#History / Background
#Early Foundations (Pre-1950s)
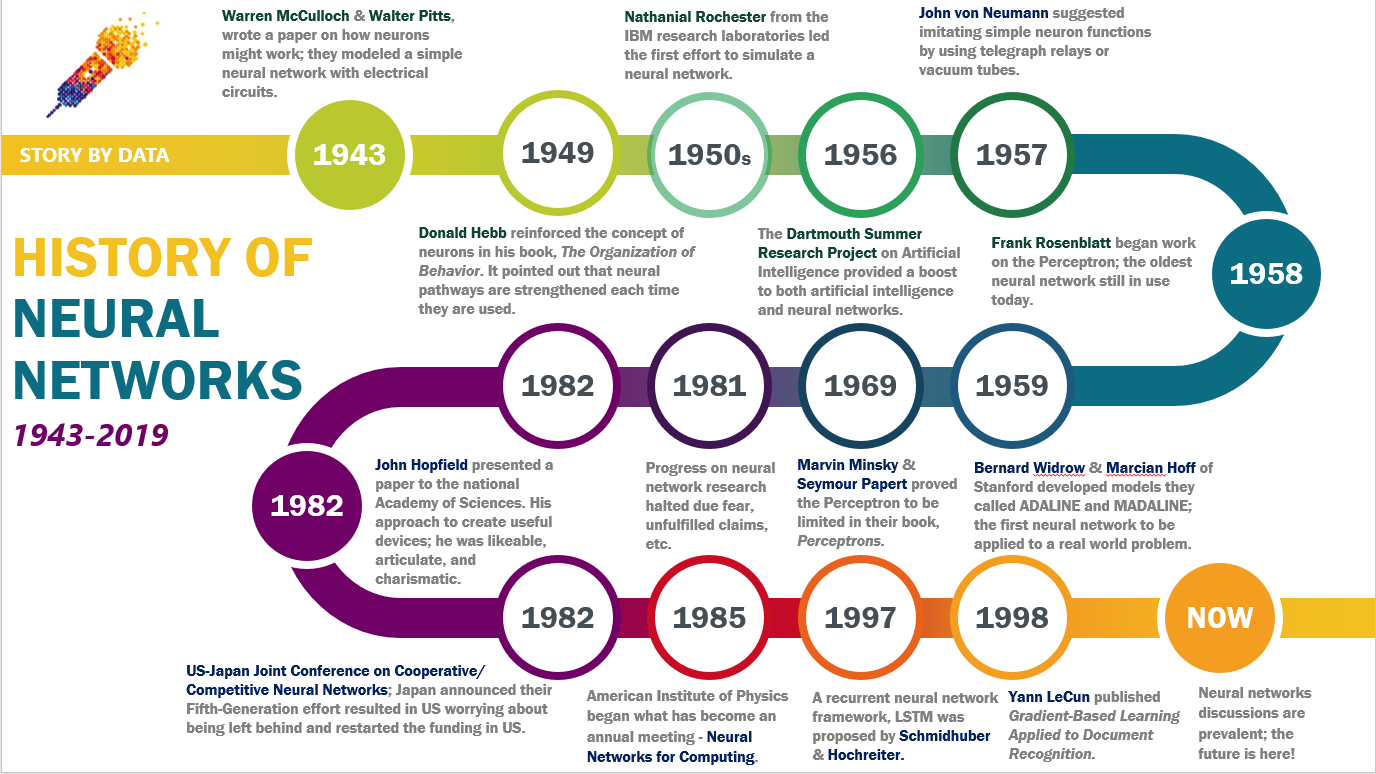
The conceptual roots of neural networks trace back to the 1940s, when researchers sought to model the brain's computational processes. In 1943, neurophysiologist Warren McCulloch and mathematician Walter Pitts published a seminal paper introducing the McCulloch-Pitts neuron, a simplified model of biological neurons. This model demonstrated that networks of such neurons could perform logical operations, laying the groundwork for artificial intelligence. During this period, the field was largely theoretical, with limited computational resources to test these ideas. However, the work inspired further exploration into how machines could emulate cognitive functions.
#The Perceptron Era (1950s–1960s)
The 1950s marked a pivotal shift with the invention of the perceptron by Frank Rosenblatt in 1958. The perceptron was the first artificial neural network capable of learning from data, using a simple algorithm to adjust weights and improve accuracy over time. Rosenblatt's work, funded by the U.S. Office of Naval Research, demonstrated that machines could "learn" from examples, a concept that captivated both the scientific community and the public. However, the perceptron's limitations became apparent in 1969 when Marvin Minsky and Seymour Papert published Perceptrons, a book that mathematically proved the perceptron's inability to solve problems involving non-linear separability, such as the XOR problem. This critique led to a decline in neural network research, shifting focus toward symbolic AI and rule-based systems.
#Revival and Backpropagation (1980s–1990s)
The field experienced a resurgence in the 1980s, driven by advances in computing power and algorithmic innovations. In 1986, David Rumelhart, Geoffrey Hinton, and Ronald Williams popularized backpropagation, a method for training multi-layer neural networks by propagating errors backward through the network. This breakthrough enabled networks to learn complex patterns, overcoming the limitations of single-layer perceptrons. During this era, Hopfield networks (John Hopfield, 1982) and Boltzmann machines (Geoffrey Hinton, 1985) emerged as alternative architectures, offering solutions for associative memory and probabilistic modeling. However, challenges such as computational inefficiency and the lack of large datasets constrained further progress.
#The Deep Learning Revolution (2000s–Present)
The 2000s heralded the deep learning revolution, fueled by three key factors: the availability of big data, advancements in computational hardware (e.g., GPUs), and breakthroughs in algorithm design. In 2006, Geoffrey Hinton and his team demonstrated that deep belief networks could be trained efficiently using a greedy layer-wise approach, reigniting interest in neural networks. The introduction of convolutional neural networks (CNNs) by Yann LeCun in the 1990s gained renewed attention in 2012 when Alex Krizhevsky's AlexNet won the ImageNet competition, achieving unprecedented accuracy in image classification. This success spurred widespread adoption of CNNs in computer vision tasks. Subsequent innovations included recurrent neural networks (RNNs) for sequential data, long short-term memory (LSTM) networks for handling long-term dependencies, and transformers (Vaswani et al., 2017), which revolutionized natural language processing by enabling models like BERT and GPT to understand context and generate human-like text.
#How It Works
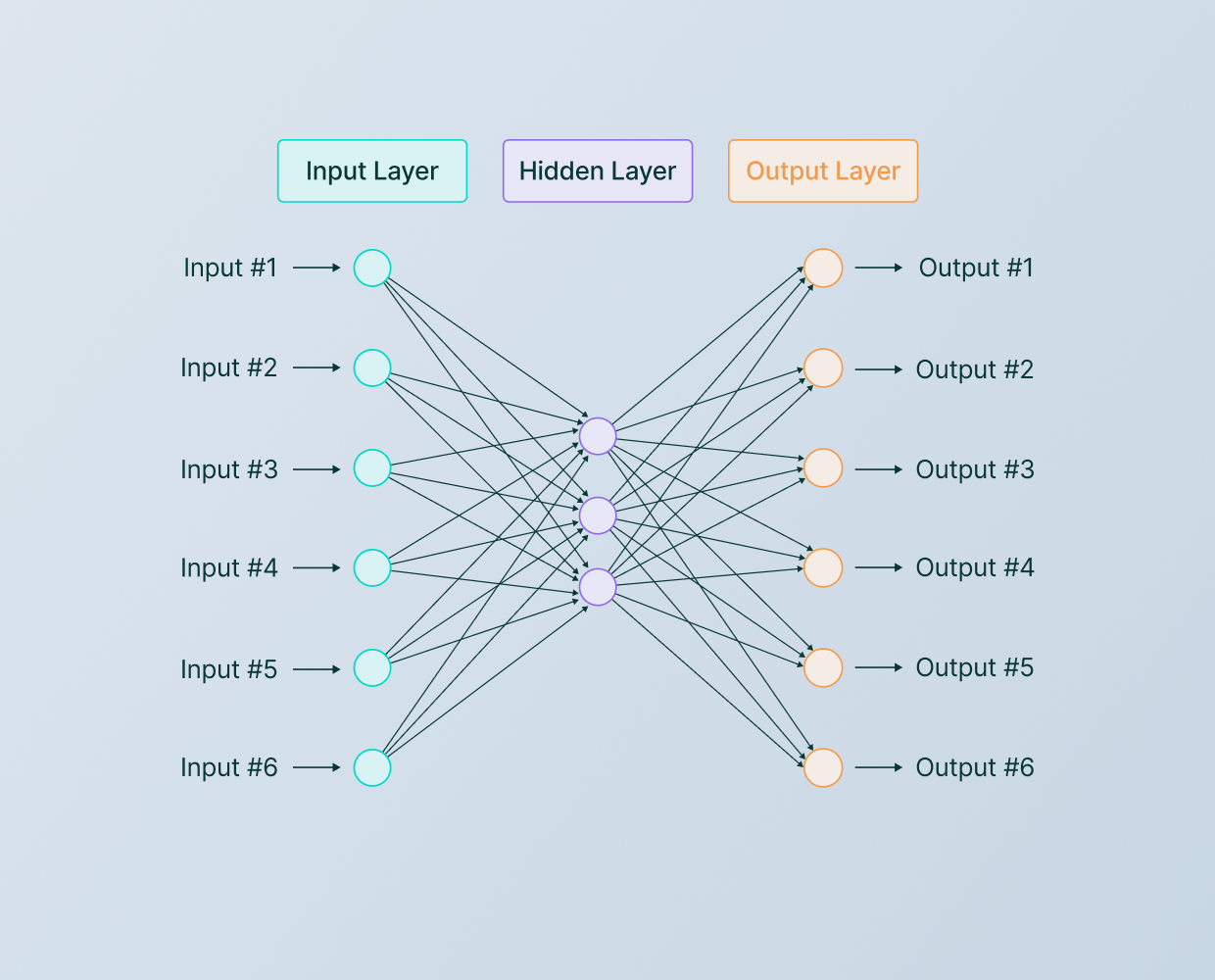
#Basic Structure A neural network consists of interconnected layers of artificial neurons (nodes), typically organized into three types:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Perform computations and transformations on the input data. The number of hidden layers determines the network's "depth."
- Output Layer: Produces the final prediction or classification (e.g., identifying an object in an image). Each neuron in a layer is connected to neurons in the next layer via weights, which determine the strength of the connection. During training, these weights are adjusted to minimize the difference between the predicted output and the actual output, a process known as learning.
#Activation Functions Neurons use activation functions to introduce non-linearity into the model, enabling it to learn complex patterns. Common activation functions include:
- Sigmoid: Outputs values between 0 and 1, useful for binary classification.
- ReLU (Rectified Linear Unit): Outputs the input directly if positive, otherwise zero; widely used in deep networks due to its computational efficiency.
- Softmax: Converts outputs into probabilities, often used in multi-class classification.
#Training Process
Neural networks learn through supervised learning, where they are fed labeled data (input-output pairs). The training process involves:
- Forward Propagation: Input data is passed through the network, generating an output.
- Loss Calculation: The difference between the predicted output and the true label is measured using a loss function (e.g., mean squared error, cross-entropy loss).
- Backpropagation: The loss is propagated backward through the network, and weights are updated using an optimizer (e.g., stochastic gradient descent, Adam) to minimize the loss.
- Iteration: The process repeats over multiple epochs until the model achieves satisfactory performance.
#Key Architectures
- Feedforward Neural Networks (FNNs): The simplest form, where data flows in one direction from input to output.
- Convolutional Neural Networks (CNNs): Specialized for grid-like data (e.g., images), using convolutional layers to detect spatial hierarchies.
- Recurrent Neural Networks (RNNs): Designed for sequential data (e.g., time series, text), with loops that allow information to persist.
- Transformers: Use self-attention mechanisms to weigh the importance of different parts of the input, enabling parallel processing and superior performance in language tasks.
#Important Facts
- First Practical Application: The perceptron was used in the 1960s for tasks like handwritten character recognition and speech synthesis.
- AI Winter: The 1970s and late 1980s saw reduced funding and interest in neural networks due to unmet expectations and computational limitations.
- ImageNet Breakthrough: AlexNet's 2012 victory reduced the error rate in image classification from 26% to 15%, demonstrating the power of deep learning.
- AlphaGo: In 2016, Google's AlphaGo defeated a world champion Go player, showcasing the potential of neural networks in complex decision-making.
- Generative AI: Models like DALL·E and Stable Diffusion use neural networks to generate realistic images from text prompts, highlighting their creative capabilities.
- Energy Efficiency: Training large neural networks requires significant computational resources, leading to research into more efficient architectures and training methods.
#Timeline
- Foundational ideas
Core concepts and early methods shape Timeline of Neural Networks.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Timeline of Neural Networks cover?
Traces timeline of neural networks, highlighting major milestones, context, examples, and future implications.
Why is Timeline of Neural Networks important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Timeline, Neural, Networks before using the ideas in real projects.
#References
- Timeline of Neural Networks terminology and background research
- Timeline of Neural Networks use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Timeline case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.