#Short Answer
Explains how do neural networks work?, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
Neural networks are a cornerstone of modern artificial intelligence (AI) and machine learning (ML), enabling systems to perform tasks that traditionally required human intelligence. Unlike traditional algorithms, which follow explicit instructions, neural networks learn from data by identifying patterns and relationships. This adaptability makes them particularly effective for problems involving unstructured data, such as images, audio, and text. At their core, neural networks are composed of interconnected nodes (neurons) organized into layers. The input layer receives raw data, which is then processed through one or more hidden layers before reaching the output layer, which produces the final prediction or classification. The strength of connections between neurons (weights) is adjusted during training to minimize errors, a process known as backpropagation. Neural networks have evolved significantly since their inception, with advancements in computing power and algorithmic innovations driving their widespread adoption across industries. Today, they power applications ranging from virtual assistants and autonomous vehicles to medical diagnostics and financial forecasting.
#History / Background
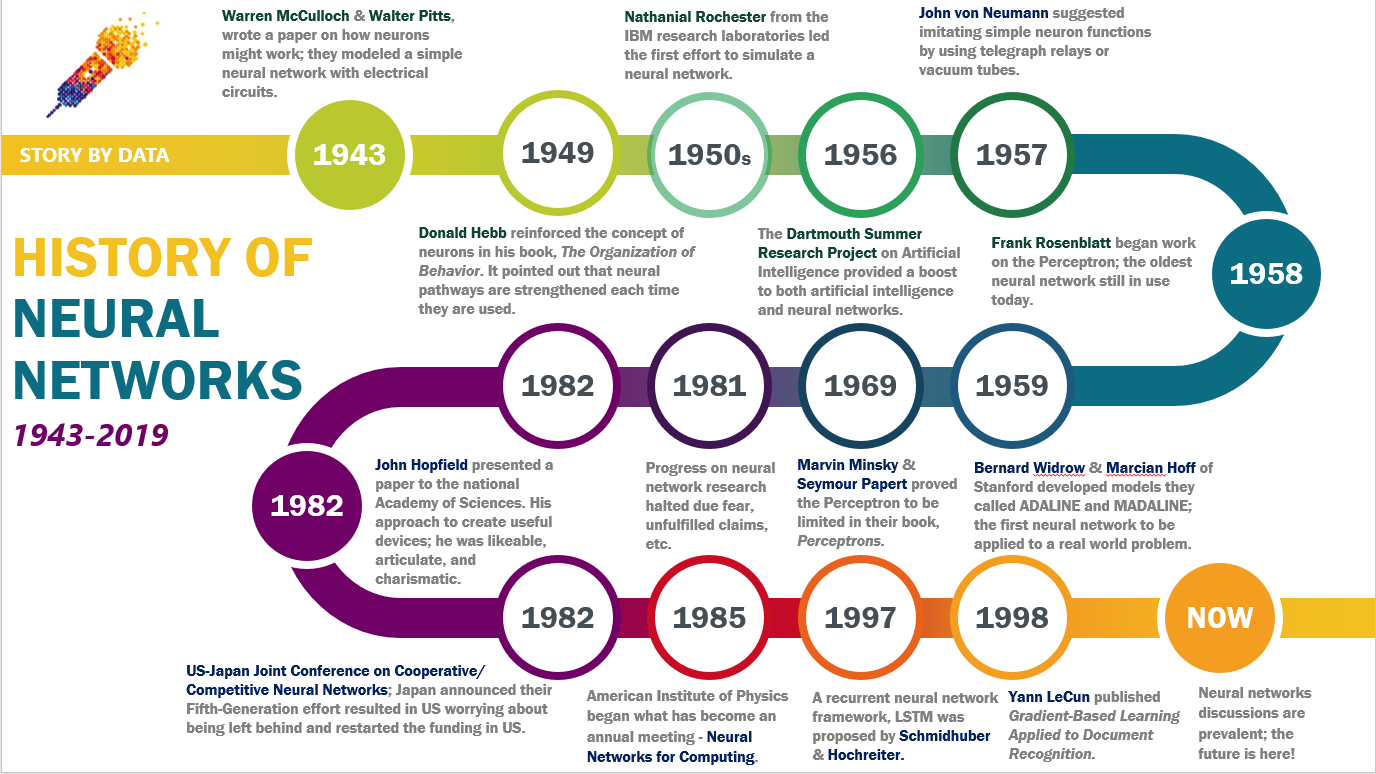
#Early Foundations (1940s–1960s)
The concept of neural networks traces back to the 1940s, with the work of Warren McCulloch and Walter Pitts, who proposed a mathematical model of artificial neurons. In 1943, they published a paper describing how neurons could perform logical operations, laying the groundwork for artificial intelligence. The term "perceptron" was later introduced by Frank Rosenblatt in 1958, who developed a single-layer neural network capable of learning from data.
#The First AI Winter (1960s–1980s)
Despite early promise, neural networks faced skepticism due to limitations in computational power and theoretical understanding. The 1969 critique by Marvin Minsky and Seymour Papert highlighted the inability of single-layer perceptrons to solve non-linear problems, leading to reduced funding and research interest—a period known as the first AI winter.
#Revival and Backpropagation (1980s–1990s)
The field experienced a resurgence in the 1980s with the introduction of backpropagation, an algorithm that efficiently trains multi-layer neural networks by propagating errors backward through the network. Geoffrey Hinton, David Rumelhart, and Ronald Williams played pivotal roles in popularizing this method. Additionally, the development of Hopfield networks and Boltzmann machines expanded the applications of neural networks to optimization and probabilistic modeling.
#Deep Learning Era (2000s–Present)
The modern era of neural networks began with the advent of deep learning, characterized by networks with many hidden layers (hence "deep"). Key milestones include:
- 2006: Geoffrey Hinton’s work on deep belief networks demonstrated that pre-training layers could overcome the vanishing gradient problem.
- 2012: The AlexNet convolutional neural network (CNN) achieved breakthrough performance in the ImageNet competition, sparking widespread interest in deep learning.
- 2014: The introduction of Generative Adversarial Networks (GANs) by Ian Goodfellow revolutionized generative modeling.
- 2017: Transformers, introduced in the paper "Attention Is All You Need", became the foundation for state-of-the-art natural language processing models like BERT and GPT. Today, neural networks underpin many of the most advanced AI systems, from self-driving cars to large language models like ChatGPT.
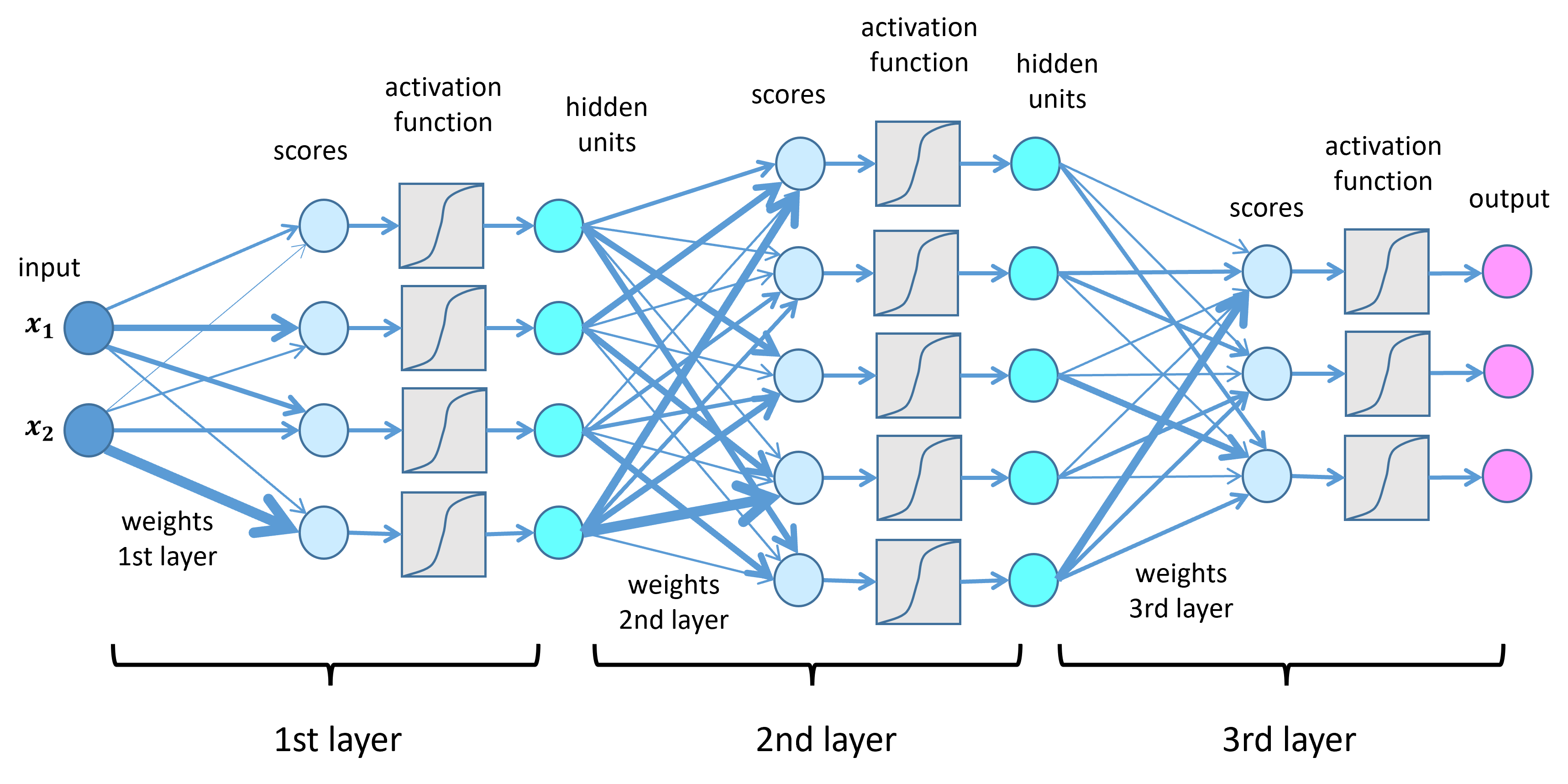
#How It Works
#Basic Structure A neural network consists of three primary components:
- Input Layer: Receives the raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Intermediate layers where computations occur. Each layer transforms the input data using weighted connections and activation functions.
- Output Layer: Produces the final prediction or classification (e.g., identifying an object in an image).
#Key Concepts
Neurons and Weights Each neuron in a layer is connected to neurons in the next layer via weights, which determine the strength of the connection. During training, these weights are adjusted to minimize the difference between the predicted output and the actual output (error).
Activation Functions Activation functions introduce non-linearity into the network, enabling it to learn complex patterns. Common functions include:
- Sigmoid: Outputs values between 0 and 1, useful for binary classification.
- ReLU (Rectified Linear Unit): Outputs the input directly if positive, otherwise zero; widely used in hidden layers due to computational efficiency.
- Softmax: Converts outputs into probabilities, ideal for multi-class classification.
Forward Propagation Data flows through the network in a process called forward propagation: 1. Input data is fed into the input layer. 2. Each neuron computes a weighted sum of its inputs, adds a bias term, and applies an activation function. 3. The output of one layer becomes the input for the next.
Loss Function The loss function measures the difference between the predicted output and the true label. Common loss functions include:
- Mean Squared Error (MSE): Used for regression tasks.
- Cross-Entropy Loss: Used for classification tasks.
Backpropagation Backpropagation is the algorithm used to train neural networks: 1. The loss is computed at the output layer. 2. The gradient of the loss with respect to each weight is calculated using the chain rule of calculus. 3. Weights are updated in the opposite direction of the gradient to reduce the loss (gradient descent).
Optimization Optimization algorithms adjust the weights to minimize the loss. Popular methods include:
- Stochastic Gradient Descent (SGD): Updates weights using a subset of the data.
- Adam: Combines momentum and adaptive learning rates for faster convergence.
#Types of Neural Networks
| Type | Description | Applications | |------------------------|---------------------------------------------------------------------------------|-------------------------------------------| | Feedforward NN | Data flows in one direction (input → output). | Classification, Regression | | Convolutional NN | Uses convolutional layers to extract spatial features from images. | Image Recognition, Object Detection | | Recurrent NN | Contains loops to process sequential data (e.g., time series). | Speech Recognition, Language Modeling | | Long Short-Term Memory (LSTM) | A type of RNN that mitigates the vanishing gradient problem. | Time Series Forecasting, Machine Translation | | Transformer | Relies on self-attention mechanisms to process sequential data. | Natural Language Processing, NLP | | Generative Adversarial Network (GAN) | Consists of a generator and discriminator competing to improve outputs. | Image Generation, Data Augmentation |
#Important Facts
- Universal Approximation Theorem: A neural network with a single hidden layer containing a sufficient number of neurons can approximate any continuous function, given appropriate weights.
- Overfitting: Neural networks can memorize training data, leading to poor performance on unseen data. Techniques like dropout (randomly deactivating neurons during training) and regularization (penalizing large weights) mitigate this issue.
- Vanishing Gradient Problem: In deep networks, gradients can become extremely small during backpropagation, hindering learning in early layers. Solutions include ReLU activation and batch normalization.
- Transfer Learning: Pre-trained models (e.g., ResNet, BERT) can be fine-tuned for specific tasks, reducing the need for large datasets.
- Hardware Acceleration: Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) significantly speed up neural network training by parallelizing computations.
- Ethical Concerns: Neural networks can inherit biases from training data, leading to unfair or discriminatory outcomes. Addressing AI ethics and bias mitigation is an active area of research.
#Timeline
- Foundational ideas
Core concepts and early methods shape How Do Neural Networks Work?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How Do Neural Networks Work? cover?
Explains how do neural networks work?, including the main process, tools, examples, risks, and practical implementation steps.
Why is How Do Neural Networks Work? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Do, Neural, Networks before using the ideas in real projects.
#References
- How Do Neural Networks Work? terminology and background research
- How Do Neural Networks Work? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Do case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.