
#Short Answer
Explains how to get started with natural language processing, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
Natural Language Processing (NLP) bridges the gap between human communication and computer understanding by allowing machines to read, interpret, and respond to text or speech in a meaningful way. It combines computational linguistics—rule-based modeling of human language—with statistical, machine learning, and deep learning models to enable applications such as voice assistants, translation services, and automated content moderation. At its core, NLP transforms unstructured text data into structured formats that computers can process. This involves breaking down language into components like words, sentences, and grammatical structures, then applying algorithms to derive insights or generate human-like responses. The field has evolved significantly from early rule-based systems to modern transformer-based models that achieve near-human performance in tasks like language translation and question answering. NLP is now a cornerstone of AI, powering tools used across industries including healthcare (for analyzing clinical notes), finance (for sentiment-driven trading), and customer service (via intelligent chatbots). Its interdisciplinary nature draws from linguistics, computer science, and cognitive psychology, making it both challenging and rewarding to master.
#History / Background
The origins of NLP trace back to the 1950s, when researchers first attempted to translate human language using computers. One of the earliest milestones was the Georgetown-IBM experiment in 1954, which demonstrated the automatic translation of Russian sentences into English using a limited set of rules. This period was dominated by symbolic AI approaches, where linguists manually encoded grammatical rules into systems. In the 1960s and 1970s, NLP research expanded with the development of early parsers and semantic networks, such as Terry Winograd’s SHRDLU system, which could understand and respond to commands in a restricted English domain. However, progress was slow due to the complexity of human language and the limitations of computational power. The 1980s and 1990s saw a shift toward statistical methods, driven by the availability of large text corpora and advances in machine learning. Researchers began using probabilistic models like Hidden Markov Models (HMMs) for speech recognition and part-of-speech tagging. The introduction of the Penn Treebank in 1993 provided a standardized dataset for training and evaluating NLP models, accelerating research. The 2000s marked a turning point with the rise of machine learning techniques, particularly supervised learning models trained on annotated datasets. Algorithms like Support Vector Machines (SVMs) and Conditional Random Fields (CRFs) became standard for tasks such as named entity recognition and sentiment analysis. Concurrently, the internet boom provided vast amounts of text data, fueling the development of web-scale NLP applications. The breakthrough came in 2017 with the introduction of the Transformer architecture by Vaswani et al. in the paper Attention Is All You Need. Transformers, with their self-attention mechanism, enabled models like BERT (Bidirectional Encoder Representations from Transformers) and later GPT (Generative Pre-trained Transformer) to achieve unprecedented accuracy in language understanding and generation. These models pre-train on massive text corpora and fine-tune for specific tasks, forming the backbone of modern NLP systems. Today, NLP continues to advance with the integration of multimodal models that combine text with images and audio, and with ethical considerations around bias, privacy, and misinformation becoming central to research and deployment.
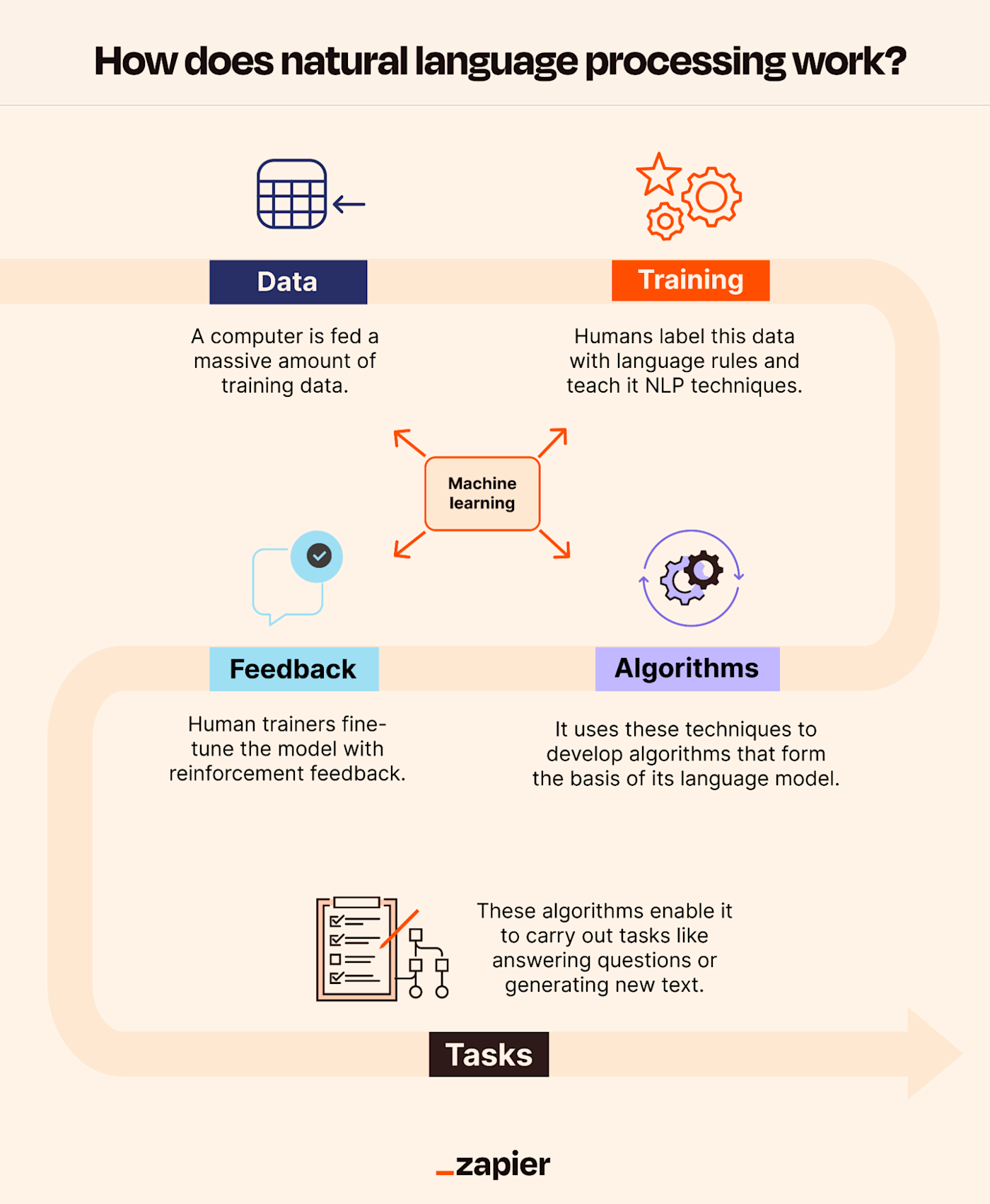
#How It Works
Natural Language Processing operates through a pipeline of stages that transform raw text into actionable insights or responses. The process typically involves several key steps:
#
- Text Preprocessing Raw text data is cleaned and normalized to prepare it for analysis. Common preprocessing steps include:
- Tokenization: Splitting text into individual words or tokens.
- Lowercasing: Converting all text to lowercase to ensure uniformity.
- Removing Punctuation and Stopwords: Eliminating non-essential characters and common words (e.g., "the", "and").
- Stemming and Lemmatization: Reducing words to their base or root form (e.g., "running" → "run").
- Handling Noise: Correcting typos, removing special characters, and addressing encoding issues.
#
- Feature Extraction Text must be converted into numerical representations that machine learning models can process. Traditional methods include:
- Bag-of-Words (BoW): Represents text as the frequency of words, ignoring grammar and word order.
- TF-IDF (Term Frequency-Inverse Document Frequency): Weighs words by their importance across a corpus.
- Word Embeddings: Dense vector representations that capture semantic meaning (e.g., Word2Vec, GloVe). Modern approaches rely on contextual embeddings from deep learning models like BERT, which generate dynamic representations based on surrounding text.
#
- Model Training NLP models are trained using labeled data for supervised tasks or unlabeled data for unsupervised or self-supervised learning. Common model types include:
- Rule-Based Systems: Use predefined linguistic rules (e.g., regular expressions).
- Machine Learning Models: Such as Naive Bayes, SVMs, or Random Forests for classification tasks.
- Deep Learning Models: Including Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Transformers for sequence modeling.
- Transformer Models: Pre-trained on large corpora and fine-tuned for specific applications (e.g., text classification, translation).
#
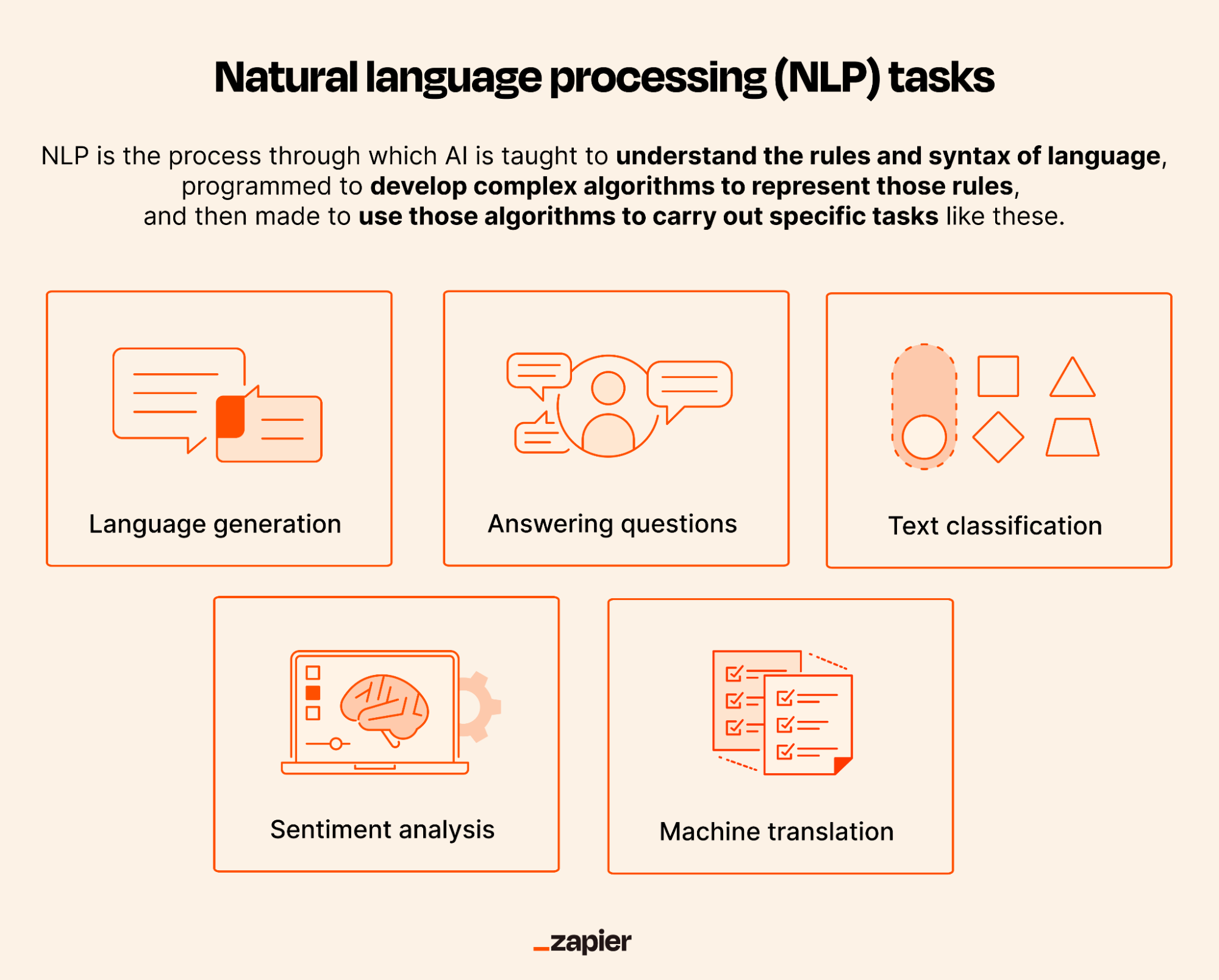
- Task-Specific Processing Depending on the application, NLP systems perform specialized tasks:
- Sentiment Analysis: Classifying text as positive, negative, or neutral.
- Named Entity Recognition (NER): Identifying entities like people, organizations, and locations.
- Part-of-Speech (POS) Tagging: Labeling words with grammatical categories.
- Machine Translation: Converting text from one language to another.
- Text Summarization: Generating concise summaries of long documents.
- Question Answering: Extracting answers from text based on queries.
#
- Post-Processing and Output The final output is refined and presented in a user-friendly format. For example: - A chatbot may format a response into natural language. - A translation system may output a grammatically correct sentence. - A sentiment analysis tool may generate a report with sentiment scores.
#Important Facts
- NLP is not perfect: Despite advances, NLP systems can struggle with ambiguity, sarcasm, and domain-specific language. Errors in translation or sentiment analysis are common in real-world applications.
- Data is king: High-quality, diverse, and well-labeled datasets are essential for training accurate NLP models. Bias in training data can lead to biased outputs.
- Multilingual NLP is challenging: Most NLP research focuses on English, leaving many languages underrepresented. Efforts like multilingual BERT aim to address this gap.
- Ethical concerns: NLP systems can perpetuate biases, invade privacy, or spread misinformation. Responsible AI practices are critical.
- Real-time processing: Many NLP applications require low-latency processing, such as voice assistants or live chatbots.
- Interdisciplinary field: NLP draws from linguistics, computer science, psychology, and cognitive science, making it a rich area for collaboration.
- Open-source tools: Libraries like spaCy, NLTK, and Hugging Face Transformers democratize access to NLP, enabling developers to build advanced systems without starting from scratch.
- Energy consumption: Training large language models like GPT-3 requires significant computational resources, raising sustainability concerns.
#Timeline
- Foundational ideas
Core concepts and early methods shape How to Get Started with Natural Language Processing.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How to Get Started with Natural Language Processing cover?
Explains how to get started with natural language processing, including the main process, tools, examples, risks, and practical implementation steps.
Why is How to Get Started with Natural Language Processing important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Get, Started, Natural before using the ideas in real projects.
#References
- How to Get Started with Natural Language Processing terminology and background research
- How to Get Started with Natural Language Processing use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Get case studies, benchmarks, and current industry analysis
Comments
No comments yet. Start the discussion with a useful note.