#Short Answer
Explains how to debug ai models, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
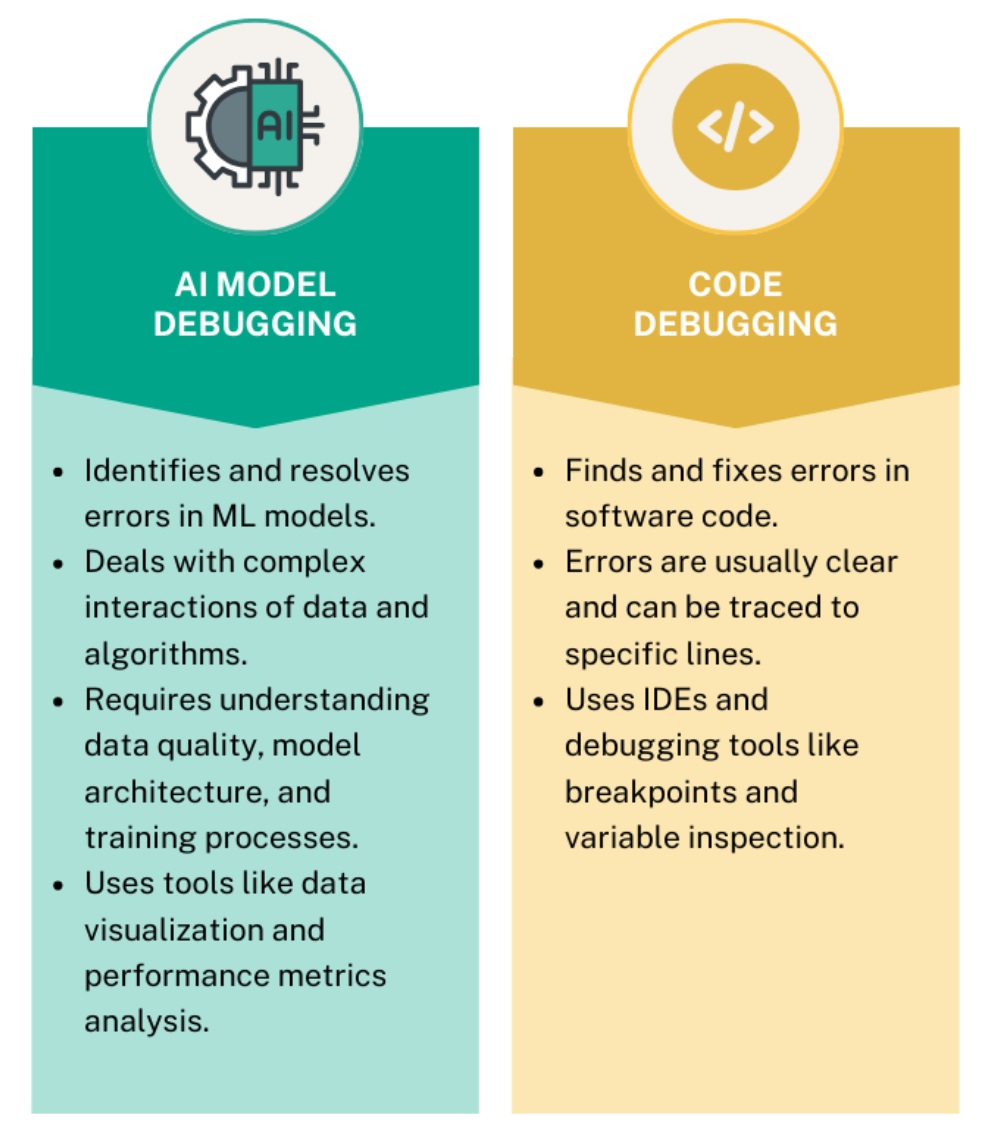
Debugging AI models is a critical phase in the machine learning lifecycle, ensuring that models generalize well to unseen data and perform as intended. Unlike traditional software debugging, which often relies on explicit error messages, AI model debugging focuses on statistical and performance-based anomalies. Issues such as overfitting (where a model performs well on training data but poorly on test data) and underfitting (where a model fails to capture underlying patterns) are common challenges that require systematic debugging approaches. The process involves multiple stages, including data inspection, model evaluation, and iterative refinement. Debugging is not a one-time task but an ongoing effort that spans the entire model development pipeline, from data collection to deployment. Effective debugging enhances model robustness, reduces bias, and improves interpretability, making it essential for deploying trustworthy AI systems.
#History / Background
The concept of debugging in computing dates back to the early days of programming, where errors were manually traced and corrected. However, debugging AI models emerged as a distinct discipline with the rise of machine learning in the late 20th and early 21st centuries. The advent of deep learning in the 2010s accelerated the need for specialized debugging techniques due to the complexity and opacity of neural networks. Early debugging methods were largely heuristic, relying on trial-and-error adjustments to model parameters. As the field matured, systematic approaches such as cross-validation, regularization, and hyperparameter optimization became standard practices. The introduction of tools like TensorFlow and PyTorch in the 2010s further streamlined the debugging process by providing built-in functionalities for monitoring model performance and visualizing training dynamics. The increasing emphasis on ethical AI and explainable machine learning has further underscored the importance of debugging. Regulatory frameworks and industry standards now mandate rigorous testing and validation of AI models, making debugging an integral part of compliance and risk management.
#How It Works
Debugging AI models involves a multi-step process designed to identify and resolve issues that affect model performance. The following sections outline the key components of this process:
#Data Debugging
- Data Inspection:
- Data Quality: Ensure datasets are free from errors, missing values, and inconsistencies. Techniques such as data profiling and statistical analysis help identify anomalies.
- Bias and Fairness: Assess datasets for biases that may lead to unfair or discriminatory outcomes. Tools like fairness-aware algorithms and bias detection metrics are used to mitigate these issues.
- Data Splitting:
- Train-Test Split: Divide data into training, validation, and test sets to evaluate model performance on unseen data.
- Cross-Validation: Use techniques like k-fold cross-validation to ensure the model generalizes well across different subsets of data.
#Model Debugging
- Performance Metrics:
- Accuracy and Loss Functions: Monitor metrics such as accuracy, precision, recall, and loss to identify deviations from expected performance.
- Confusion Matrices: Visualize model performance across different classes to pinpoint areas of weakness.
- Overfitting and Underfitting:
- Overfitting: Occurs when a model learns noise or irrelevant patterns in the training data. Techniques to address overfitting include:
- Regularization: Apply L1 or L2 regularization to penalize large weights and prevent overfitting.
- Dropout: Randomly deactivate neurons during training to reduce reliance on specific features.
- Early Stopping: Halt training when validation performance plateaus to prevent the model from memorizing training data.
- Underfitting: Occurs when a model fails to capture underlying patterns. Solutions include:
- Feature Engineering: Enhance the dataset with additional relevant features.
- Increasing Model Complexity: Use deeper or more sophisticated architectures.
- Hyperparameter Tuning: Adjust learning rates, batch sizes, and other parameters to improve performance.
- Error Analysis:
- Residual Analysis: Examine prediction errors to identify patterns or systematic biases.
- Ablation Studies: Systematically remove or modify components of the model to assess their impact on performance.
#Hyperparameter Optimization Hyperparameters are settings that govern the learning process of a model. Debugging often involves tuning these parameters to achieve optimal performance. Techniques include:
- Grid Search: Exhaustively search through a predefined set of hyperparameters.
- Random Search: Sample hyperparameters randomly to explore a wider range of possibilities.
- Bayesian Optimization: Use probabilistic models to guide the search for optimal hyperparameters efficiently.
#Tools and Frameworks Several tools and frameworks facilitate the debugging process:
- TensorFlow and PyTorch: Provide built-in functionalities for monitoring training dynamics, visualizing model architectures, and debugging gradients.
- Weights & Biases: Offers experiment tracking, visualization, and collaboration features for debugging and optimizing models.
- MLflow: Enables tracking of experiments, managing models, and deploying debugging insights.
- SHAP and LIME: Explainable AI tools that help interpret model decisions and identify potential biases or errors.
#Important Facts
- Overfitting vs. Underfitting: - Overfitting occurs when a model learns the training data too well, including noise, leading to poor generalization. - Underfitting occurs when a model is too simple to capture the underlying patterns in the data, resulting in high bias.
- Bias-Variance Tradeoff: - High bias (underfitting) and high variance (overfitting) are two extremes that must be balanced to achieve optimal model performance.
- Data Leakage: - A critical issue where information from the test set inadvertently influences the training process, leading to overly optimistic performance estimates.
- Reproducibility: - Debugging often requires reproducible results, which can be achieved by setting random seeds, documenting data preprocessing steps, and using version control for code and datasets.
- Interpretability: - Debugging is closely tied to model interpretability, as understanding why a model makes certain predictions is essential for identifying and correcting errors.
#Timeline
- Foundational ideas
Core concepts and early methods shape How to Debug AI Models.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How to Debug AI Models cover?
Explains how to debug ai models, including the main process, tools, examples, risks, and practical implementation steps.
Why is How to Debug AI Models important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Debug, AI, Models before using the ideas in real projects.
#References
- How to Debug AI Models terminology and background research
- How to Debug AI Models use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Debug case studies, benchmarks, and current industry analysis



Comments
No comments yet. Start the discussion with a useful note.