#Short Answer
Explains how does generative ai work?, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
Generative AI represents a transformative branch of artificial intelligence focused on creating new, original content rather than merely analyzing or classifying existing data. Unlike traditional AI systems designed for prediction or classification, generative models learn the underlying structure and patterns of their training data and use this knowledge to produce novel outputs that can be indistinguishable from human-made content. At its core, generative AI operates by identifying statistical correlations within vast datasets. For example, a language model trained on millions of books learns not just vocabulary and grammar but also stylistic nuances, contextual relationships, and even cultural references. When prompted, it generates text that reflects these learned patterns, often producing coherent and contextually appropriate responses. The applications of generative AI are vast and continue to expand. In creative industries, it assists artists, writers, and musicians in generating ideas, drafts, or even complete works. In business, it powers chatbots, automates customer service responses, and aids in data synthesis for research. In technology, it enables the creation of synthetic training data, reducing the need for real-world datasets in certain scenarios. Despite its potential, generative AI also raises significant challenges, including concerns about authenticity, intellectual property, and the potential for misuse in spreading misinformation or deepfakes. These issues have spurred ongoing debates about regulation, ethical use, and the need for transparency in AI-generated content.
#History / Background
The concept of machines generating creative or novel content dates back to the early days of computing, but the field of generative AI as we know it today began to take shape in the mid-to-late 20th century.
#Early Foundations (1950s–1980s)
The theoretical groundwork for generative AI was laid by early computer scientists exploring symbolic reasoning and rule-based systems. In 1950, Alan Turing proposed the "Imitation Game," now known as the Turing Test, which challenged machines to generate human-like responses—a foundational idea for generative systems. By the 1960s, ELIZA, one of the first chatbots, demonstrated how simple pattern-matching algorithms could simulate conversation, albeit in a limited way. During the 1980s, advances in statistical modeling and machine learning began to influence generative approaches. Hidden Markov Models (HMMs) and early neural networks were used for tasks like speech synthesis and text generation, though their outputs were often rigid and lacked creativity.
#The Rise of Deep Learning (2000s–2010s)
The breakthrough in generative AI came with the advent of deep learning, particularly the development of neural networks with multiple layers (deep neural networks). In 2006, Geoffrey Hinton and colleagues introduced deep belief networks, which significantly improved the training of complex models. This paved the way for more sophisticated generative architectures. A major milestone occurred in 2014 with the introduction of Generative Adversarial Networks (GANs) by Ian Goodfellow and his team. GANs consist of two neural networks—a generator and a discriminator—that compete against each other. The generator creates data (e.g., images), while the discriminator evaluates its authenticity. This adversarial training process led to dramatic improvements in the quality of generated images, videos, and even audio. Around the same time, advances in natural language processing (NLP) enabled the development of more capable language models. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks were used to generate text, though they struggled with long-range dependencies and coherence.
#The Transformer Era (2017–Present)
The most transformative period in generative AI began with the introduction of the Transformer architecture in 2017. Proposed in the paper "Attention Is All You Need" by researchers at Google, the Transformer replaced traditional recurrent and convolutional layers with self-attention mechanisms, allowing models to process sequences more efficiently and capture long-range dependencies. This architecture became the backbone of modern large language models (LLMs). In 2018, OpenAI released GPT (Generative Pre-trained Transformer), followed by GPT-2 in 2019 and GPT-3 in 2020. These models demonstrated unprecedented ability to generate coherent, contextually relevant text across a wide range of topics and styles. Subsequent models like Google’s LaMDA, Meta’s LLaMA, and Mistral’s models further refined the capabilities of LLMs. Parallel to text generation, generative models for images also advanced rapidly. DALL-E (2021), developed by OpenAI, combined a Transformer-based language model with a diffusion model to generate images from text descriptions. Stable Diffusion (2022), an open-source model, democratized image generation by making it accessible to researchers and artists worldwide. The 2020s have seen generative AI integrated into mainstream applications, from AI-powered writing assistants like Grammarly and Jasper to image generators used in marketing, design, and entertainment. Companies across industries are exploring generative AI for automation, personalization, and innovation.
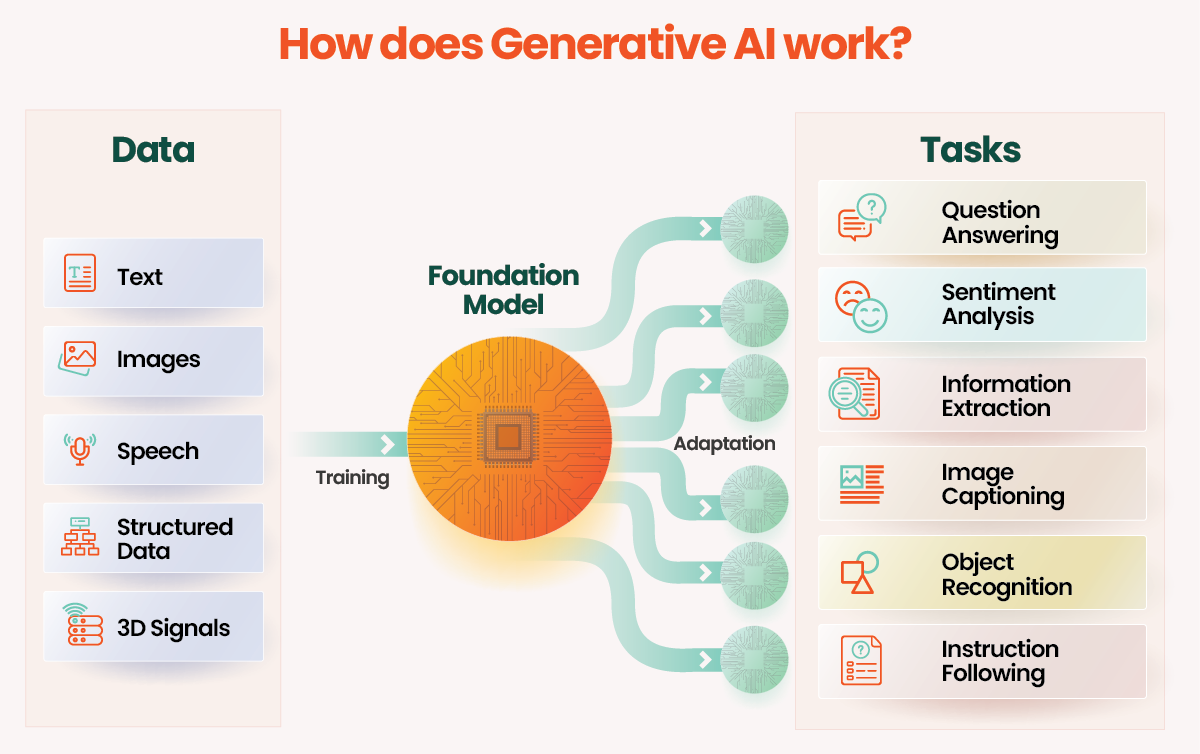
#How It Works
Generative AI systems rely on sophisticated machine learning models trained on large datasets. While the specific architectures vary depending on the type of content being generated (text, images, audio, etc.), the underlying principles are often similar. Below is a breakdown of how generative AI works, focusing on the most common approaches.
#Core Principles
- Learning from Data Generative models learn by analyzing patterns in their training data. For example, a text-generating model trained on novels learns grammar, syntax, and stylistic elements. An image-generating model trained on photographs learns textures, shapes, and color distributions.
- Probabilistic Modeling Most generative models are probabilistic, meaning they estimate the likelihood of different outputs. For instance, given a prompt like "The cat sat on the," the model calculates the probability of the next word being "mat," "couch," or "floor," and selects the most likely option—or samples from the distribution.
- Autoregressive Generation Many generative models generate content sequentially. In text generation, the model predicts one word at a time, using previously generated words as context. This process continues until a stopping condition is met (e.g., a maximum length or end-of-sequence token).
- Latent Space Representation Generative models often work in a "latent space," a compressed, abstract representation of the data. For example, an image generator might map images to a lower-dimensional space where similar images are close together. New images are created by sampling points in this space and decoding them back into pixel space.
#Key Architectures
- Generative Adversarial Networks (GANs)
GANs consist of two neural networks:
- Generator: Creates new data (e.g., images) from random noise or a latent vector.
- Discriminator: Evaluates whether the generated data is real (from the training set) or fake (from the generator). The two networks are trained simultaneously in a competitive process: - The generator aims to produce data that fools the discriminator. - The discriminator aims to correctly identify real vs. fake data. Over time, the generator improves, producing increasingly realistic outputs. GANs have been particularly successful in generating high-quality images, videos, and even audio. Example Use Cases: - Creating realistic human faces (e.g., StyleGAN). - Generating art or design variations. - Enhancing image resolution (super-resolution). Challenges: - Training instability (mode collapse, where the generator produces limited varieties). - Difficulty in evaluating the quality of generated outputs.
- Variational Autoencoders (VAEs)
VAEs are a type of autoencoder designed for generative tasks. They consist of:
- Encoder: Maps input data (e.g., an image) to a latent space distribution.
- Decoder: Reconstructs data from a sample drawn from the latent space. Unlike traditional autoencoders, VAEs impose a probabilistic structure on the latent space, allowing for smooth interpolation between points. This enables the generation of new, diverse data points by sampling from the latent space. Example Use Cases: - Generating new images by interpolating between existing ones. - Anomaly detection (identifying outliers in data). - Data compression and denoising. Advantages: - Stable training compared to GANs. - Provides a structured latent space for exploration. Limitations: - Generated outputs may be blurrier than those from GANs. - Less effective for high-resolution image generation.
- Diffusion Models
Diffusion models are a class of generative models that work by gradually adding noise to data and then learning to reverse this process. They consist of two phases:
- Forward Diffusion: Gradually corrupts data by adding Gaussian noise over many steps.
- Reverse Diffusion: A neural network learns to denoise the corrupted data, eventually reconstructing the original input. Diffusion models have gained popularity for their ability to generate high-quality, detailed images and other data types. Example Use Cases: - Image generation (e.g., DALL-E 2, Stable Diffusion). - Audio synthesis (e.g., generating speech or music). - Molecular design in drug discovery. Advantages: - High-quality, diverse outputs. - Stable training process. - Scalability to large datasets. Challenges: - Computationally intensive (requires many denoising steps). - Slower generation compared to other models.
- Transformer-Based Models (for Text Generation)
Transformer-based models, particularly those using the decoder-only architecture (e.g., GPT series), dominate modern text generation. These models rely on:
- Self-Attention Mechanisms: Allow the model to weigh the importance of different words in a sequence, regardless of their position.
- Pre-training: The model is first trained on a large corpus of text to learn general language patterns (e.g., grammar, semantics).
- Fine-Tuning: The pre-trained model is adapted to specific tasks or domains (e.g., chatbots, code generation). Example Use Cases: - Chatbots and virtual assistants. - Content creation (e.g., articles, marketing copy). - Code generation and debugging. - Translation and summarization. Advantages: - High coherence and contextual understanding. - Ability to handle long-range dependencies. - Versatility across tasks. Challenges: - Requires massive computational resources for training. - Potential for generating biased or harmful content. - Hallucinations (generating false or nonsensical information).
#Training Process
The training process for generative models typically involves the following steps:
- Data Collection: A large dataset relevant to the task is collected. For text generation, this might include books, articles, and web pages. For image generation, it could include millions of labeled or unlabeled images.
- Preprocessing: Data is cleaned, normalized, and formatted for training. For example, text may be tokenized (split into words or subwords), and images may be resized or augmented.
- Model Selection: An appropriate architecture is chosen based on the task (e.g., GAN for images, Transformer for text).
- Training: The model is trained using optimization techniques like stochastic gradient descent (SGD) or Adam. The loss function measures how well the model’s outputs match the training data. For GANs, the loss is a combination of generator and discriminator losses.
- Evaluation: The model’s outputs are evaluated for quality, diversity, and coherence. Metrics like Inception Score (for images) or perplexity (for text) are used to assess performance.
- Deployment: The trained model is deployed in applications, often with additional safeguards to prevent misuse (e.g., content filters, rate limits).
#Challenges in Generative AI Despite its advancements, generative AI faces several challenges:
- Data Quality and Bias: Generative models learn from the data they are trained on. If the training data contains biases (e.g., racial, gender, or cultural biases), the model may perpetuate or amplify these biases in its outputs.
- Hallucinations: Generative models, especially language models, can produce false or nonsensical information with high confidence. This is known as "hallucination" and poses risks in applications like healthcare or legal advice.
- Computational Cost: Training large generative models requires significant computational resources, leading to high costs and environmental concerns due to energy consumption.
- Ethical and Legal Issues: The use of generative AI raises questions about intellectual property (e.g., training on copyrighted material), deepfakes (malicious use of synthetic media), and misinformation.
- Control and Interpretability: Generative models often operate as "black boxes," making it difficult to understand how they produce specific outputs. This lack of interpretability complicates debugging and trust-building.
- Overfitting: Models may memorize training data and reproduce it verbatim, rather than generating novel content. This is particularly problematic in applications like image generation, where overfitting can lead to repetitive outputs.
#Important Facts
- Generative AI is not truly "creative": While generative models can produce novel outputs, they do so by recombining patterns learned from existing data rather than exhibiting human-like creativity or consciousness.
- The term "generative" is broad: It encompasses models that generate text, images, audio, video, 3D models, and even code. Each type of content requires specialized architectures and training techniques.
- Generative AI can be fine-tuned: Pre-trained models like GPT-3 can be adapted to specific domains (e.g., medical, legal, or technical text) through fine-tuning, which involves training the model on smaller, domain-specific datasets.
- Generative models can be used for data augmentation: In machine learning, generative models can create synthetic data to supplement real datasets, improving the performance of other AI models.
- Generative AI is probabilistic: Outputs are not deterministic; the same prompt can generate different responses due to randomness in the sampling process.
- Generative AI is resource-intensive: Training state-of-the-art models like GPT-4 or Stable Diffusion requires thousands of GPUs or TPUs and can cost millions of dollars.
- Generative AI is improving rapidly: Benchmarks like the Turing Test, human evaluation scores, and technical metrics (e.g., FID for images, perplexity for text) show steady improvements in the quality of generated outputs.
#Timeline
- Foundational ideas
Core concepts and early methods shape How Does Generative AI Work?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How Does Generative AI Work? cover?
Explains how does generative ai work?, including the main process, tools, examples, risks, and practical implementation steps.
Why is How Does Generative AI Work? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Generative AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Does, Generative, AI before using the ideas in real projects.
#References
- How Does Generative AI Work? terminology and background research
- How Does Generative AI Work? use cases, implementation examples, and limitations
- Generative AI best practices, standards, and risk guidance
- Does case studies, benchmarks, and current industry analysis




Comments
No comments yet. Start the discussion with a useful note.