#Short Answer
Covers facts about neural networks, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Neural networks are a cornerstone of artificial intelligence, designed to simulate the way biological neurons process information. Unlike traditional programming, which relies on explicit instructions, neural networks learn from data through a process called training, where they adjust internal parameters (weights) to minimize errors. This adaptability makes them particularly effective for tasks involving complex patterns, such as recognizing handwritten digits or translating languages. At their core, neural networks consist of layers of interconnected nodes (neurons). The simplest form is the feedforward neural network, where data flows in one direction—from input to output—through hidden layers. More advanced architectures, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), are tailored for specific tasks like image processing and sequential data analysis, respectively. The power of neural networks lies in their ability to generalize from training data, enabling them to perform well on unseen inputs. This capability has driven breakthroughs in fields like computer vision, where CNNs achieve human-level accuracy in tasks like object detection, and natural language processing (NLP), where models like transformers power chatbots and translation services.
#History / Background
#Early Foundations (1940s–1960s)
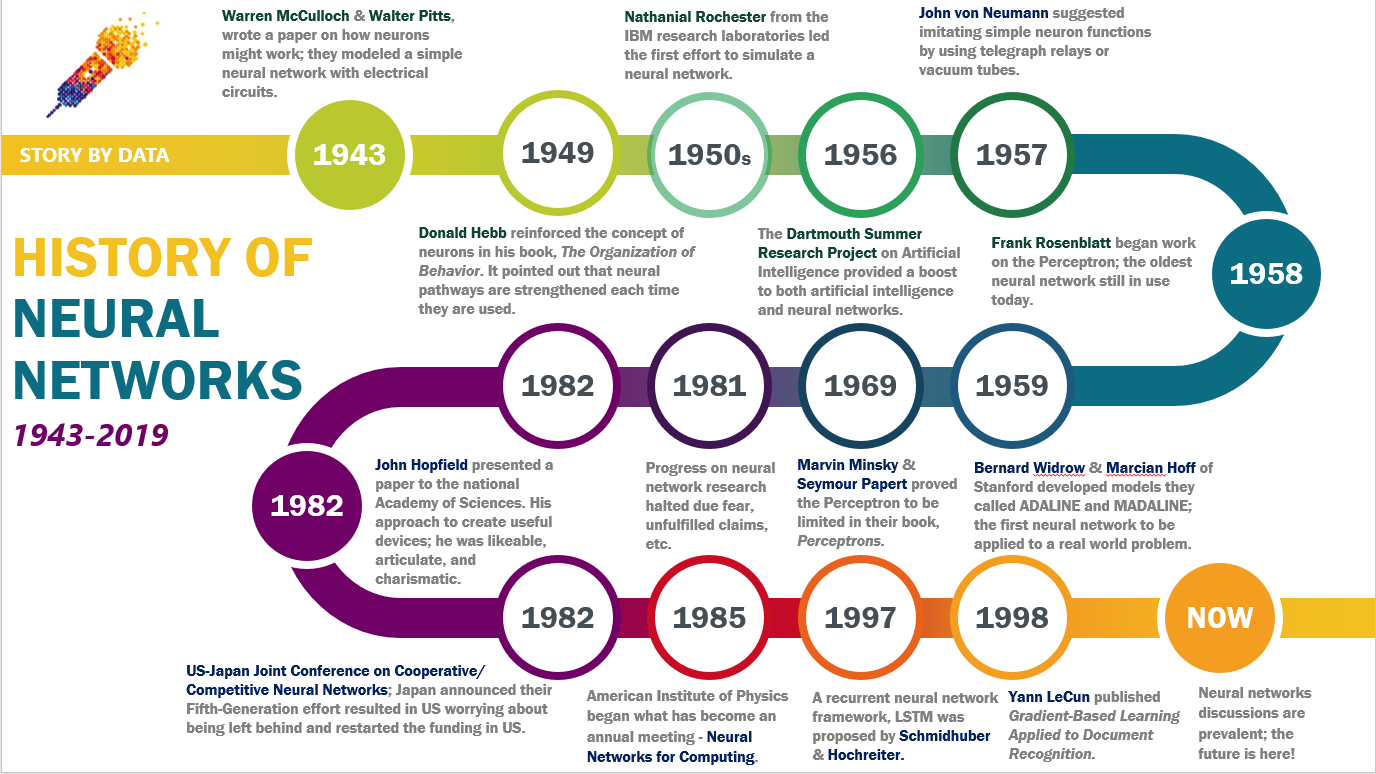
The concept of neural networks traces back to the 1940s, when researchers first attempted to model the brain's neural architecture. In 1943, neurophysiologist Warren McCulloch and mathematician Walter Pitts proposed the first mathematical model of a neuron, laying the groundwork for artificial neural networks (ANNs). Their work demonstrated that simple logical operations could be performed by interconnected neurons, inspiring further research. In 1958, psychologist Frank Rosenblatt developed the Perceptron, the first trainable neural network model. The Perceptron could learn to classify linearly separable data, but its limitations became apparent when it failed to solve problems requiring non-linear decision boundaries. This setback led to a decline in neural network research during the 1970s, a period known as the "AI Winter."
#Revival and Advancements (1980s–2000s)
The field experienced a resurgence in the 1980s with the introduction of backpropagation, an algorithm that efficiently trained multi-layer neural networks by adjusting weights based on error gradients. Researchers like Geoffrey Hinton, Yann LeCun, and David Rumelhart made pivotal contributions, demonstrating that neural networks could solve complex problems, including handwritten digit recognition. During this era, Convolutional Neural Networks (CNNs) emerged as a breakthrough for image processing. LeCun's LeNet-5 (1998) became the first CNN to achieve practical success, paving the way for modern computer vision systems. However, computational limitations and the dominance of symbolic AI approaches temporarily slowed progress.
#The Deep Learning Revolution (2010s–Present)
The 2010s marked the deep learning revolution, driven by three key factors:
- Big Data: The availability of large datasets (e.g., ImageNet) enabled neural networks to learn from vast amounts of information.
- Computational Power: Graphics Processing Units (GPUs) accelerated training, making it feasible to process complex models.
- Algorithmic Innovations: Techniques like dropout, batch normalization, and attention mechanisms improved training efficiency and model performance. Landmark achievements include:
- AlexNet (2012): A CNN that won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), surpassing human-level accuracy in image classification.
- AlphaGo (2016): A deep reinforcement learning model that defeated world champion Go players, showcasing neural networks' strategic decision-making capabilities.
- Transformers (2017): Introduced in the paper "Attention Is All You Need", these architectures revolutionized NLP by enabling models like BERT and GPT to understand context in language. Today, neural networks underpin cutting-edge technologies, from self-driving cars to personalized medicine, with ongoing research focusing on explainability, efficiency, and scalability.
#How It Works
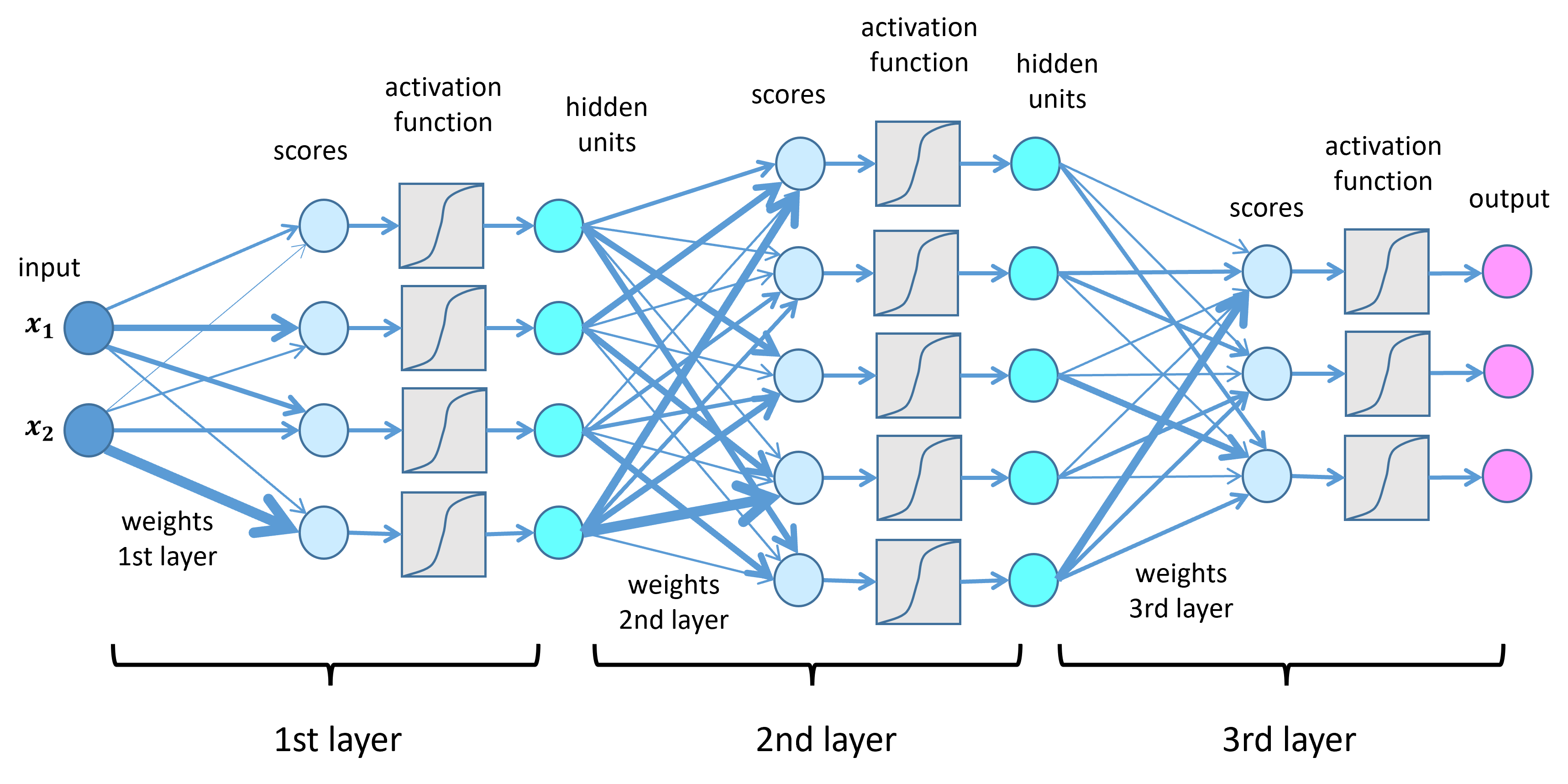
#Basic Structure A neural network comprises three primary types of layers:
- Input Layer: Receives raw data (e.g., pixel values of an image or words in a sentence).
- Hidden Layers: Intermediate layers where computations occur. These layers can be dense (fully connected) or specialized (e.g., convolutional or recurrent).
- Output Layer: Produces the final prediction or classification (e.g., identifying an object or generating text). Each neuron in a layer is connected to neurons in the next layer via weights, which determine the strength of the connection. A neuron's output is calculated by applying an activation function (e.g., ReLU, sigmoid) to a weighted sum of its inputs plus a bias term.
#Training Process
Neural networks learn through supervised learning, where they are fed labeled data (input-output pairs). The training process involves:
- Forward Propagation: Data passes through the network, generating predictions.
- Loss Calculation: A loss function (e.g., mean squared error, cross-entropy) measures the difference between predictions and actual labels.
- Backpropagation: The gradient of the loss function is computed with respect to each weight, and weights are updated using an optimizer (e.g., stochastic gradient descent, Adam) to minimize the loss.
- Iteration: This process repeats over multiple epochs until the model achieves satisfactory performance.
#Key Concepts
- Overfitting: When a model memorizes training data but fails to generalize to unseen data. Techniques like regularization (L1/L2) and dropout mitigate this.
- Hyperparameters: Configurable settings (e.g., learning rate, batch size, number of layers) that influence training and model performance.
- Transfer Learning: Leveraging pre-trained models (e.g., ResNet, BERT) to adapt to new tasks with minimal additional training.
#Advanced Architectures
- Convolutional Neural Networks (CNNs): Use convolutional layers to detect spatial hierarchies in data, ideal for image and video analysis.
- Recurrent Neural Networks (RNNs): Feature loops to process sequential data (e.g., time series, text), though they struggle with long-term dependencies.
- Long Short-Term Memory (LSTM): A type of RNN that addresses long-term dependencies using memory cells.
- Transformers: Rely on self-attention mechanisms to weigh the importance of different parts of the input, enabling parallel processing and superior performance in NLP tasks.
#Important Facts
- Brain-Inspired but Not Brain-Like: While neural networks mimic the brain's structure, they are vastly simplified. A human brain has ~86 billion neurons, whereas modern neural networks typically have millions of artificial neurons.
- Universal Approximation Theorem: A feedforward neural network with a single hidden layer can approximate any continuous function, given sufficient neurons and proper training.
- Black Box Nature: Neural networks often lack interpretability, making it challenging to understand how they arrive at decisions—a critical issue in fields like healthcare and finance.
- Data Hunger: Deep learning models require massive datasets to train effectively. For example, training a state-of-the-art NLP model may consume terabytes of text data.
- Hardware Dependency: Training large neural networks demands specialized hardware, such as GPUs or TPUs (Tensor Processing Units), which can be expensive and energy-intensive.
- Ethical Concerns: Bias in training data can lead to discriminatory outcomes (e.g., facial recognition systems performing poorly on darker-skinned individuals).
- Energy Consumption: The carbon footprint of training large models (e.g., GPT-3) is significant, raising sustainability concerns in AI development.
- Neuromorphic Computing: Emerging hardware designs (e.g., IBM's TrueNorth) aim to replicate biological neural networks more closely, potentially enabling energy-efficient AI.
#Timeline
- Foundational ideas
Core concepts and early methods shape Facts About Neural Networks.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Facts About Neural Networks cover?
Covers facts about neural networks, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Facts About Neural Networks important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Facts, About, Neural before using the ideas in real projects.
#References
- Facts About Neural Networks terminology and background research
- Facts About Neural Networks use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Facts case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.