#Short Answer
Introduces natural language processing for new readers, covering essential concepts, common examples, practical uses, and next steps for learning.
#Infobox
A beginner-friendly introduction to Natural Language Processing (NLP), its applications, and foundational concepts. Natural Language Processing Field Artificial intelligence Subfields Computational linguistics, Text mining, Machine translation Key Techniques Tokenization, Part-of-speech tagging, Named-entity recognition, Sentiment analysis Applications Chatbots, Machine translation, Speech recognition, Text summarization Notable Libraries NLTK, spaCy, Hugging Face Transformers, Stanford NLP First Developed 1950s Pioneers Alan Turing, Noam Chomsky, Geoffrey Hinton
#Overview
Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) that focuses on the interaction between computers and human language. It enables machines to understand, interpret, generate, and respond to human language in a way that is both meaningful and useful. NLP combines computational linguistics—rule-based modeling of human language—with statistical, machine learning, and deep learning models. These technologies allow computers to process human language in the form of text or voice data and perform tasks such as language translation, sentiment analysis, and question answering.
At its core, NLP bridges the gap between human communication and computer understanding. While humans communicate effortlessly through speech and writing, computers require structured data to process information. NLP transforms unstructured language data into structured formats that machines can analyze. This transformation involves several stages, including tokenization, part-of-speech tagging, parsing, and named-entity recognition. These processes help computers extract meaning, identify relationships, and generate coherent responses.
#History / Background
The origins of NLP can be traced back to the 1950s, when researchers first began exploring the possibility of machines understanding and generating human language. One of the earliest milestones was the Turing test, proposed by Alan Turing in 1950, which evaluated a machine's ability to exhibit intelligent behavior equivalent to, or indistinguishable from, that of a human. This test laid the foundation for AI research, including NLP.
In 1954, IBM and Georgetown University demonstrated the first machine translation system, translating 60 Russian sentences into English. This event marked a significant step forward in NLP, although early systems relied heavily on rule-based approaches and were limited in scope. The 1960s and 1970s saw the development of more sophisticated linguistic models, including Noam Chomsky's generative grammar, which influenced computational linguistics and NLP.
The 1980s and 1990s brought statistical methods to NLP, with researchers using corpus linguistics and machine learning techniques to improve language processing. The introduction of the Hidden Markov model and later support vector machines enabled more accurate part-of-speech tagging and named-entity recognition. The turn of the millennium saw the rise of deep learning, particularly with the advent of recurrent neural networks (RNNs) and long short-term memory (LSTM) networks, which revolutionized NLP by enabling more complex language modeling.
#How It Works
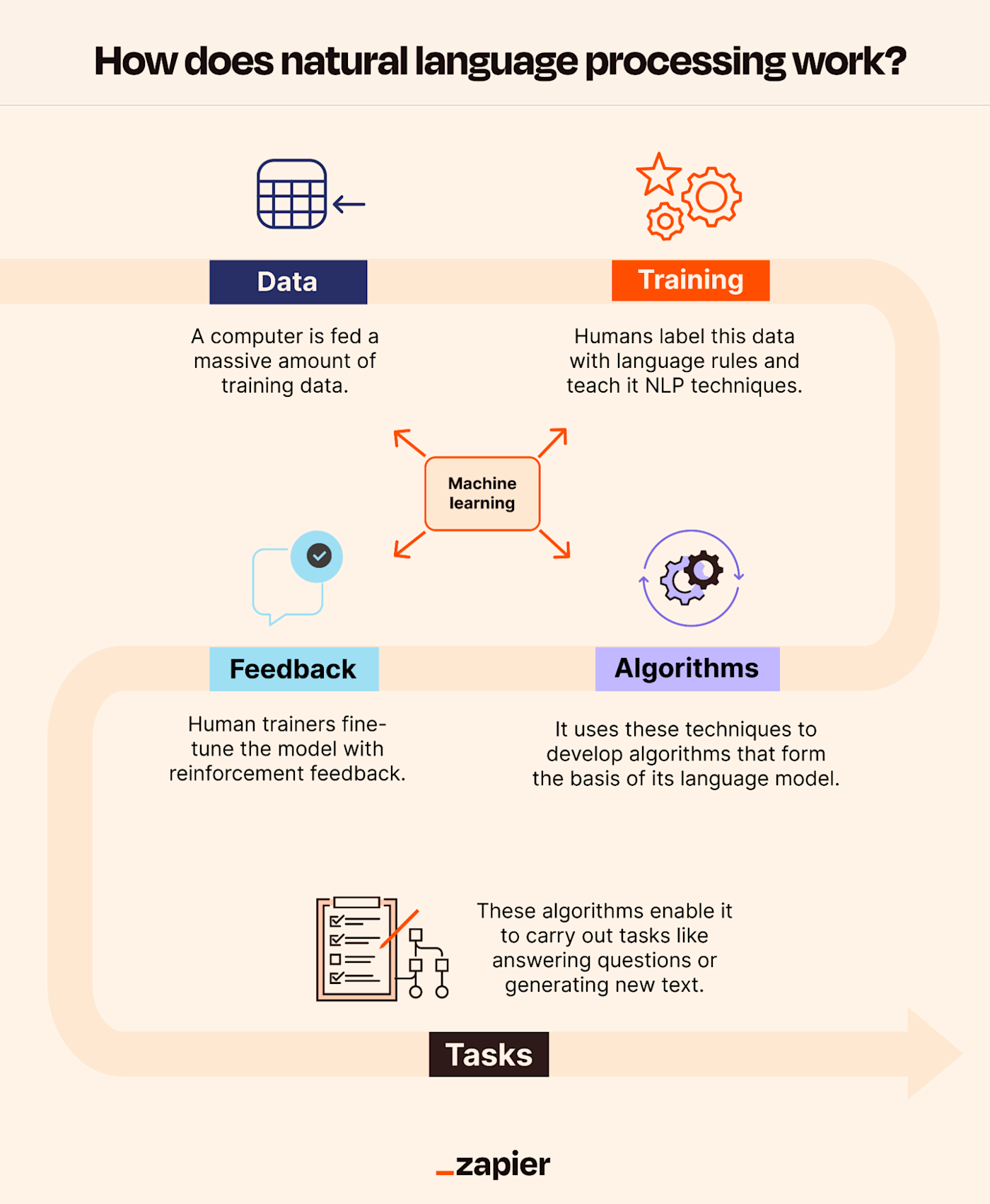
NLP systems operate through a series of interconnected steps that transform raw language data into actionable insights. The process typically begins with text preprocessing, which includes cleaning and normalizing text data to remove noise such as punctuation, special characters, and stop words. This step ensures that the input data is consistent and ready for further analysis.
The next stage involves tokenization, where text is divided into smaller units called tokens, such as words or sentences. Tokenization is crucial because it breaks down the text into manageable pieces that can be analyzed individually. Following tokenization, part-of-speech tagging assigns grammatical labels (e.g., noun, verb, adjective) to each token, helping the system understand the syntactic structure of the sentence.
Named-entity recognition (NER) identifies and classifies named entities in the text, such as people, organizations, locations, and dates. This step is essential for extracting meaningful information from unstructured data. Another critical process is parsing, which analyzes the grammatical structure of sentences to determine relationships between words. For example, parsing can identify the subject, verb, and object in a sentence, providing a deeper understanding of the text.
Once the text is parsed, NLP systems use machine learning or deep learning models to perform tasks such as sentiment analysis, topic modeling, or machine translation. These models are trained on large datasets to recognize patterns and make predictions. For instance, a sentiment analysis model can classify a piece of text as positive, negative, or neutral based on the words and phrases used. Similarly, a machine translation model can convert text from one language to another by learning from parallel corpora.
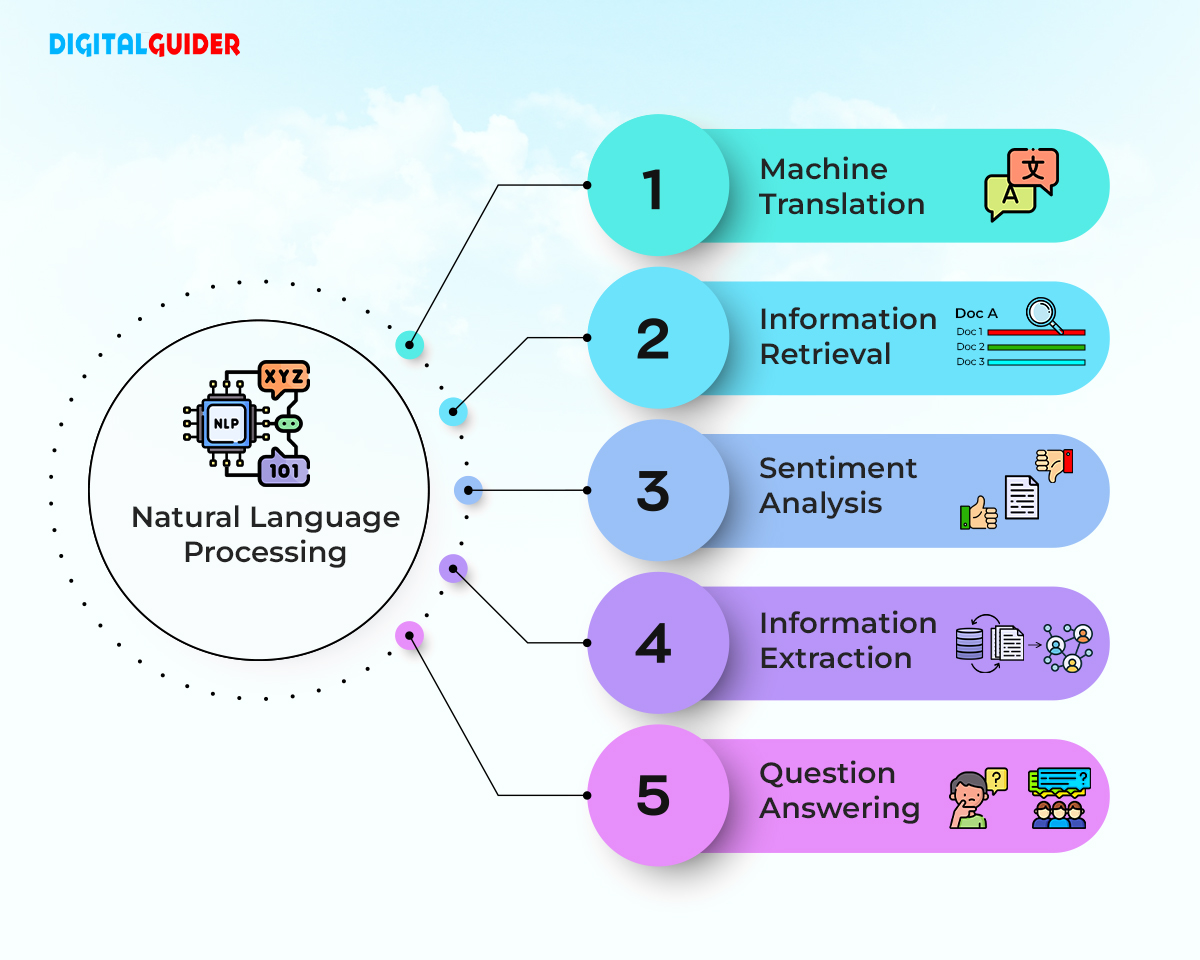
#Key Techniques in NLP
- Tokenization: Splitting text into individual words or sentences.
- Stemming and Lemmatization: Reducing words to their base or root form (e.g., "running" to "run").
- Part-of-Speech Tagging: Assigning grammatical labels to words.
- Named-Entity Recognition: Identifying and classifying entities such as people, places, and organizations.
- Sentiment Analysis: Determining the emotional tone of a piece of text.
- Topic Modeling: Identifying topics present in a collection of documents.
- Machine Translation: Translating text from one language to another.
- Text Summarization: Condensing long texts into shorter summaries.
#Important Facts
- NLP is used in everyday applications such as email filtering, virtual assistants (e.g., Siri, Alexa), and search engines.
- The first NLP program, ELIZA, was developed in the 1960s and simulated conversation by using pattern matching and substitution methods.
- BERT (Bidirectional Encoder Representations from Transformers), developed by Google, revolutionized NLP by using bidirectional training to understand the context of words in a sentence.
- NLP models require large datasets for training, often consisting of millions or billions of words.
- Multilingual NLP enables machines to process and translate text across multiple languages, supporting global communication.
- Ethical considerations in NLP include addressing bias in language models, ensuring data privacy, and preventing misuse of NLP technologies.
#Timeline
Key Milestones in NLP History Year Milestone 1950 Alan Turing proposes the Turing test, laying the groundwork for AI and NLP. 1954 IBM and Georgetown University demonstrate the first machine translation system. 1966 ELIZA, the first chatbot, is developed by Joseph Weizenbaum. 1970s Development of rule-based NLP systems and early linguistic models. 1980s Introduction of statistical methods in NLP, including Hidden Markov Models. 1997 Launch of Google, which later becomes a major player in NLP through its search algorithms. 2011 IBM's Watson wins Jeopardy!, showcasing advanced NLP capabilities in question answering. 2013 Word2Vec, a neural network-based technique for word embeddings, is introduced by Tomas Mikolov. 2018 Google releases BERT, a transformer-based model that significantly improves NLP tasks. 2020 OpenAI's GPT-3, a large-scale language model, demonstrates human-like text generation.
#Related Terms
#FAQ
What does Beginner Guide To Natural Language Processing cover?
Introduces natural language processing for new readers, covering essential concepts, common examples, practical uses, and next steps for learning.
Why is Beginner Guide To Natural Language Processing important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare the benefits, limitations, data requirements, and related themes such as Beginner Friendly, Natural, Language before using the ideas in real projects.
#References
- Beginner Guide To Natural Language Processing terminology and background research
- Beginner Guide To Natural Language Processing use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Beginner Friendly case studies, benchmarks, and current industry analysis
Comments
No comments yet. Start the discussion with a useful note.