#Short Answer
Explains What Is an AI Model, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
An AI model is a computational system trained to perform specific tasks by identifying patterns in data. Unlike traditional software, which follows explicit instructions, AI models learn from examples, improving their performance as they process more data. These models are the foundation of modern AI applications, powering technologies such as virtual assistants, autonomous vehicles, fraud detection systems, and medical diagnostics. AI models operate on the principle of inductive learning, where they generalize from training data to make predictions or decisions on unseen inputs. The effectiveness of an AI model depends on factors such as the quality and quantity of training data, the chosen algorithm, and the model's architecture. Common types of AI models include supervised learning models (e.g., linear regression, decision trees), unsupervised learning models (e.g., clustering algorithms), reinforcement learning models (e.g., Q-learning), and deep learning models (e.g., convolutional neural networks, transformers).
#History / Background
#Early Foundations (1950s–1980s)
The concept of AI models traces back to the mid-20th century, with early work focusing on symbolic AI and rule-based systems. In 1950, Alan Turing proposed the Turing Test, a benchmark for machine intelligence, laying the groundwork for AI research. The 1956 Dartmouth Conference, organized by John McCarthy, Marvin Minsky, and others, marked the birth of AI as a formal discipline. During this era, AI models were primarily rule-based, relying on handcrafted logic to solve problems. However, these systems struggled with scalability and adaptability. The Perceptron, introduced by Frank Rosenblatt in 1958, was one of the first attempts to create a machine learning model inspired by biological neurons, though its limitations were later highlighted by Marvin Minsky and Seymour Papert in their 1969 book Perceptrons.
#The AI Winter and Revival (1980s–2000s)
The 1980s saw a resurgence in AI research with the development of expert systems, which used rule-based logic to mimic human expertise in specific domains. However, these systems were brittle and failed to generalize beyond their predefined rules. The late 1980s and 1990s marked the AI Winter, a period of reduced funding and interest due to unmet expectations. The revival of AI models began in the late 1990s and early 2000s, driven by advances in machine learning and the availability of large datasets. Researchers like Geoffrey Hinton, Yoshua Bengio, and Yann LeCun pioneered deep learning, a subset of machine learning that uses multi-layered neural networks to model complex patterns. The 2012 breakthrough by Hinton's team in image recognition using convolutional neural networks (CNNs) on the ImageNet dataset demonstrated the potential of deep learning, sparking a new wave of AI innovation.
#The Modern Era (2010s–Present)
The 2010s witnessed the democratization of AI models, fueled by open-source frameworks like TensorFlow and PyTorch, cloud computing resources, and the proliferation of big data. Key milestones include:
- 2016: AlphaGo, developed by DeepMind, defeated a world champion Go player, showcasing the power of reinforcement learning.
- 2017: The introduction of Transformer models by Vaswani et al., revolutionizing natural language processing (NLP).
- 2020s: The rise of large language models (LLMs) like GPT-3 and GPT-4, capable of generating human-like text and performing a wide range of tasks. Today, AI models are integral to industries such as healthcare (e.g., drug discovery, medical imaging), finance (e.g., algorithmic trading, risk assessment), and entertainment (e.g., recommendation systems, generative AI).
#How It Works
#Core Components An AI model consists of several key components:
- Data: The raw material used to train the model. Data quality and representativeness are critical for model performance.
- Algorithm: The mathematical procedure or set of rules that the model follows to learn from data. Examples include linear regression, support vector machines (SVMs), and neural networks.
- Parameters: The internal variables of the model that are adjusted during training to minimize error. For example, in a neural network, parameters include weights and biases.
- Loss Function: A metric that quantifies the difference between the model's predictions and the actual outcomes. Common loss functions include mean squared error (MSE) for regression and cross-entropy loss for classification.
- Optimization Algorithm: A method (e.g., gradient descent, Adam) used to update the model's parameters and minimize the loss function.
- Evaluation Metrics: Measures used to assess the model's performance on unseen data, such as accuracy, precision, recall, and F1-score.
#Training Process
The training of an AI model typically involves the following steps:
- Data Collection and Preprocessing: - Gather relevant data from various sources. - Clean the data to handle missing values, outliers, and inconsistencies. - Normalize or standardize the data to ensure consistent scaling. - Split the data into training, validation, and test sets.
- Model Selection: - Choose an appropriate algorithm based on the problem type (e.g., classification, regression, clustering). - Select a model architecture (e.g., a deep neural network for image recognition or a transformer for NLP).
- Training: - Feed the training data into the model. - The model makes predictions and compares them to the actual outcomes using the loss function. - The optimization algorithm adjusts the model's parameters to minimize the loss. - This process repeats over multiple epochs (iterations) until the model's performance on the validation set plateaus or starts to degrade (indicating overfitting).
- Evaluation: - Assess the model's performance on the test set to estimate its generalization ability. - Use evaluation metrics tailored to the problem (e.g., accuracy for classification, mean absolute error for regression).
- Deployment and Monitoring: - Deploy the trained model in a production environment. - Continuously monitor its performance and retrain it with new data to maintain accuracy.
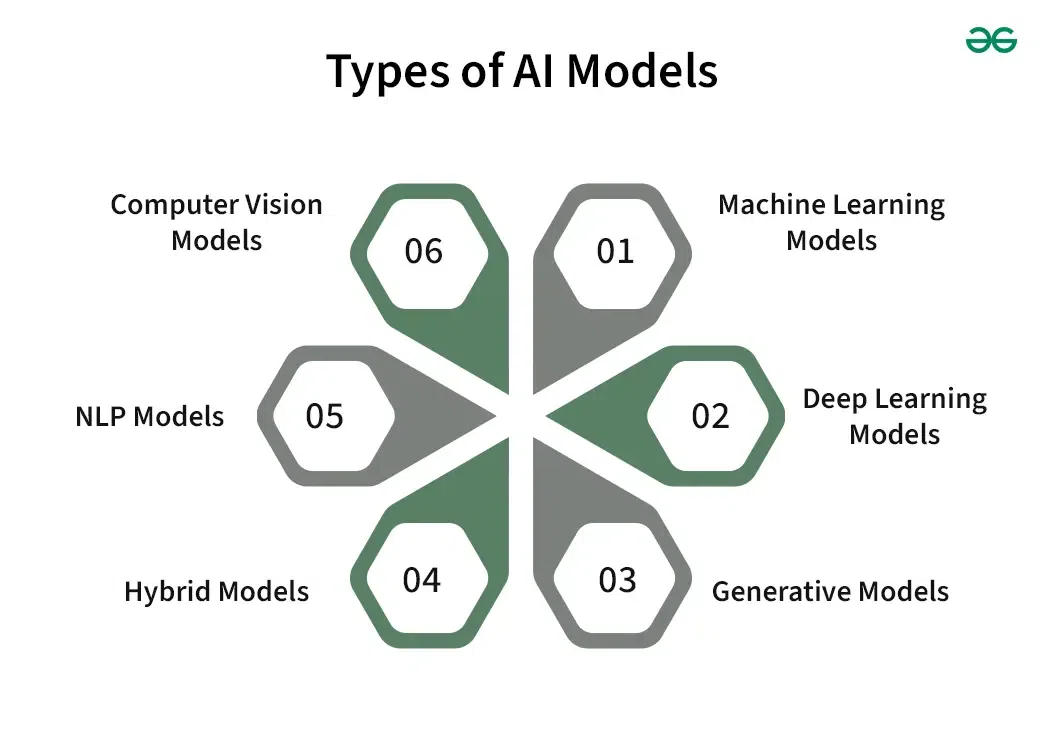
#Types of AI Models AI models can be categorized based on their learning approach and architecture:
| Category | Description | Examples | |-------------------------|---------------------------------------------------------------------------------|------------------------------------------------------------------------------| | Supervised Learning | Models learn from labeled data, where the input-output pairs are provided. | Linear regression, logistic regression, decision trees, support vector machines (SVMs) | | Unsupervised Learning | Models learn from unlabeled data, identifying patterns or groupings. | K-means clustering, principal component analysis (PCA), autoencoders | | Reinforcement Learning | Models learn by interacting with an environment, receiving rewards or penalties. | Q-learning, Deep Q-Networks (DQN), Proximal Policy Optimization (PPO) | | Semi-Supervised Learning | Models learn from a combination of labeled and unlabeled data. | Self-training, co-training, generative adversarial networks (GANs) | | Deep Learning | Models use multi-layered neural networks to learn hierarchical representations. | Convolutional neural networks (CNNs), recurrent neural networks (RNNs), transformers |
#Important Facts
- Bias and Fairness: AI models can inherit biases present in their training data, leading to unfair or discriminatory outcomes. Addressing bias is a critical challenge in AI ethics.
- Overfitting vs. Underfitting:
- Overfitting occurs when a model learns the training data too well, including noise, and performs poorly on unseen data.
- Underfitting occurs when a model is too simple to capture the underlying patterns in the data.
- Transfer Learning: A technique where a pre-trained model is fine-tuned for a new task, reducing the need for large amounts of labeled data.
- Explainability: Many AI models, particularly deep learning models, are often referred to as "black boxes" due to their lack of interpretability. Techniques like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) aim to make models more transparent.
- Computational Resources: Training large AI models (e.g., LLMs) requires significant computational power, often necessitating the use of GPUs or TPUs and distributed computing.
- Data Privacy: AI models trained on sensitive data (e.g., medical records) must comply with regulations like GDPR and HIPAA to protect user privacy.
- Model Drift: The phenomenon where a model's performance degrades over time due to changes in the underlying data distribution (e.g., shifting user preferences in recommendation systems).
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is an AI Model?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is an AI Model? cover?
Explains What Is an AI Model, including the core definition, how it works, practical examples, and limitations.
Why is What Is an AI Model? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as AI, Model, Implementation before using the ideas in real projects.
#References
- What Is an AI Model? terminology and background research
- What Is an AI Model? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- AI case studies, benchmarks, and current industry analysis




Comments
No comments yet. Start the discussion with a useful note.