
#Short Answer
Explains What Is a T5 Model, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
The T5 model represents a paradigm shift in natural language processing by unifying diverse NLP tasks under a single text-to-text framework. Developed by Google Research and introduced in the 2019 paper "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer", T5 leverages the Transformer architecture, originally proposed in the 2017 paper "Attention Is All You Need" by Vaswani et al. Unlike traditional models that require separate architectures for tasks like translation, summarization, or classification, T5 treats all problems as text generation tasks, where both the input and output are sequences of text. This approach simplifies the training process, as a single model can be pre-trained on a vast corpus of text data and then fine-tuned for specific applications with minimal adjustments. T5’s flexibility stems from its encoder-decoder structure, where the encoder processes the input text into a contextualized representation, and the decoder generates the desired output sequence. The model’s pre-training on the C4 dataset—a cleaned and deduplicated version of the Common Crawl—ensures robust generalization across a wide range of linguistic patterns and domains. T5’s architecture is built upon the Transformer, which relies on self-attention mechanisms to capture dependencies between words in a sequence, regardless of their distance. This allows T5 to handle long-range dependencies and contextual nuances effectively. The model’s scalability, from small variants like T5-small to large ones like T5-xxl, enables it to balance computational efficiency with performance, making it suitable for both research and production environments.
#History / Background
The development of T5 was motivated by the growing need for general-purpose NLP models that could adapt to multiple tasks without extensive task-specific engineering. Prior to T5, most NLP models were designed for single-task learning, where a model was trained and optimized for a specific function, such as machine translation or sentiment analysis. This approach was inefficient, as it required separate models, datasets, and training pipelines for each task. Google Research’s T5 project emerged from the observation that many NLP tasks could be reformulated as text-to-text problems. For example:
- Translation: Input = "Hello world", Output = "Hola mundo"
- Summarization: Input = "The quick brown fox jumps over the lazy dog.", Output = "A fox jumps over a dog."
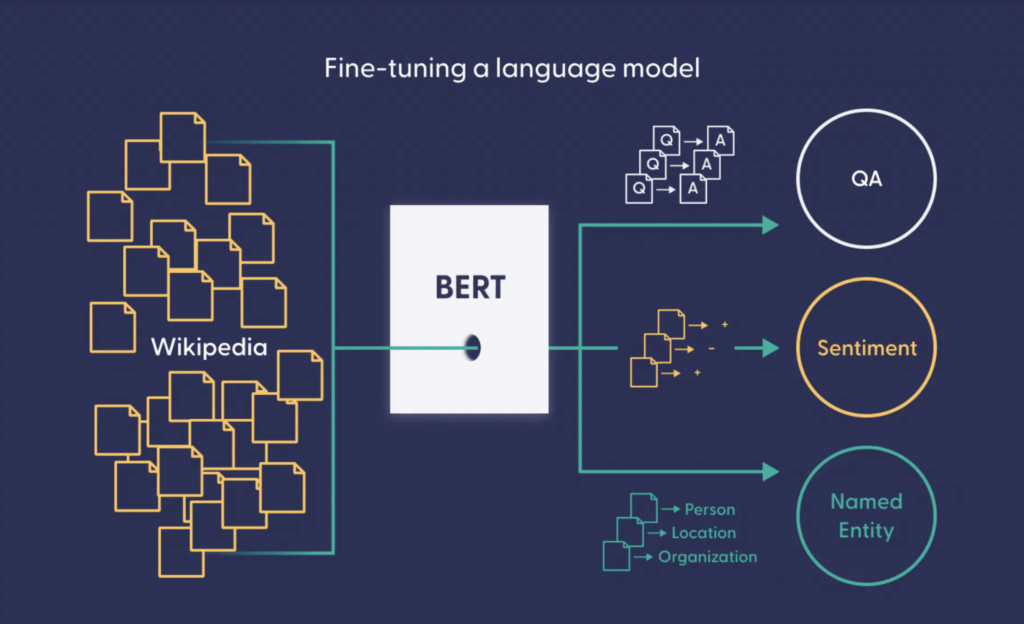
- Classification: Input = "This movie was great!", Output = "Positive" The T5 paper, published in October 2019, demonstrated that a single model could achieve state-of-the-art results across a variety of benchmarks by leveraging transfer learning. The model was pre-trained on the C4 dataset, which contains over 750GB of cleaned English text, and then fine-tuned for specific tasks. This pre-training phase allowed T5 to learn general language patterns, while fine-tuning adapted it to task-specific requirements. Following its initial release, T5 was further refined with larger variants (T5-large, T5-xl, T5-xxl) and extended versions like T5.1.1, which incorporated improvements in training efficiency and performance. The model also inspired derivative works, such as FLAN-T5, which fine-tunes T5 on a collection of instruction-based datasets to enhance its ability to follow natural language instructions.
#How It Works
#Architecture T5 is built on the Transformer architecture, which consists of two main components:
- Encoder: Processes the input text and converts it into a contextualized representation.
- Decoder: Generates the output text based on the encoder’s representation. The encoder is composed of multiple layers of self-attention mechanisms and feed-forward neural networks, which transform the input sequence into a set of hidden states. These hidden states capture the semantic and syntactic relationships between words in the input. The decoder also contains self-attention layers but includes an additional cross-attention mechanism that attends to the encoder’s hidden states. This allows the decoder to generate output sequences that are conditioned on the input. The decoder uses autoregressive generation, where it predicts the next token in the sequence based on the previously generated tokens.
#Pre-training T5 undergoes two main phases of training:
- Pre-training: The model is trained on a large corpus of text data (C4) using self-supervised learning. During this phase, T5 learns to predict missing or corrupted tokens in the input text, a task known as masked language modeling. This helps the model develop a strong understanding of language structure and semantics.
- Fine-tuning: After pre-training, T5 is fine-tuned on specific downstream tasks. For example, if the task is text summarization, the model is trained to generate a summary given an input document. Fine-tuning involves adjusting the model’s weights to optimize performance on the target task.
#Task Formulation T5 reformulates all NLP tasks as text-to-text problems, where both the input and output are sequences of text. This is achieved by:
- Prefixing the input with a task-specific prefix (e.g., "summarize:" for summarization tasks).
- Using the same loss function (cross-entropy loss) for all tasks, which simplifies the training process. For example:
- Translation: Input = "translate English to French: Hello world", Output = "Bonjour le monde"
- Question Answering: Input = "question: What is the capital of France? context: Paris is the capital of France.", Output = "Paris"
#Scaling and Variants T5 is available in multiple sizes, each offering a trade-off between computational efficiency and performance:
- T5-small: 60 million parameters, suitable for lightweight applications.
- T5-base: 220 million parameters, a balance between performance and resource usage.
- T5-large: 770 million parameters, offers improved accuracy for complex tasks.
- T5-xl: 3 billion parameters, designed for high-performance applications.
- T5-xxl: 11 billion parameters, the largest variant, capable of handling highly complex tasks. Larger variants generally achieve better performance but require more computational resources for training and inference.
#Important Facts
- Unified Text-to-Text Framework: T5 treats all NLP tasks as text generation problems, simplifying the training and deployment process.
- Pre-training on C4: The model is pre-trained on the Colossal Clean Crawled Corpus (C4), a high-quality dataset derived from the Common Crawl.
- Scalability: T5 is available in multiple sizes, from T5-small to T5-xxl, allowing users to choose based on their computational constraints.
- State-of-the-Art Performance: T5 has achieved state-of-the-art results on several NLP benchmarks, including GLUE, SuperGLUE, and SQuAD.
- Fine-Tuning Flexibility: T5 can be fine-tuned for a wide range of tasks with minimal modifications, making it highly adaptable.
- Multilingual Capabilities: While primarily trained on English data, T5 has been extended to support multilingual tasks through variants like mT5.
- Open-Source: T5 is released under the Apache License 2.0, allowing for widespread adoption and modification.
- Inspiration for Derivative Models: T5 has inspired derivative works like FLAN-T5, which fine-tunes the model on instruction-based datasets to improve its ability to follow natural language instructions.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a T5 Model?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a T5 Model? cover?
Explains What Is a T5 Model, including the core definition, how it works, practical examples, and limitations.
Why is What Is a T5 Model? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as T5, Model, AI before using the ideas in real projects.
#References
- What Is a T5 Model? terminology and background research
- What Is a T5 Model? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- T5 case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.