#Short Answer
Explains What Is a Neural Network Layer, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
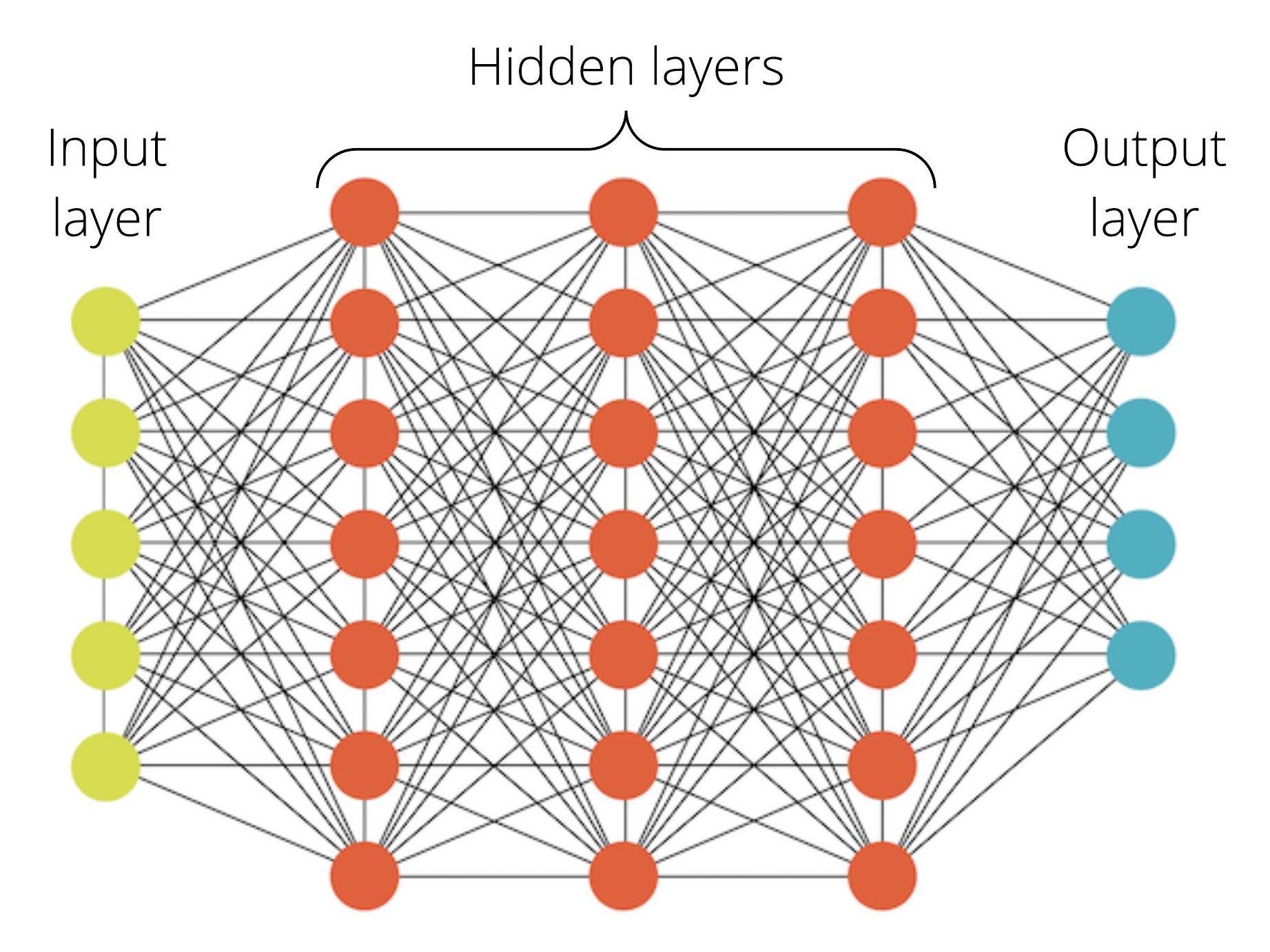
A neural network layer is a structured arrangement of artificial neurons designed to process input data in a sequential or parallel manner. Each layer performs a specific transformation, enabling the network to learn hierarchical representations of data. The architecture of a neural network—comprising multiple layers—determines its ability to model complex relationships in data. Neural network layers are inspired by biological neural networks, where neurons communicate via electrical signals. In artificial neural networks, layers act as computational units that apply mathematical operations to input data, passing the transformed output to subsequent layers. This hierarchical processing allows neural networks to approximate highly non-linear functions, making them powerful tools for tasks such as classification, regression, and pattern recognition. The design of a neural network layer depends on its role within the network:
- Input layers receive raw data and pass it to hidden layers.
- Hidden layers perform intermediate computations, extracting features and patterns.
- Output layers produce the final prediction or classification. The depth and width of a neural network (number of layers and neurons per layer) influence its capacity to learn from data. Deeper networks can model more complex relationships but require more computational resources and larger datasets to train effectively.
#History / Background
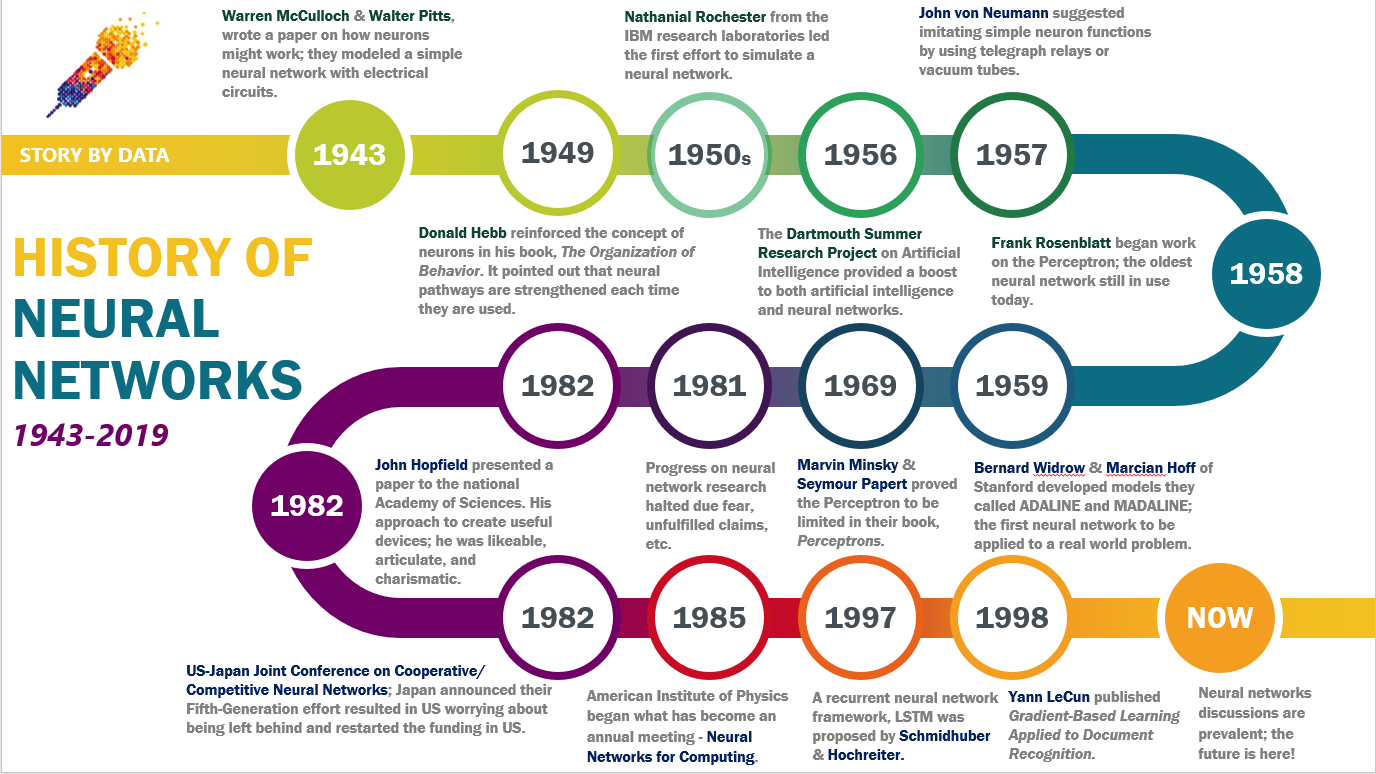
The concept of neural network layers emerged from early research in artificial intelligence and neuroscience. The foundational ideas were laid in the mid-20th century, with key milestones shaping the development of modern neural networks:
- 1943: McCulloch-Pitts Neuron Warren McCulloch and Walter Pitts introduced the first mathematical model of a neuron, laying the groundwork for artificial neural networks. Their work demonstrated that simple logical operations could be performed by interconnected neurons.
- 1958: Perceptron Frank Rosenblatt developed the Perceptron, the first trainable neural network model. The Perceptron consisted of a single layer of neurons with adjustable weights, capable of learning linear decision boundaries. However, its limitations in handling non-linear problems became apparent.
- 1969: The XOR Problem Marvin Minsky and Seymour Papert highlighted the Perceptron’s inability to solve the XOR problem, a simple non-linear classification task. This critique slowed research in neural networks for over a decade, as single-layer networks were deemed insufficient for complex tasks.
- 1986: Backpropagation and Multilayer Networks The resurgence of neural networks began with the popularization of backpropagation, an algorithm for training multilayer networks. Geoffrey Hinton, David Rumelhart, and Ronald Williams demonstrated that hidden layers could learn useful representations, enabling neural networks to tackle non-linear problems.
- 1990s–2000s: Deep Learning Emergence Advances in computational power and the availability of large datasets led to the development of deep neural networks with many hidden layers. Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) became prominent for tasks like image and speech recognition.
- 2010s–Present: Modern Neural Networks The rise of deep learning frameworks (e.g., TensorFlow, PyTorch) and hardware accelerators (e.g., GPUs, TPUs) enabled the training of extremely deep networks. Innovations such as residual connections, attention mechanisms, and transformer architectures further expanded the capabilities of neural network layers.
#How It Works
#Structure of a Neural Network Layer A neural network layer consists of the following key components:
- Neurons (Nodes) Each neuron in a layer receives input from the previous layer (or raw data, in the case of an input layer) and produces an output. A neuron applies a weighted sum of its inputs, adds a bias term, and passes the result through an activation function.
- Weights and Biases
- Weights determine the strength of the connection between neurons in adjacent layers. They are learned during training via optimization algorithms like gradient descent.
- Biases shift the activation function, allowing the neuron to fit the data more flexibly.
- Activation Functions Activation functions introduce non-linearity into the network, enabling it to learn complex patterns. Common activation functions include:
- ReLU (Rectified Linear Unit): Outputs the input directly if positive; otherwise, it outputs zero.
- Sigmoid: Maps inputs to a range between 0 and 1, useful for binary classification.
- Tanh: Maps inputs to a range between -1 and 1, providing stronger gradients than sigmoid.
- Softmax: Converts outputs into probabilities, often used in multi-class classification.
- Forward Propagation During forward propagation, data flows through the network layer by layer. Each layer’s output becomes the input for the next layer. The final layer’s output is compared to the true label (in supervised learning) to compute a loss function, which measures the network’s performance.
- Backpropagation Backpropagation is the algorithm used to train neural networks. It calculates the gradient of the loss function with respect to each weight in the network, using the chain rule of calculus. These gradients are then used to update the weights via optimization algorithms (e.g., stochastic gradient descent, Adam) to minimize the loss.
#Types of Neural Network Layers
- Input Layer - The first layer in a neural network, responsible for receiving raw input data. - Each neuron in the input layer corresponds to a feature in the dataset (e.g., pixel values in an image, word embeddings in text).
- Hidden Layer - Intermediate layers between the input and output layers. - Perform feature extraction and transformation. Hidden layers can be:
- Fully Connected (Dense): Each neuron is connected to every neuron in the previous layer.
- Convolutional: Used in CNNs for spatial data (e.g., images), applying filters to detect local patterns.
- Recurrent: Used in RNNs for sequential data (e.g., time series, text), where neurons have loops to maintain memory.
- Pooling: Reduces the spatial dimensions of data (e.g., max pooling, average pooling) to decrease computational load and control overfitting.
- Output Layer - The final layer, producing the network’s prediction or classification. - The number of neurons in the output layer depends on the task:
- Regression: Single neuron (continuous output).
- Binary Classification: Single neuron with sigmoid activation.
- Multi-class Classification: Multiple neurons with softmax activation.
#Important Facts
- Universal Approximation Theorem A neural network with a single hidden layer containing a finite number of neurons can approximate any continuous function, given appropriate weights. This theorem underscores the power of neural networks in function approximation.
- Curse of Dimensionality As the number of layers and neurons increases, the computational complexity and data requirements grow exponentially. Techniques like regularization, dropout, and batch normalization help mitigate this issue.
- Overfitting and Underfitting
- Overfitting: Occurs when a neural network learns noise in the training data, performing poorly on unseen data. Regularization techniques (e.g., L1/L2 regularization, dropout) are used to prevent overfitting.
- Underfitting: Occurs when the network is too simple to capture the underlying patterns in the data. Increasing the network’s depth or width can address underfitting.
- Transfer Learning Pre-trained neural networks (e.g., ResNet, BERT) can be fine-tuned for specific tasks, reducing the need for large labeled datasets. This approach leverages knowledge from related domains to improve performance.
- Hyperparameters Key hyperparameters that influence layer performance include:
- Learning Rate: Controls the step size during weight updates.
- Batch Size: Number of samples processed before updating weights.
- Number of Layers and Neurons: Determines the network’s capacity.
- Activation Functions: Affects the network’s non-linearity and training dynamics.
- Hardware Acceleration Neural network layers benefit from parallel processing on GPUs and TPUs, significantly speeding up training and inference. Frameworks like TensorFlow and PyTorch optimize computations for these hardware platforms.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a Neural Network Layer?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a Neural Network Layer? cover?
Explains What Is a Neural Network Layer, including the core definition, how it works, practical examples, and limitations.
Why is What Is a Neural Network Layer? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Neural, Network, Layer before using the ideas in real projects.
#References
- What Is a Neural Network Layer? terminology and background research
- What Is a Neural Network Layer? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Neural case studies, benchmarks, and current industry analysis

.png?1678746405)
Comments
No comments yet. Start the discussion with a useful note.