
#Short Answer
Covers step-by-step guide to training a neural network, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Training a neural network is a fundamental process in deep learning, enabling machines to learn from data and make predictions or decisions without explicit programming. Neural networks, inspired by the human brain, consist of interconnected layers of nodes (neurons) that process input data through weighted connections. The training process involves iteratively adjusting these weights to minimize the difference between predicted outputs and actual values, a concept known as minimizing the loss function. Neural networks excel in tasks such as image classification, speech recognition, and natural language processing due to their ability to model complex, non-linear relationships. However, successful training requires careful consideration of data quality, model architecture, hyperparameters, and computational resources.
#History / Background
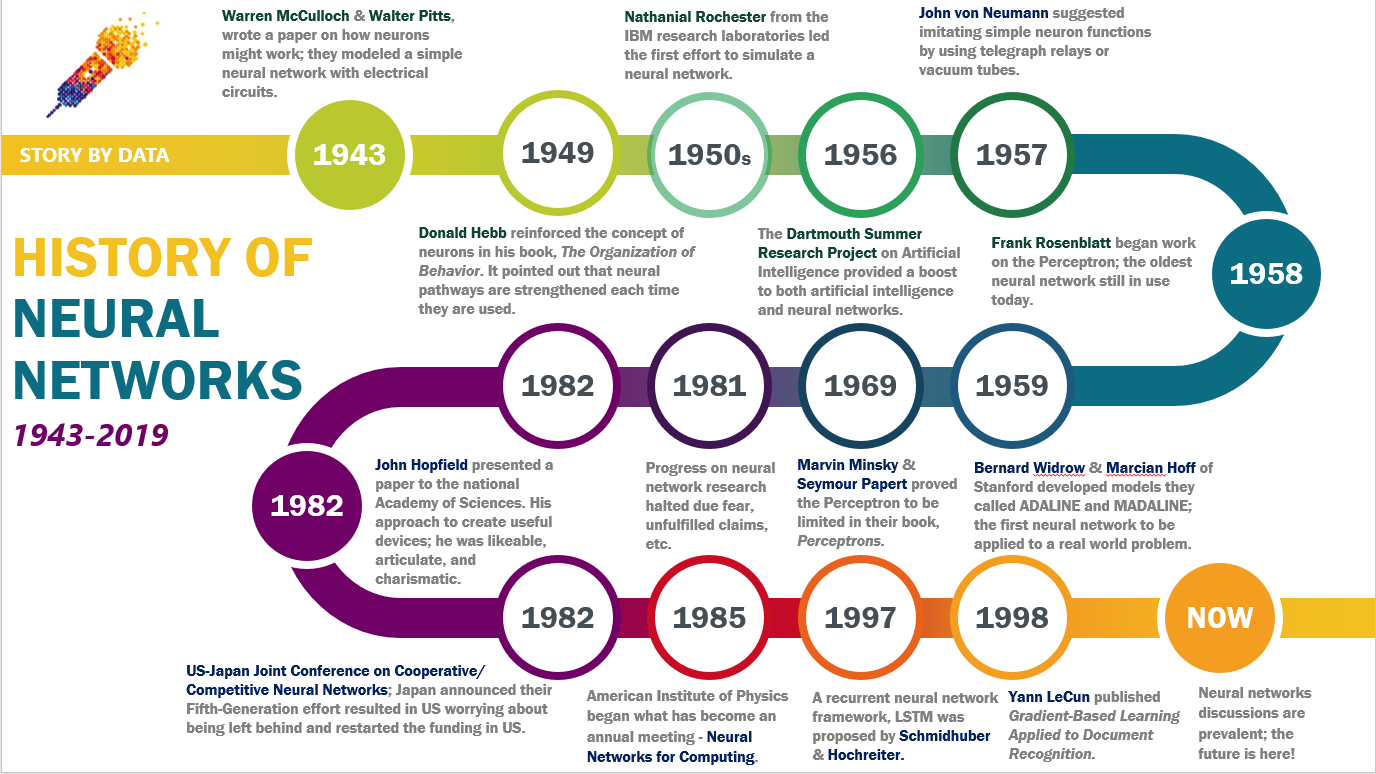
The concept of neural networks dates back to the 1940s, with early work by Warren McCulloch and Walter Pitts on artificial neurons. The first practical implementation, the perceptron, was introduced by Frank Rosenblatt in 1958, demonstrating the ability to learn linear decision boundaries. However, limitations in computational power and the lack of efficient training algorithms led to a decline in interest during the 1970s, known as the "AI Winter." The resurgence of neural networks began in the 1980s with the development of the backpropagation algorithm, which enabled efficient training of multi-layer networks. Geoffrey Hinton’s work in the 2000s further advanced the field by introducing deep belief networks and overcoming challenges like vanishing gradients. The breakthrough came in 2012 when a deep convolutional neural network (CNN), AlexNet, won the ImageNet competition, showcasing the power of deep learning. Since then, neural networks have become a cornerstone of artificial intelligence, with applications ranging from healthcare diagnostics to autonomous vehicles. Advances in hardware (e.g., GPUs and TPUs) and optimization techniques have accelerated training speeds and improved model performance.
#How It Works
#
- Data Preparation Training a neural network begins with data collection and preprocessing. Data must be cleaned, normalized, and split into training, validation, and test sets. Techniques like feature scaling, one-hot encoding, and data augmentation (for images/text) are commonly used to improve model performance.
#
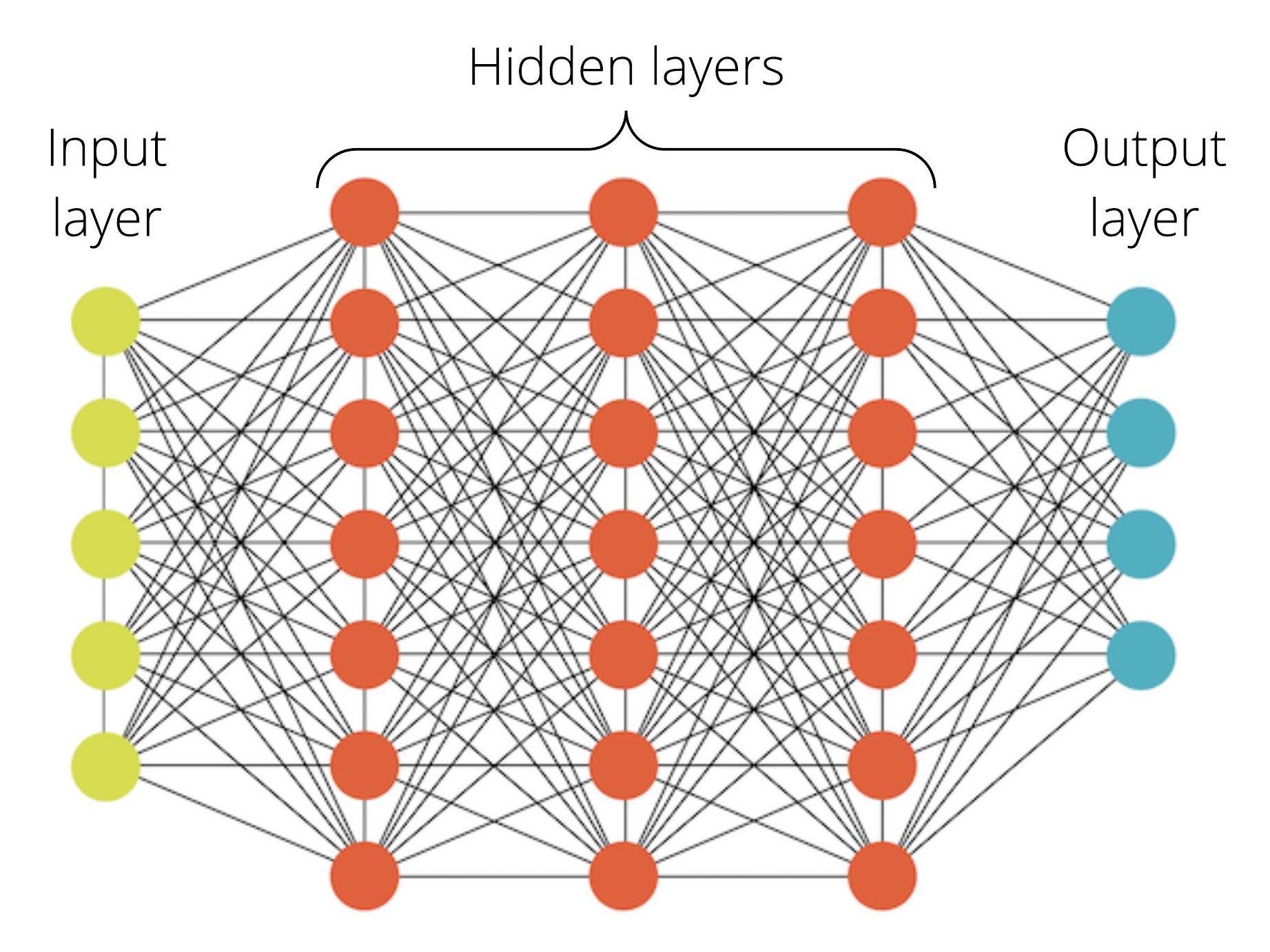
- Model Architecture The architecture of a neural network defines its structure, including:
- Input Layer: Receives the raw data (e.g., pixels for images, words for text).
- Hidden Layers: Intermediate layers where computations occur. Common types include:
- Fully Connected (Dense) Layers: Each neuron connects to every neuron in the next layer.
- Convolutional Layers (CNNs): Used for spatial data like images, applying filters to detect features.
- Recurrent Layers (RNNs/LSTMs): Process sequential data (e.g., time series, text).
- Output Layer: Produces the final prediction (e.g., class probabilities for classification).
#
- Initialization Weights and biases are initialized randomly (e.g., using Xavier or He initialization) to break symmetry and enable learning. Poor initialization can lead to slow convergence or failure to train.
#
- Forward Propagation The input data is passed through the network layer by layer. At each neuron, the weighted sum of inputs is computed, followed by an activation function (e.g., ReLU, Sigmoid, Tanh) to introduce non-linearity. The output layer’s result is compared to the true label using a loss function (e.g., Mean Squared Error for regression, Cross-Entropy for classification).
#
- Backpropagation The core training mechanism, backpropagation, calculates the gradient of the loss function with respect to each weight using the chain rule of calculus. This gradient indicates how much each weight contributed to the error, guiding adjustments to minimize loss.
#
- Optimization Gradients are used by an optimizer (e.g., Stochastic Gradient Descent (SGD), Adam, RMSprop) to update weights. Key hyperparameters include:
- Learning Rate: Controls the size of weight updates. Too high causes divergence; too low slows training.
- Batch Size: Number of samples processed before updating weights (e.g., mini-batch gradient descent).
- Epochs: Number of passes through the entire dataset.
#
- Evaluation and Validation After training, the model is evaluated on the validation set to tune hyperparameters and prevent overfitting. Metrics like accuracy, precision, recall, and F1-score are used for classification, while Mean Absolute Error (MAE) or R² are used for regression.
#
- Deployment Once validated, the trained model is deployed to make predictions on new, unseen data. Continuous monitoring and retraining may be required to maintain performance as data distributions change.
#Important Facts
- Universal Approximation Theorem: A neural network with at least one hidden layer can approximate any continuous function, given sufficient neurons and proper training.
- Overfitting vs. Underfitting:
- Overfitting: Model memorizes training data but performs poorly on new data. Mitigated by techniques like dropout, regularization (L1/L2), or early stopping.
- Underfitting: Model fails to capture underlying patterns. Addressed by increasing model complexity or training longer.
- Vanishing/Exploding Gradients: Common in deep networks, where gradients become too small (vanishing) or too large (exploding), hindering learning. Solutions include batch normalization, gradient clipping, or residual connections.
- Transfer Learning: Leveraging pre-trained models (e.g., ResNet, BERT) to fine-tune on specific tasks, reducing training time and data requirements.
- Hardware Acceleration: GPUs and TPUs significantly speed up training by parallelizing computations across thousands of cores.
#Timeline
- Foundational ideas
Core concepts and early methods shape Step-by-step Guide to Training a Neural Network.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Step-by-step Guide to Training a Neural Network cover?
Covers step-by-step guide to training a neural network, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Step-by-step Guide to Training a Neural Network important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Training, Neural, Network before using the ideas in real projects.
#References
- Step-by-step Guide to Training a Neural Network terminology and background research
- Step-by-step Guide to Training a Neural Network use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Training case studies, benchmarks, and current industry analysis
.png?1678746405)
Comments
No comments yet. Start the discussion with a useful note.