
#Short Answer
Covers understanding neural networks: a comprehensive guide, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Neural networks are a cornerstone of modern artificial intelligence (AI) and machine learning, enabling systems to learn from data and improve over time without explicit programming. Unlike traditional algorithms, which follow predefined rules, neural networks adapt their internal parameters (weights) based on input data, allowing them to generalize patterns and make predictions on unseen data. Their architecture mimics the brain’s interconnected neurons, where information flows through layers of nodes, each performing simple computations before passing results to the next layer. The versatility of neural networks has led to breakthroughs in fields such as computer vision, where they excel at identifying objects in images, and natural language processing (NLP), where they power chatbots and translation services. Their ability to handle large-scale, unstructured data—such as text, audio, and video—has made them indispensable in industries ranging from healthcare to finance.
#History / Background
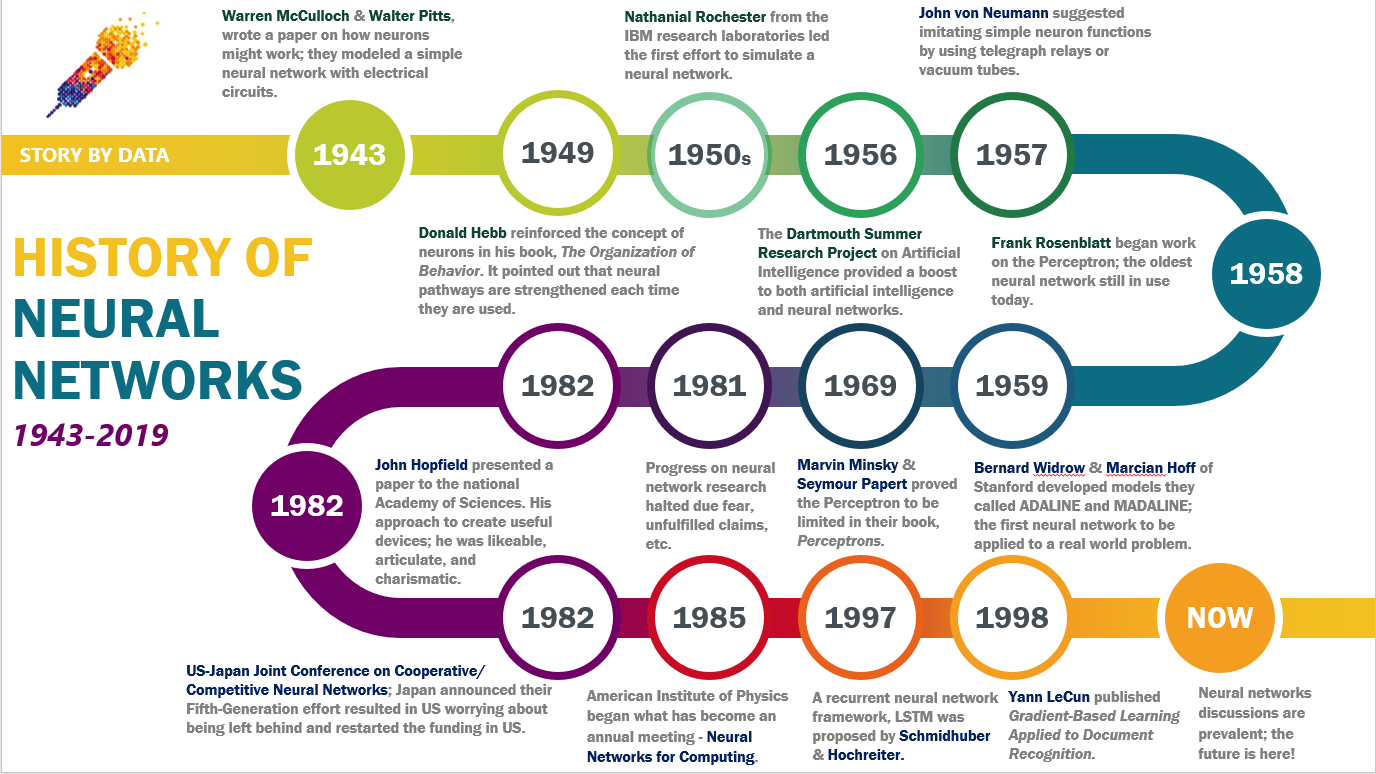
#Early Foundations (1940s–1960s)
The concept of neural networks traces back to the 1940s, when neurophysiologist Warren McCulloch and mathematician Walter Pitts proposed the first mathematical model of an artificial neuron in 1943. Their work, inspired by biological neurons, laid the groundwork for understanding how simple logical operations could be performed by interconnected nodes. In 1958, psychologist Frank Rosenblatt developed the Perceptron, the first functional neural network model capable of learning. The Perceptron could classify linearly separable data, though its limitations—such as the inability to solve non-linear problems—were later highlighted by Marvin Minsky and Seymour Papert in their 1969 book Perceptrons. This critique temporarily stalled research in the field.
#Revival and Modernization (1980s–1990s)
The 1980s saw a resurgence in neural network research, driven by advances in computing power and the development of new algorithms. Key milestones included:
- Backpropagation (1986): Introduced by David Rumelhart, Geoffrey Hinton, and Ronald Williams, this algorithm enabled neural networks to learn from errors by adjusting weights in reverse, significantly improving training efficiency.
- Multilayer Perceptrons (MLPs): These networks, with multiple hidden layers, could model complex non-linear relationships, overcoming the limitations of single-layer Perceptrons. Despite these advances, neural networks faced challenges, including slow training times and the lack of large datasets. The field experienced another decline in the late 1990s as support vector machines (SVMs) and other methods gained popularity.
#Deep Learning Era (2000s–Present)
The 2000s marked a turning point with the advent of deep learning, a subset of neural networks characterized by multiple hidden layers (hence "deep"). Critical developments included:
- ImageNet Competition (2012): A convolutional neural network (CNN) called AlexNet, developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, achieved unprecedented accuracy in image classification, sparking widespread interest in deep learning.
- GPU Acceleration: The use of graphics processing units (GPUs) for parallel computation drastically reduced training times, enabling the training of larger and more complex models.
- Transformers (2017): Introduced in the paper Attention Is All You Need by Vaswani et al., Transformers revolutionized NLP by replacing recurrent layers with self-attention mechanisms, leading to models like BERT and GPT. Today, neural networks underpin many state-of-the-art AI systems, from self-driving cars to generative AI tools like DALL·E and Stable Diffusion.
#How It Works
#Basic Architecture A neural network consists of three primary layers:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence) and passes it to the next layer.
- Hidden Layers: Intermediate layers where computations occur. Each hidden layer applies transformations to the input using weights and biases, followed by an activation function to introduce non-linearity.
- Output Layer: Produces the final prediction or classification (e.g., identifying a cat in an image or translating a sentence).
#Key Components
- Weights and Biases: Parameters that the network learns during training. Weights determine the strength of connections between neurons, while biases allow shifting the activation function.
- Activation Functions: Non-linear functions (e.g., ReLU, sigmoid, tanh) applied to neuron outputs to enable complex mappings. ReLU (Rectified Linear Unit) is commonly used in hidden layers due to its simplicity and effectiveness.
- Loss Function: Measures the difference between predicted and actual outputs (e.g., mean squared error for regression, cross-entropy for classification). The goal during training is to minimize this loss.
- Optimization Algorithm: Adjusts weights to reduce loss. Common methods include Stochastic Gradient Descent (SGD), Adam, and RMSprop.
#Training Process
- Forward Propagation: Input data is passed through the network, and predictions are generated.
- Loss Calculation: The loss function quantifies the error between predictions and true labels.
- Backpropagation: The gradient of the loss with respect to each weight is computed using the chain rule, and weights are updated to reduce the loss.
- Iteration: Steps 1–3 repeat over multiple epochs (training cycles) until the model converges to a satisfactory performance.
#Types of Neural Networks
- Feedforward Neural Networks (FNNs): Data flows in one direction (input → hidden → output). Used for tasks like classification and regression.
- Convolutional Neural Networks (CNNs): Specialized for grid-like data (e.g., images) using convolutional layers to detect spatial hierarchies.
- Recurrent Neural Networks (RNNs): Designed for sequential data (e.g., time series, text) with loops that allow information to persist. Variants include LSTMs (Long Short-Term Memory) and GRUs (Gated Recurrent Units).
- Transformers: Rely on self-attention mechanisms to weigh the importance of different parts of the input, excelling in NLP and other sequence tasks.
#Important Facts
- Universal Approximation Theorem: A neural network with a single hidden layer containing a finite number of neurons can approximate any continuous function, given appropriate weights. This theoretical foundation justifies their use in complex tasks.
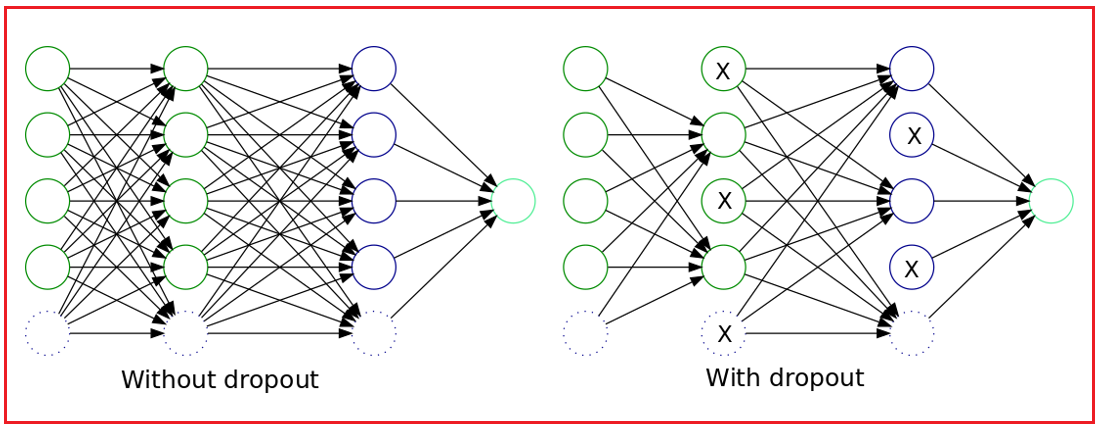
- Overfitting: Neural networks can memorize training data instead of generalizing, leading to poor performance on unseen data. Techniques like dropout (randomly deactivating neurons during training) and regularization (penalizing large weights) mitigate this.
- Transfer Learning: Pre-trained models (e.g., ResNet for images, BERT for text) can be fine-tuned for specific tasks, reducing the need for large labeled datasets.
- Hardware Requirements: Training large neural networks often requires specialized hardware like GPUs or TPUs (Tensor Processing Units) due to the computational intensity of matrix operations.
- Ethical Concerns: Neural networks can inherit biases present in training data, leading to unfair or discriminatory outcomes. Addressing these issues is an active area of research in AI ethics.
#Timeline
- Foundational ideas
Core concepts and early methods shape Understanding Neural Networks: a Comprehensive Guide.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Understanding Neural Networks: a Comprehensive Guide cover?
Covers understanding neural networks: a comprehensive guide, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Understanding Neural Networks: a Comprehensive Guide important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Understanding, Neural, Networks before using the ideas in real projects.
#References
- Understanding Neural Networks: a Comprehensive Guide terminology and background research
- Understanding Neural Networks: a Comprehensive Guide use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Understanding case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.