#Short Answer
Covers the science behind deep learning, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
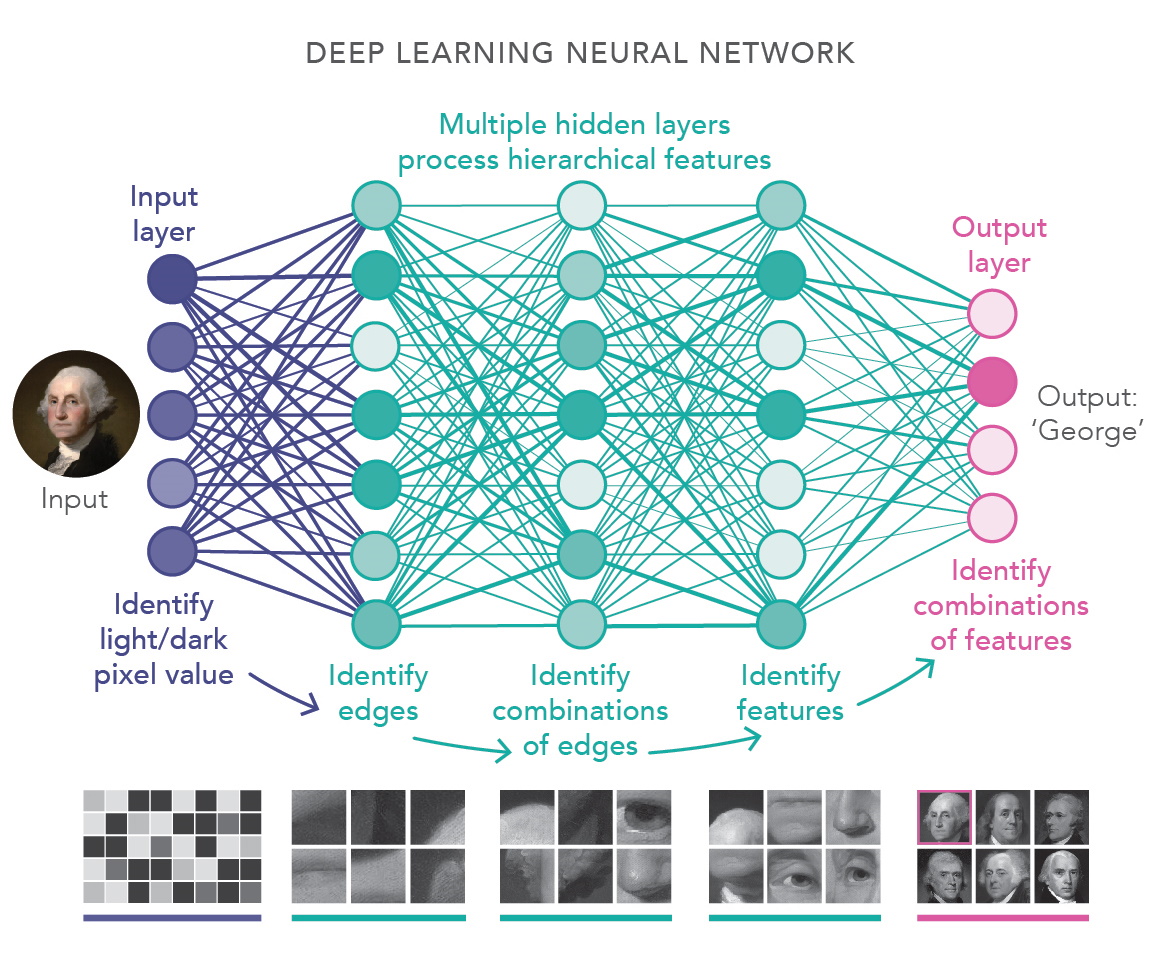
Deep learning is a transformative branch of artificial intelligence (AI) that enables machines to learn from vast amounts of data by mimicking the structure and function of the human brain. Unlike traditional machine learning, which relies on handcrafted features, deep learning automatically extracts relevant features from raw data through layered neural networks. This capability has led to breakthroughs in fields such as computer vision, natural language processing (NLP), and robotics. The core idea behind deep learning is the artificial neural network (ANN), which consists of interconnected nodes (neurons) organized into layers. These layers—input, hidden, and output—work together to process and transform data, progressively refining it into meaningful representations. The "deep" in deep learning refers to the multiple hidden layers between the input and output, which allow the network to learn intricate patterns.
#History / Background
#Early Foundations (1940s–1980s)
The theoretical groundwork for deep learning was laid in the mid-20th century. In 1943, Warren McCulloch and Walter Pitts proposed the first mathematical model of a neuron, inspired by biological neural networks. This work laid the foundation for artificial neural networks. In 1958, Frank Rosenblatt developed the Perceptron, a simple neural network model capable of binary classification. However, early limitations, such as the inability to solve non-linear problems, led to a decline in interest during the 1970s.
#Revival and Challenges (1980s–2000s)
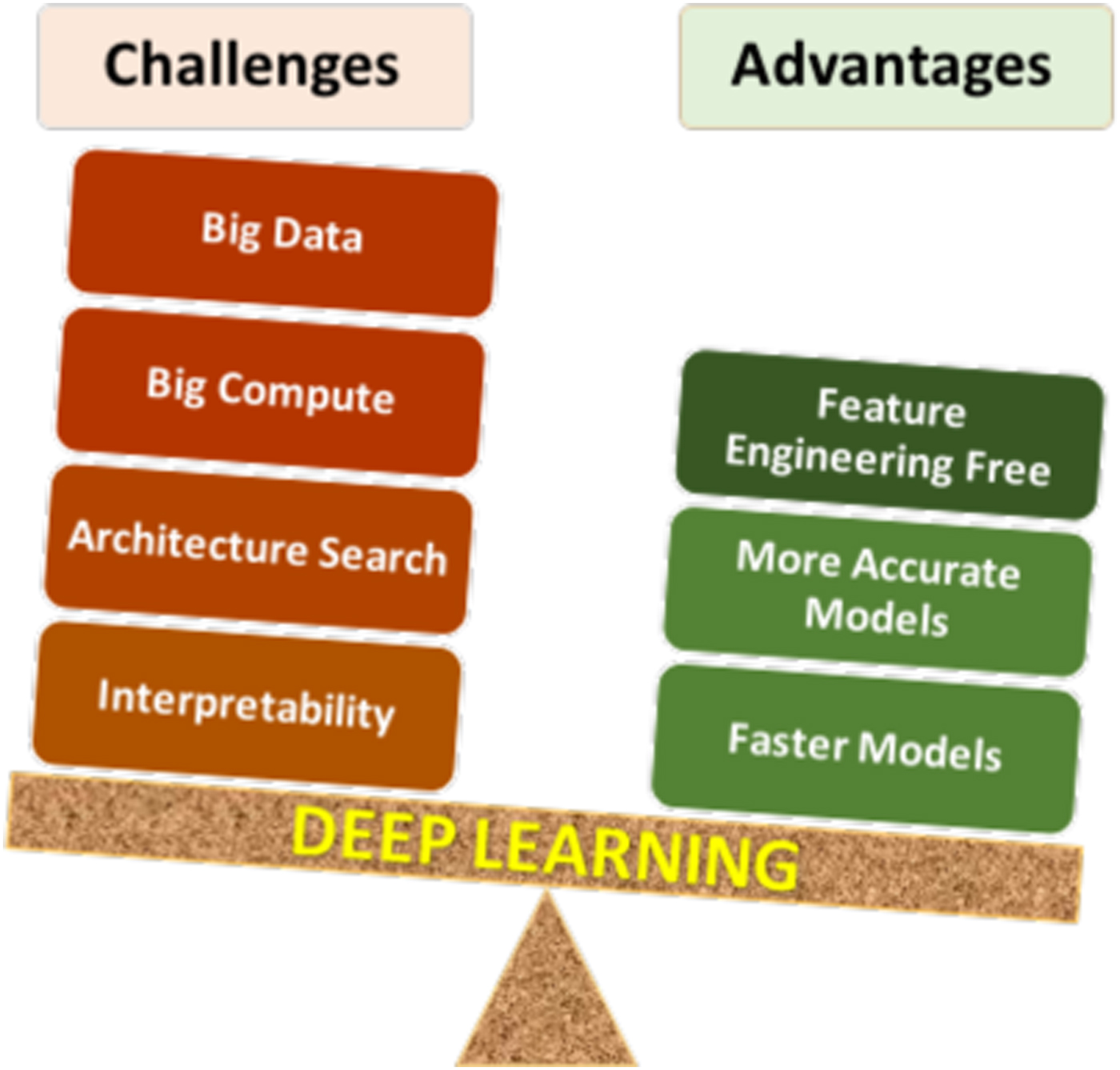
The 1980s saw a resurgence of interest in neural networks with the introduction of the backpropagation algorithm by Geoffrey Hinton, David Rumelhart, and Ronald Williams. This method enabled neural networks to learn from errors by adjusting weights through gradient descent. Around the same time, convolutional neural networks (CNNs) were introduced by Yann LeCun, which revolutionized image recognition tasks. Despite these advances, deep learning faced significant challenges, including:
- Vanishing gradient problem: Gradients in deep networks became too small during backpropagation, hindering learning in early layers.
- Computational limitations: Training deep networks required immense computational power, which was not widely available.
- Lack of large datasets: Deep learning thrives on big data, which was scarce before the digital age.
#The Deep Learning Revolution (2010s–Present)
The breakthrough came in the 2010s, driven by three key factors:
- Big Data: The explosion of digital data from sources like social media, sensors, and the internet provided the raw material for training deep networks.
- Computational Power: The advent of GPUs (Graphics Processing Units) and later TPUs (Tensor Processing Units) enabled efficient parallel processing, drastically reducing training times.
- Algorithmic Improvements: Innovations such as rectified linear units (ReLUs), dropout, and batch normalization addressed training challenges and improved model performance. Landmark achievements include:
- 2012: AlexNet, a CNN developed by Alex Krizhevsky, won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), achieving unprecedented accuracy in image classification.
- 2016: AlphaGo, developed by DeepMind, defeated the world champion Go player, demonstrating the power of deep reinforcement learning.
- 2020s: Deep learning models like GPT-3 and DALL-E showcased capabilities in generating human-like text and images, respectively.
#How It Works
#Neural Networks: The Building Blocks At the heart of deep learning are artificial neural networks (ANNs), which consist of interconnected layers of neurons. Each neuron applies a mathematical operation to its inputs, typically involving: - A weighted sum of inputs. - An activation function (e.g., ReLU, sigmoid, tanh) to introduce non-linearity. - An output passed to the next layer.
#Types of Neural Networks
- Feedforward Neural Networks (FNNs): The simplest form, where data flows in one direction from input to output. Used for tasks like classification and regression.
- Convolutional Neural Networks (CNNs): Designed for spatial data (e.g., images), using convolutional layers to detect local patterns like edges and textures.
- Recurrent Neural Networks (RNNs): Process sequential data (e.g., time series, text) by maintaining a "memory" of previous inputs via recurrent connections. Variants like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs) mitigate the vanishing gradient problem.
- Transformer Networks: Introduced in the 2017 paper "Attention Is All You Need", transformers use self-attention mechanisms to weigh the importance of different parts of the input, enabling superior performance in NLP tasks (e.g., BERT, GPT).
#Training Deep Learning Models Training involves the following steps:
- Data Preparation: Raw data is preprocessed (e.g., normalization, augmentation) and split into training, validation, and test sets.
- Forward Propagation: Input data is passed through the network, and predictions are generated.
- Loss Calculation: A loss function (e.g., cross-entropy for classification, mean squared error for regression) quantifies the difference between predictions and actual labels.
- Backpropagation: The network calculates gradients of the loss with respect to each weight using the chain rule and updates weights via optimization algorithms like Stochastic Gradient Descent (SGD), Adam, or RMSprop.
- Iteration: Steps 2–4 are repeated over multiple epochs until the model converges (i.e., loss stabilizes).
#Key Techniques
- Regularization: Techniques like dropout (randomly deactivating neurons during training) and weight decay (L2 regularization) prevent overfitting.
- Batch Normalization: Normalizes layer inputs to stabilize and accelerate training.
- Transfer Learning: Leverages pre-trained models (e.g., ResNet, BERT) for new tasks, reducing the need for large datasets.
#Important Facts
- Hierarchical Feature Learning: Deep learning models learn features hierarchically—lower layers detect simple patterns (e.g., edges in images), while higher layers capture complex abstractions (e.g., object parts or entire objects).
- Universal Approximation Theorem: A neural network with a single hidden layer can approximate any continuous function, given sufficient neurons. Deep networks extend this capability with fewer parameters.
- Data Hunger: Deep learning models often require millions to billions of labeled examples to achieve high performance, unlike humans, who can learn from few examples.
- Black Box Nature: Despite their power, deep learning models are often opaque, making it challenging to interpret how they arrive at decisions. Techniques like SHAP values and LIME aim to address this.
- Hardware Dependency: Training deep models relies heavily on GPUs/TPUs and distributed computing (e.g., cloud platforms like AWS, Google Cloud).
- Ethical Concerns: Deep learning raises issues like bias in training data, privacy violations, and misuse in deepfakes or autonomous weapons.
#Timeline
- Foundational ideas
Core concepts and early methods shape The Science Behind Deep Learning.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does The Science Behind Deep Learning cover?
Covers the science behind deep learning, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is The Science Behind Deep Learning important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Science, Behind, Deep before using the ideas in real projects.
#References
- The Science Behind Deep Learning terminology and background research
- The Science Behind Deep Learning use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Science case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.