
#Short Answer
Explains how deep learning is changing the world, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
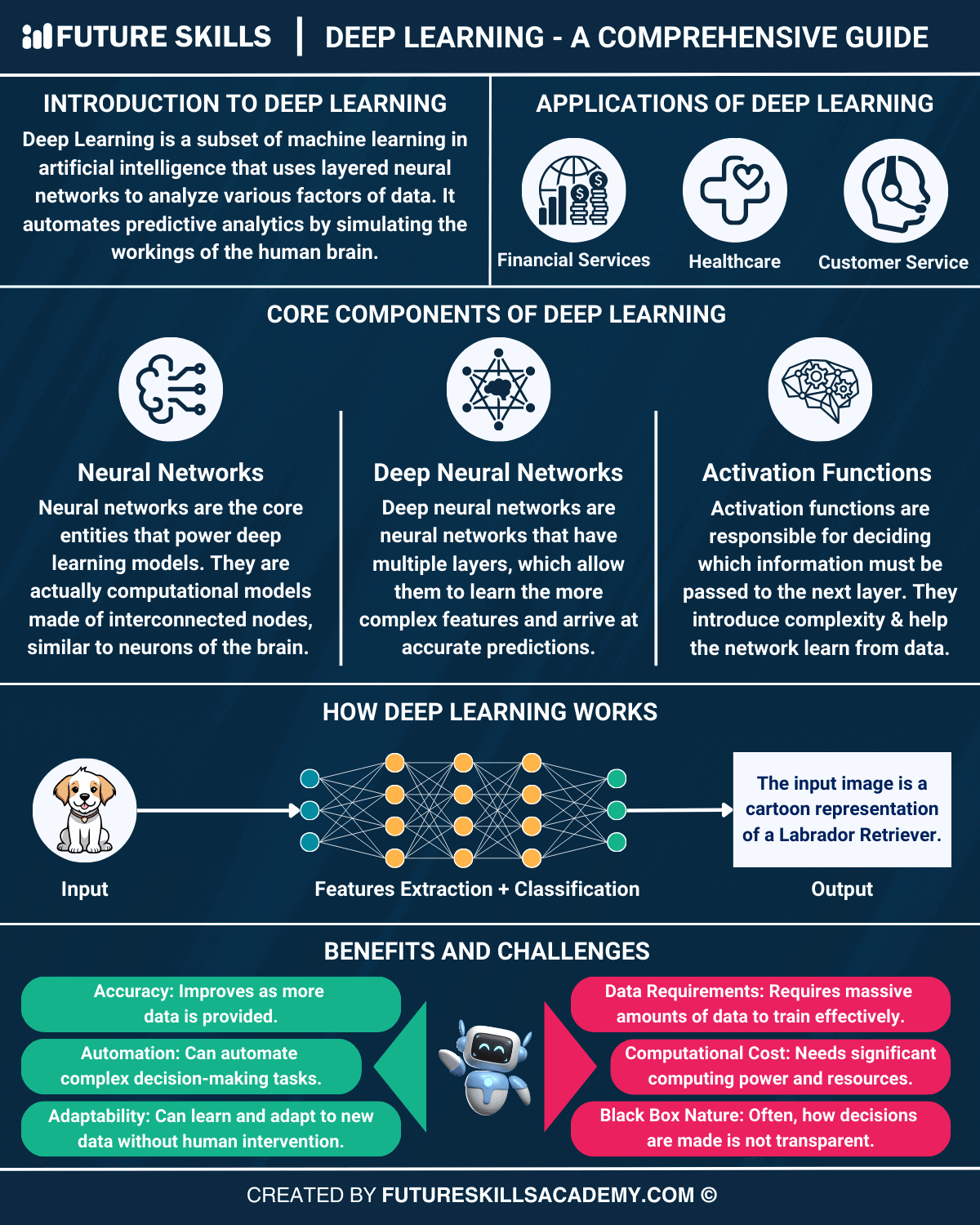
Deep learning represents a paradigm shift in artificial intelligence (AI), enabling machines to learn from data in ways that mimic the human brain's neural architecture. Unlike traditional machine learning, which relies on handcrafted features, deep learning models automatically extract hierarchical representations from raw data through multiple layers of interconnected nodes (neurons). This capability has unlocked unprecedented progress in fields where pattern recognition and decision-making are critical. The foundational idea behind deep learning is the artificial neural network (ANN), inspired by biological neural networks. These networks consist of an input layer, multiple hidden layers, and an output layer. Each layer processes data and passes it to the next, progressively refining the information. The depth of these networks allows them to learn intricate features—such as edges in images or syntactic structures in text—without explicit programming. Deep learning has become a cornerstone of modern AI due to its scalability and adaptability. It thrives on large datasets and high-performance computing, making it feasible to train models that were once computationally infeasible. As a result, deep learning has permeated nearly every sector, from healthcare diagnostics to financial forecasting, reshaping how humans interact with technology.
#History / Background
#Early Foundations (1940s–1980s)
The conceptual roots of deep learning trace back to the mid-20th century. In 1943, Warren McCulloch and Walter Pitts proposed a mathematical model of artificial neurons, laying the groundwork for neural networks. Frank Rosenblatt’s Perceptron (1958) was one of the first implementations of a neural network, capable of learning simple patterns. However, limitations in computational power and the lack of effective training algorithms restricted progress during this era.
#The First AI Winter (1980s–1990s)
Interest in neural networks waned during the 1980s and 1990s due to the Perceptron’s inability to solve non-linear problems and the rise of symbolic AI approaches. Research stagnated until the introduction of backpropagation by Geoffrey Hinton in 1986, which enabled multi-layer networks to learn from errors. Despite this, practical applications remained limited by hardware constraints and insufficient data.
#The Revival (2000s)
The resurgence of deep learning began in the early 2000s, driven by three key factors:
- Increased Computing Power: The advent of graphics processing units (GPUs) accelerated matrix operations essential for training neural networks.
- Big Data: The proliferation of digital data (e.g., images, text, sensor readings) provided the raw material for training robust models.
- Algorithmic Advances: Breakthroughs such as the rectified linear unit (ReLU) activation function and dropout regularization improved training efficiency and model generalization. In 2012, a convolutional neural network (CNN) named AlexNet won the ImageNet Large Scale Visual Recognition Challenge, achieving a top-5 error rate of 15.3%—a significant improvement over traditional methods. This milestone marked the beginning of deep learning’s dominance in computer vision.
#Modern Era
(2010s–Present)
Since 2012, deep learning has expanded into diverse domains:
- Natural Language Processing (NLP): Models like Word2Vec (2013) and later Transformer architectures (e.g., BERT, 2018) revolutionized language understanding.
- Speech Recognition: Systems like DeepMind’s WaveNet (2016) achieved near-human accuracy in generating synthetic speech.
- Autonomous Systems: Companies like Tesla and Waymo leveraged deep learning for self-driving cars, using CNNs and recurrent networks to process sensor data.
- Healthcare: Deep learning models now assist in medical imaging (e.g., detecting tumors in X-rays), drug discovery, and personalized treatment planning. The field continues to evolve with innovations such as generative adversarial networks (GANs), reinforcement learning, and neurosymbolic AI, which combine deep learning with symbolic reasoning.
#How It Works
#Neural Network Architecture
Deep learning models are built on artificial neural networks (ANNs) composed of layers of interconnected nodes (neurons). Each neuron applies a weighted sum to its inputs, followed by an activation function (e.g., ReLU, sigmoid) to introduce non-linearity. The weights are adjusted during training to minimize prediction errors.
Key Components:
- Input Layer: Receives raw data (e.g., pixels of an image, words in a sentence).
- Hidden Layers: Intermediate layers that transform data through learned representations. Depth (number of layers) enables hierarchical feature extraction.
- Output Layer: Produces the final prediction (e.g., class probabilities, numerical values).
- Activation Functions: Introduce non-linearity, allowing the network to model complex relationships. Common functions include:
- ReLU (Rectified Linear Unit): Outputs the input directly if positive; otherwise, zero.
- Sigmoid: Squashes outputs between 0 and 1, useful for binary classification.
- Softmax: Converts outputs into probabilities for multi-class classification.
- Loss Function: Measures the difference between predicted and actual values (e.g., cross-entropy for classification, mean squared error for regression).
- Optimizer: Adjusts weights to minimize loss. Popular optimizers include:
- Stochastic Gradient Descent (SGD): Updates weights based on gradient estimates.
- Adam: Combines adaptive learning rates with momentum for faster convergence.
#Training Process
- Forward Propagation: Data flows through the network, generating predictions.
- Loss Calculation: The model’s predictions are compared to ground truth using a loss function.
- Backpropagation: The gradient of the loss is computed with respect to each weight, and weights are updated via the optimizer.
- Iteration: The process repeats over multiple epochs (passes through the dataset) until the model converges to a satisfactory performance.
#Types of Deep Learning Models
- Convolutional Neural Networks (CNNs): - Designed for grid-like data (e.g., images). - Use convolutional layers to detect local patterns (e.g., edges, textures) and pooling layers to reduce dimensionality. - Applications: Image classification, object detection, facial recognition.
- Recurrent Neural Networks (RNNs): - Process sequential data (e.g., time series, text) by maintaining a "memory" of previous inputs. - Variants include Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs), which mitigate the vanishing gradient problem. - Applications: Machine translation, speech recognition, sentiment analysis.
- Transformers: - Introduced in the 2017 paper "Attention Is All You Need," transformers rely on self-attention mechanisms to weigh the importance of different parts of the input. - Enable parallel processing of sequences, making them highly efficient for NLP tasks. - Applications: Language modeling (e.g., GPT, BERT), code generation, multimodal learning.
- Generative Models:
- Generative Adversarial Networks (GANs): Consist of a generator (creates data) and a discriminator (evaluates authenticity), trained adversarially.
- Variational Autoencoders (VAEs): Learn to encode and decode data, enabling generation of new samples. - Applications: Image synthesis, drug discovery, text generation.
- Reinforcement Learning (RL): - Models learn by interacting with an environment, receiving rewards for actions. - Deep RL combines neural networks with RL algorithms (e.g., Deep Q-Networks). - Applications: Robotics, game-playing AI (e.g., AlphaGo), autonomous systems.
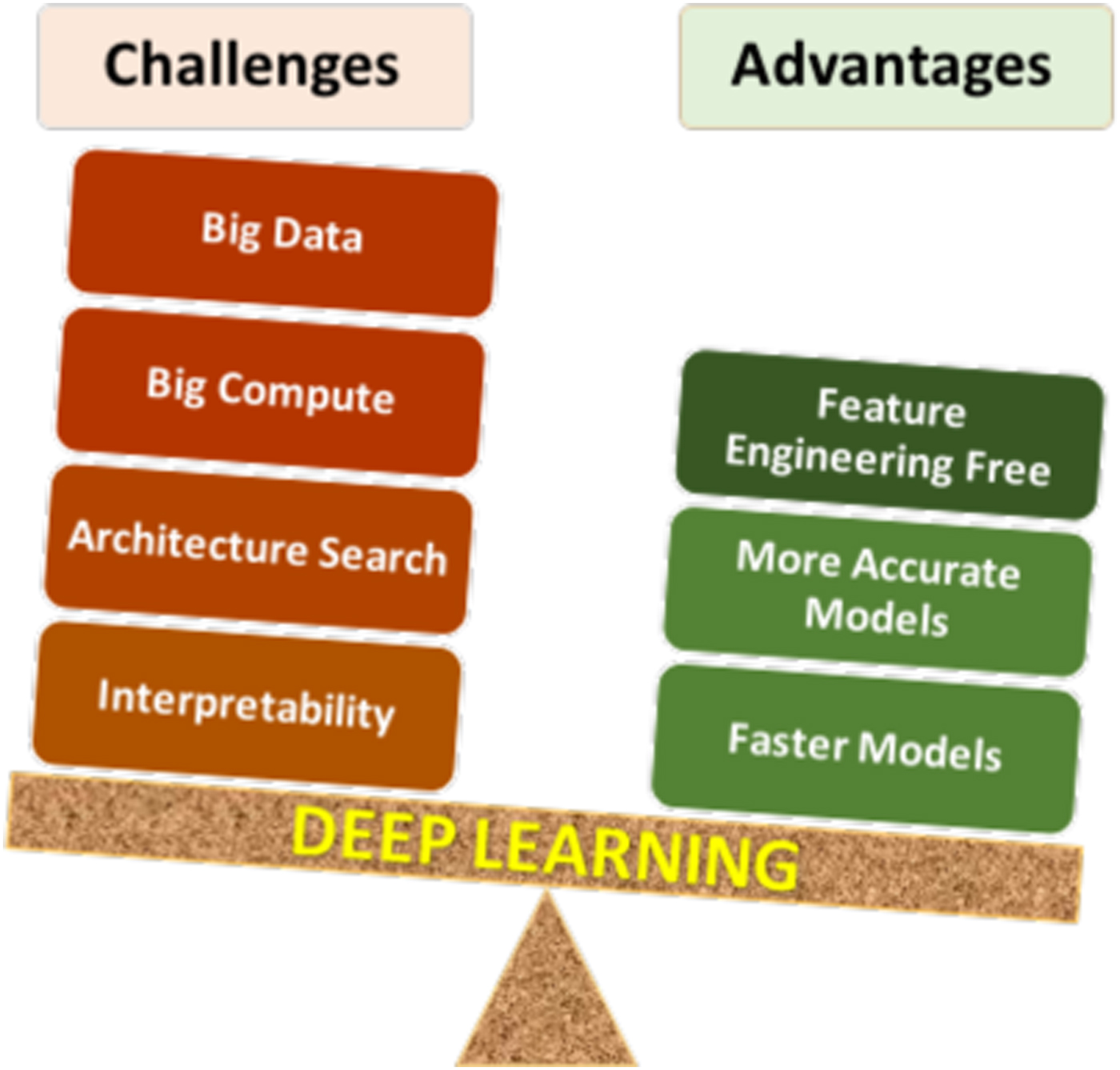
#Challenges and Solutions
- Overfitting: When a model performs well on training data but poorly on unseen data. Mitigated by techniques like dropout, regularization, and data augmentation.
- Vanishing/Exploding Gradients: Gradients become too small or large during backpropagation, hindering learning. Addressed by normalization (e.g., batch normalization) and advanced architectures (e.g., residual connections in ResNet).
- Computational Cost: Training deep models requires significant resources. Solutions include distributed training, model pruning, and quantization.
#Important Facts
- Data Dependency: Deep learning models require vast amounts of labeled data for training. For example, ImageNet contains over 14 million labeled images.
- Hardware Requirements: Training state-of-the-art models often necessitates specialized hardware like GPUs (e.g., NVIDIA A100) or TPUs (Tensor Processing Units by Google).
- Energy Consumption: Large-scale deep learning models can consume substantial energy. For instance, training a single Transformer model may emit as much CO₂ as five cars over their lifetimes.
- Bias and Fairness: Deep learning models can inherit biases present in training data, leading to unfair outcomes (e.g., racial or gender bias in facial recognition).
- Explainability: Many deep learning models operate as "black boxes," making it difficult to interpret their decisions. Techniques like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) aim to address this.
- Transfer Learning: Pre-trained models (e.g., ResNet, BERT) can be fine-tuned for specific tasks, reducing the need for large datasets and computational resources.
- Ethical Concerns: Deepfakes, autonomous weapons, and surveillance applications raise ethical dilemmas regarding privacy and misuse.
- Interdisciplinary Impact: Deep learning intersects with neuroscience (e.g., comparing artificial and biological neural networks), physics (e.g., simulating quantum systems), and biology (e.g., protein folding prediction via AlphaFold).
#Timeline
- Foundational ideas
Core concepts and early methods shape How Deep Learning Is Changing the World.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How Deep Learning Is Changing the World cover?
Explains how deep learning is changing the world, including the main process, tools, examples, risks, and practical implementation steps.
Why is How Deep Learning Is Changing the World important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Deep, Learning, Changing before using the ideas in real projects.
#References
- How Deep Learning Is Changing the World terminology and background research
- How Deep Learning Is Changing the World use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Deep case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.