.png?1678746405)
#Short Answer
Covers neural networks for dummies: a beginner’s overview, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
A neural network is a subset of artificial intelligence (AI) that mimics the structure and function of biological neural networks in the brain. Unlike traditional programming, where rules are explicitly defined, neural networks learn from examples by adjusting internal parameters (weights) to minimize errors. This ability to learn from data makes them powerful tools for solving complex problems that are difficult to program manually. Neural networks are composed of layers of interconnected nodes (neurons), where each layer transforms the input data into a more abstract representation. The simplest form is the feedforward neural network, where data flows in one direction—from input to output. More advanced architectures, such as convolutional neural networks (CNNs) for image processing or recurrent neural networks (RNNs) for sequential data, expand the model’s capabilities. The rise of deep learning, a subset of neural networks with many hidden layers, has revolutionized fields like computer vision, natural language processing (NLP), and robotics. Modern applications include self-driving cars, medical diagnosis, and personalized recommendations on streaming platforms.
#History / Background
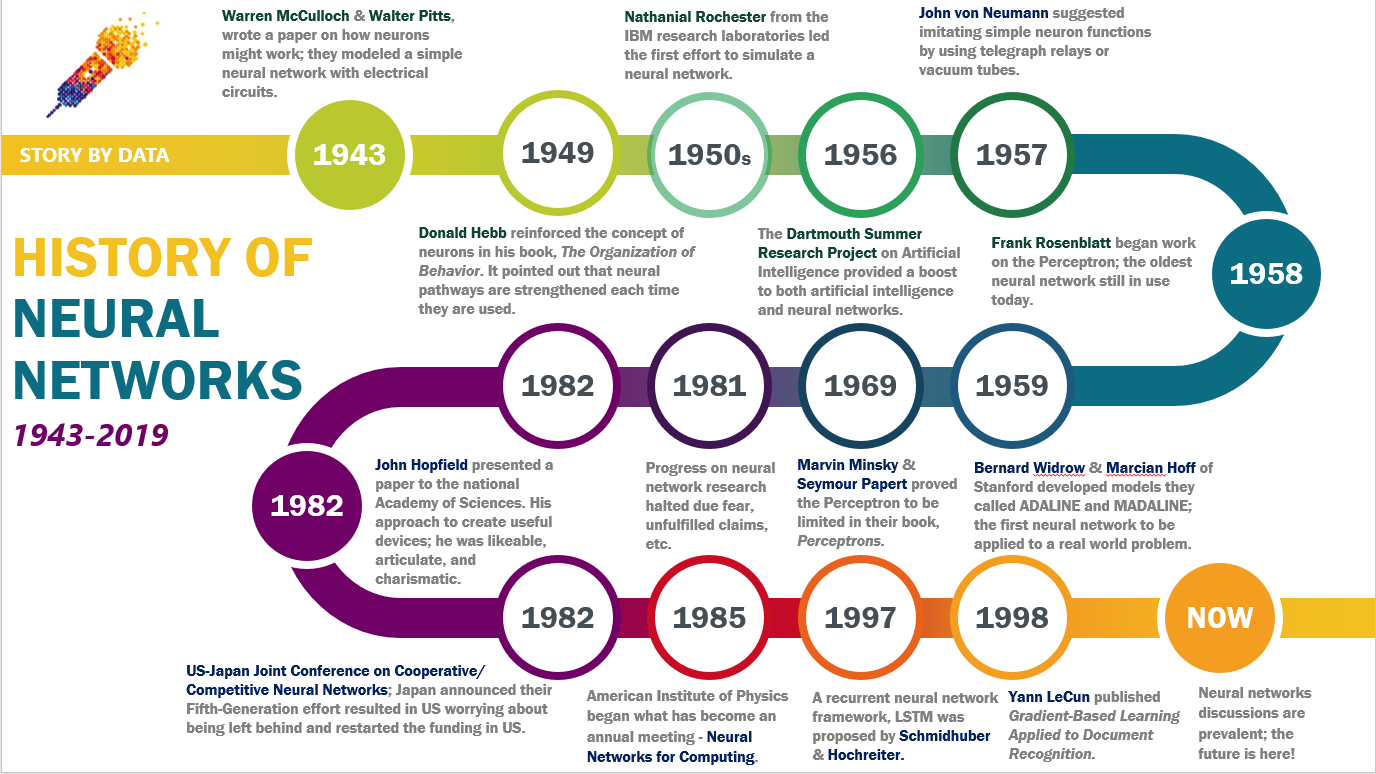
The concept of neural networks dates back to the 1940s, when researchers first explored the idea of simulating the brain’s neural activity. Key milestones in their development include:
- 1943: Warren McCulloch and Walter Pitts proposed the first mathematical model of a neuron, laying the foundation for artificial neural networks.
- 1958: Frank Rosenblatt developed the Perceptron, the first functional neural network capable of learning simple patterns.
- 1960s–1980s: Research slowed due to limited computational power and the XOR problem, which exposed limitations in single-layer Perceptrons.
- 1986: Geoffrey Hinton, David Rumelhart, and Ronald Williams introduced backpropagation, a method for training multi-layer networks, reviving interest in neural networks.
- 1997: The Long Short-Term Memory (LSTM) network was introduced, enabling better handling of sequential data.
- 2012: A breakthrough occurred when a deep convolutional neural network (AlexNet) won the ImageNet competition, demonstrating the power of deep learning.
- 2010s–Present: Neural networks became mainstream with advancements in GPU computing, big data, and cloud infrastructure, enabling large-scale models like transformers (used in AI chatbots) and generative adversarial networks (GANs). Today, neural networks are a cornerstone of AI, powering everything from smart assistants to medical imaging analysis.
#How It Works
#Basic Structure A neural network consists of three primary layers:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Perform computations and extract features. The more layers, the "deeper" the network.
- Output Layer: Produces the final prediction or classification (e.g., identifying a cat in an image). Each neuron in a layer is connected to neurons in the next layer via weights, which determine the strength of the connection. A bias is also added to shift the output of the neuron.
#Activation Functions Neurons use activation functions to introduce non-linearity, allowing the network to learn complex patterns. Common functions include:
- Sigmoid: Outputs values between 0 and 1 (useful for binary classification).
- ReLU (Rectified Linear Unit): Outputs the input directly if positive, else zero (common in deep networks).
- Tanh: Outputs values between -1 and 1 (smooth gradient for hidden layers).
#Training Process
Neural networks learn through training, where they adjust weights to minimize loss (error between predicted and actual outputs). The process involves:
- Forward Propagation: Input data passes through the network to generate a prediction.
- Loss Calculation: A loss function (e.g., Mean Squared Error for regression, Cross-Entropy for classification) measures the error.
- Backpropagation: The network calculates gradients (using gradient descent) to determine how much each weight contributed to the error and adjusts them accordingly.
- Iteration: Steps 1–3 repeat over multiple epochs (training cycles) until the model achieves acceptable accuracy.
#Key Concepts
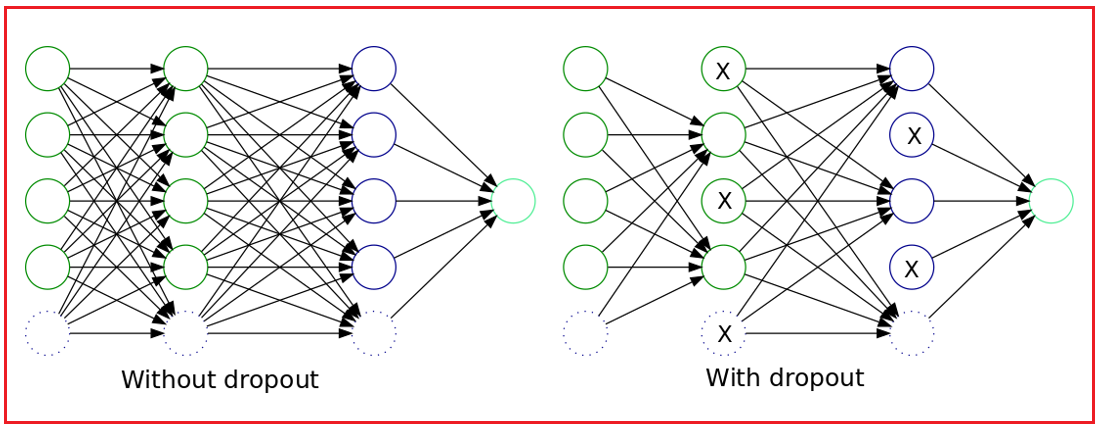
- Overfitting: When a model memorizes training data but fails to generalize to new data. Techniques like regularization (e.g., dropout, L1/L2 penalties) mitigate this.
- Hyperparameters: Configurable settings (e.g., learning rate, batch size, number of layers) that impact training performance.
- Optimizers: Algorithms like Adam or SGD (Stochastic Gradient Descent) that update weights efficiently.
#Important Facts
- No Explicit Programming: Neural networks learn from data rather than following predefined rules.
- Parallel Processing: GPUs accelerate training by processing multiple neurons simultaneously.
- Data Dependency: Performance relies heavily on the quality and quantity of training data.
- Black-Box Nature: Complex models (e.g., deep neural networks) are often difficult to interpret, leading to research in explainable AI (XAI).
- Transfer Learning: Pre-trained models (e.g., BERT for NLP) can be fine-tuned for specific tasks, saving time and resources.
- Energy Consumption: Large neural networks require significant computational power, raising concerns about environmental impact.
#Timeline
- Foundational ideas
Core concepts and early methods shape Neural Networks for Dummies: a Beginner’s Overview.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Neural Networks for Dummies: a Beginner’s Overview cover?
Covers neural networks for dummies: a beginner’s overview, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Neural Networks for Dummies: a Beginner’s Overview important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Neural, Networks, Beginner before using the ideas in real projects.
#References
- Neural Networks for Dummies: a Beginner’s Overview terminology and background research
- Neural Networks for Dummies: a Beginner’s Overview use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Neural case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.