#Short Answer
Covers meaning of neural networks, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
#Overview
Neural networks are a class of machine learning models designed to mimic the way the human brain processes information. They consist of artificial neurons (nodes) arranged in layers, where each neuron receives input, processes it, and passes the output to the next layer. The strength of neural networks lies in their ability to learn from data without explicit programming, making them highly effective for tasks involving pattern recognition, classification, and regression. At their core, neural networks operate by adjusting weights (strength of connections between neurons) and biases (thresholds for neuron activation) through a process called training. During training, the network iteratively refines its parameters to minimize errors, a technique known as backpropagation. This adaptability allows neural networks to generalize from training data and perform well on unseen inputs. Neural networks are categorized based on their architecture:
- Feedforward Neural Networks (FNNs): Data flows in one direction, from input to output.
- Convolutional Neural Networks (CNNs): Specialized for grid-like data (e.g., images), using convolutional layers to extract features.
- Recurrent Neural Networks (RNNs): Designed for sequential data (e.g., time series, text), with loops that allow information to persist.
- Transformers: Introduced in 2017, these models use self-attention mechanisms to process sequences efficiently, powering modern AI applications like large language models.
#History / Background
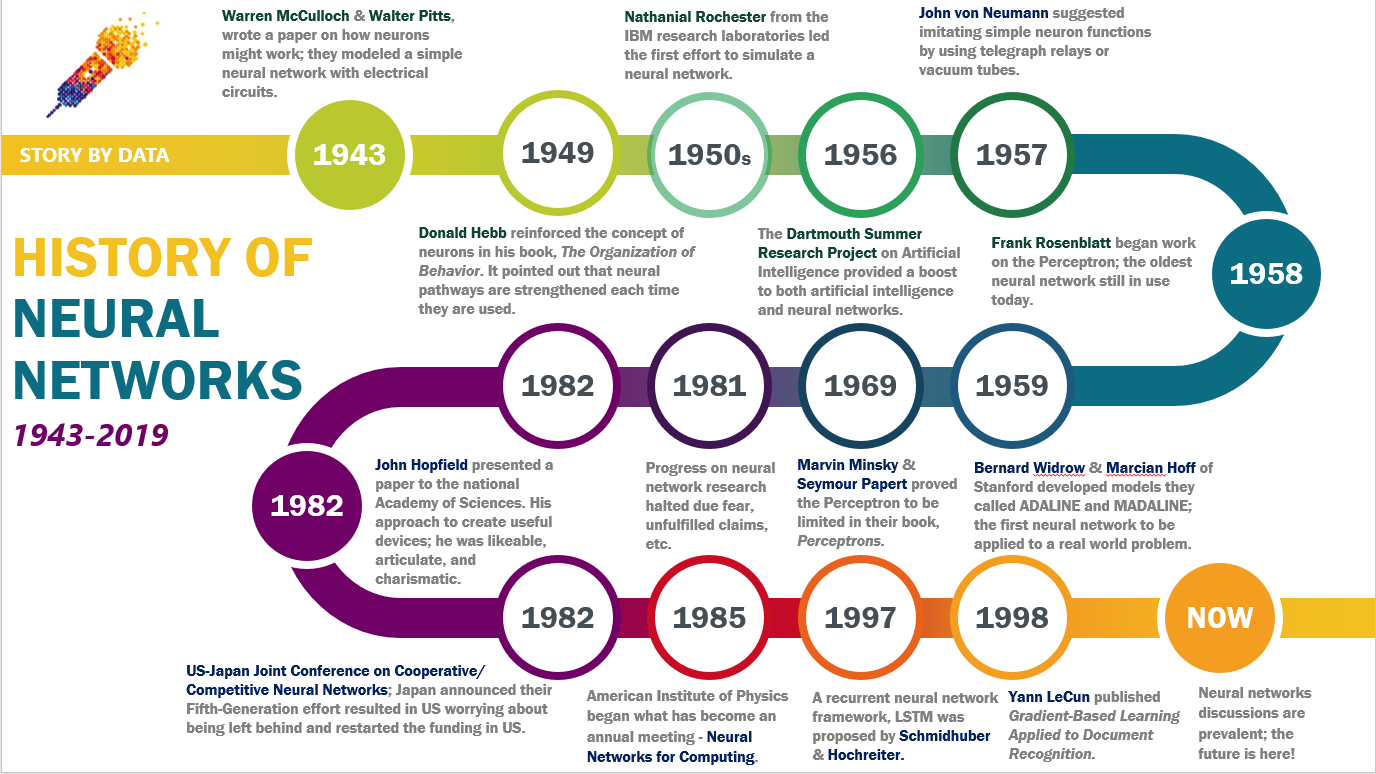
The concept of neural networks dates back to the 1940s, with early work by Warren McCulloch and Walter Pitts, who proposed a mathematical model of artificial neurons. Their 1943 paper, "A Logical Calculus of Ideas Immanent in Nervous Activity," laid the groundwork for computational neuroscience and artificial intelligence. In 1958, Frank Rosenblatt developed the Perceptron, the first functional neural network model capable of learning. The Perceptron could classify linearly separable data, but its limitations were exposed in 1969 when Marvin Minsky and Seymour Papert demonstrated that it could not solve non-linear problems like the XOR function. This led to a decline in neural network research during the 1970s, known as the "AI Winter." The field revived in the 1980s with the introduction of backpropagation by David Rumelhart, Geoffrey Hinton, and Ronald Williams, which enabled multi-layer networks to learn complex patterns. The 1990s saw the rise of support vector machines (SVMs) and other machine learning methods, temporarily overshadowing neural networks. The 2000s marked a renaissance for neural networks, driven by:
- Increased computational power (GPUs for parallel processing).
- Big data availability for training.
- Breakthroughs in deep learning, such as AlexNet (2012), a CNN that achieved state-of-the-art performance in image recognition. Since then, neural networks have become the backbone of modern AI, powering applications like self-driving cars, voice assistants, and generative AI (e.g., large language models like GPT).
#How It Works
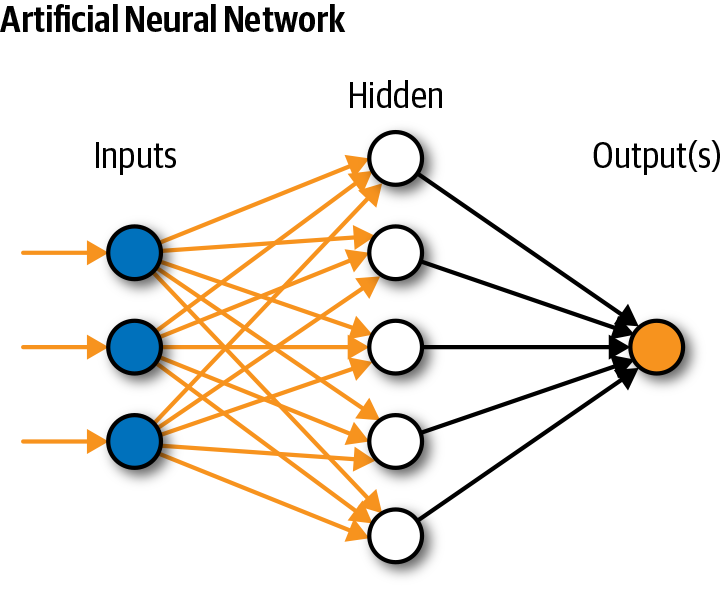
#Basic Structure A neural network consists of three primary layers:
- Input Layer: Receives raw data (e.g., pixels in an image, words in a sentence).
- Hidden Layers: Intermediate layers where computations occur. The number of hidden layers determines the network's "depth" (hence "deep learning").
- Output Layer: Produces the final prediction (e.g., a class label, a probability score). Each neuron in a layer is connected to neurons in the next layer via weights. The strength of these connections determines how much influence one neuron has on another.
#Key Concepts
- Weights and Biases:
- Weights adjust the strength of input signals.
- Biases shift the activation function, allowing the network to fit data better.
- Activation Functions: - Introduce non-linearity, enabling the network to learn complex patterns. - Common functions: ReLU (Rectified Linear Unit), Sigmoid, Tanh.
- Forward Propagation: - Input data is passed through the network layer by layer, with each neuron applying a weighted sum followed by an activation function.
- Loss Function: - Measures the difference between predicted and actual outputs (e.g., Mean Squared Error for regression, Cross-Entropy Loss for classification).
- Backpropagation: - The network calculates the gradient of the loss function with respect to each weight using the chain rule of calculus. - Gradients are used to update weights via optimization algorithms (e.g., Stochastic Gradient Descent (SGD)).
- Training: - The network iteratively adjusts weights to minimize loss on a training dataset.
- Validation and test datasets are used to evaluate performance and generalization.
#Example: Image Recognition
- Input: A 224x224 pixel image (flattened into a vector).
- Convolutional Layers: Extract features (edges, textures) using filters.
- Pooling Layers: Reduce spatial dimensions (e.g., max pooling).
- Fully Connected Layers: Combine features for classification (e.g., "cat" or "dog").
- Output: Probability distribution over possible classes.
#Important Facts
- Universal Approximation Theorem: A neural network with at least one hidden layer can approximate any continuous function, given sufficient neurons and proper training.
- Overfitting vs. Underfitting:
- Overfitting: The model memorizes training data but performs poorly on unseen data (high variance).
- Underfitting: The model fails to capture underlying patterns (high bias).
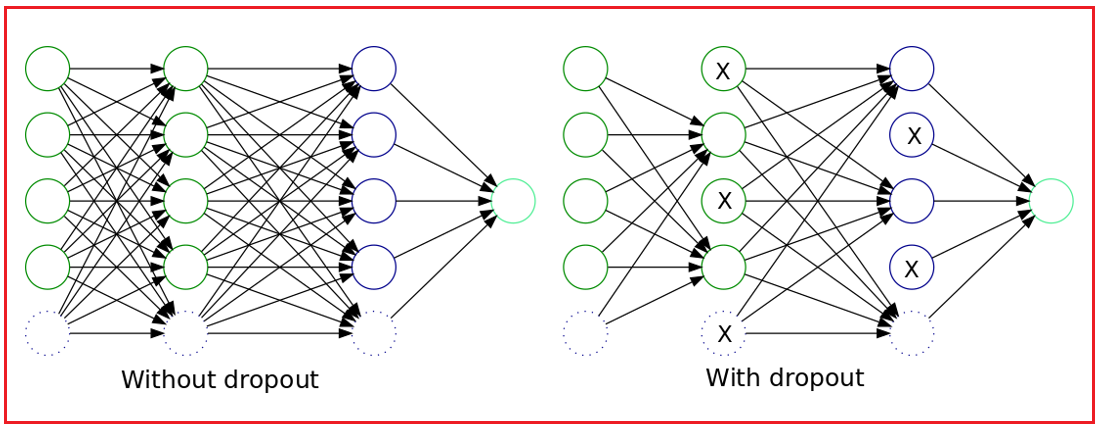
- Solutions: Regularization (e.g., dropout, L1/L2 penalties), early stopping, data augmentation.
- Hyperparameters: Key settings that influence training:
- Learning Rate: Controls the size of weight updates.
- Batch Size: Number of samples processed before updating weights.
- Epochs: Number of passes through the entire dataset.
- Architecture: Number of layers, neurons per layer.
- Transfer Learning: Pre-trained models (e.g., ResNet, BERT) are fine-tuned for specific tasks, reducing training time and data requirements.
- Explainability: Neural networks are often "black boxes." Techniques like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) help interpret decisions.
- Hardware Acceleration: Neural networks rely on GPUs and TPUs for efficient parallel processing, especially for deep learning models.
- Ethical Considerations:
- Bias and Fairness: Models may inherit biases from training data (e.g., facial recognition disparities).
- Privacy: Training on sensitive data raises concerns about data leakage.
- Misuse: Deepfakes and autonomous weapons highlight potential risks.
#Timeline
- Foundational ideas
Core concepts and early methods shape Meaning of Neural Networks.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Meaning of Neural Networks cover?
Covers meaning of neural networks, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Meaning of Neural Networks important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Meaning, Neural, Networks before using the ideas in real projects.
#References
- Meaning of Neural Networks terminology and background research
- Meaning of Neural Networks use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Meaning case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.