
#Short Answer
Explains how to get started with deep learning, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
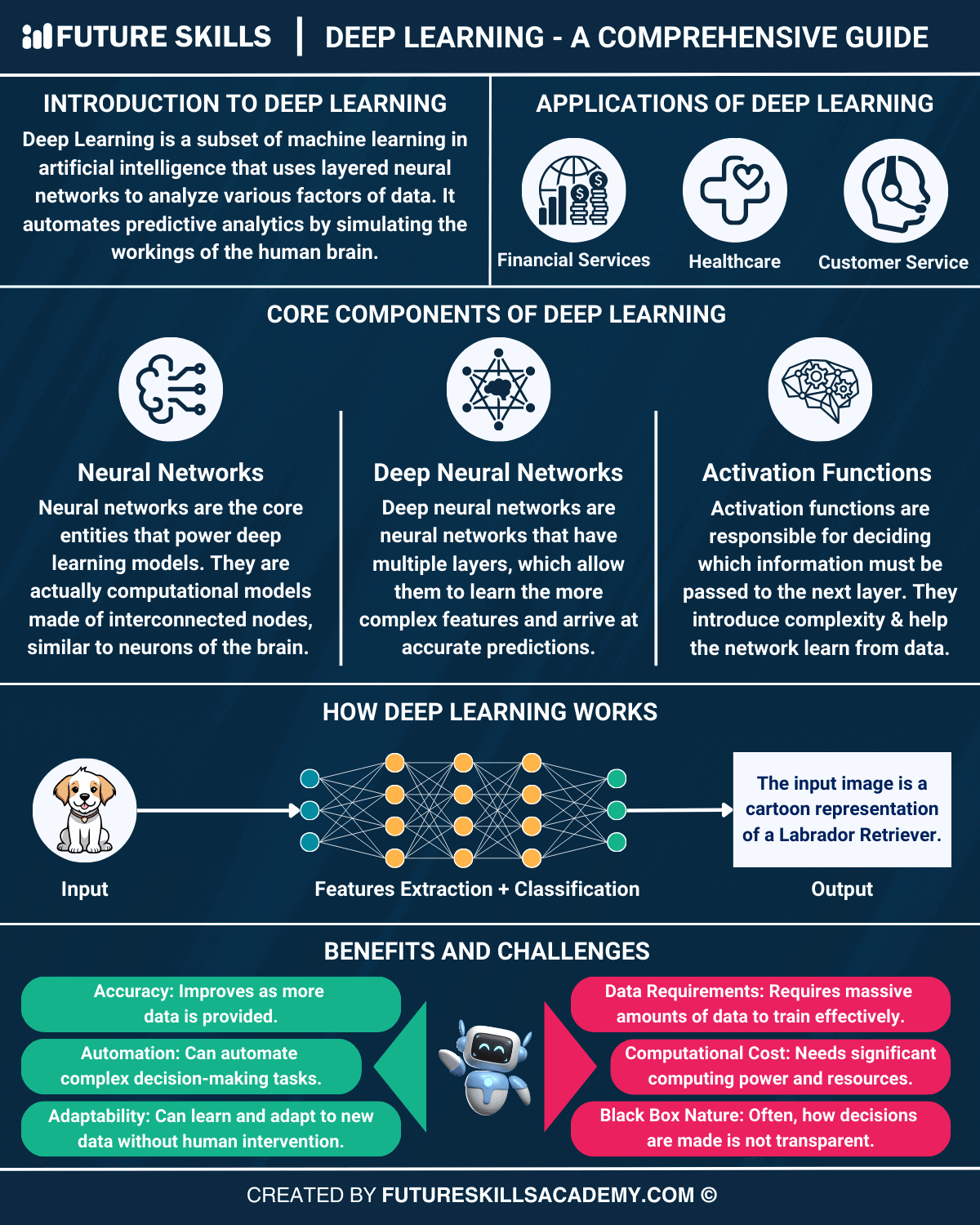
Deep learning is a transformative branch of artificial intelligence (AI) that enables machines to learn from vast amounts of data by mimicking the structure and function of the human brain. Unlike traditional machine learning, which relies on handcrafted features, deep learning automatically extracts relevant features from raw data through hierarchical layers of artificial neurons. This capability has led to breakthroughs in fields such as computer vision, natural language processing (NLP), and reinforcement learning. The core of deep learning lies in artificial neural networks (ANNs), which consist of interconnected nodes (neurons) organized in layers. These networks learn by adjusting the weights of connections between neurons based on the error of their predictions—a process known as backpropagation. The depth of these networks (i.e., the number of layers) allows them to model highly complex patterns, making deep learning particularly effective for tasks requiring nuanced understanding, such as image classification or language translation.
#History / Background
#Early Foundations (1940s–1980s)
The conceptual roots of deep learning trace back to the 1940s with the work of Warren McCulloch and Walter Pitts, who proposed a simplified model of the neuron. In 1958, Frank Rosenblatt developed the Perceptron, an early form of a neural network capable of binary classification. However, limitations in computational power and the lack of effective training algorithms hindered progress.
#The First AI Winter (1970s–1980s)
During this period, skepticism about neural networks grew due to the XOR problem, which the Perceptron could not solve. Research stagnated until Geoffrey Hinton, David Rumelhart, and Ronald Williams introduced backpropagation in 1986, enabling neural networks to learn from errors by adjusting weights iteratively. This breakthrough reignited interest in the field.
#The Rise of Deep Learning (2000s–Present)
The modern era of deep learning began in the early 2000s, driven by three key factors:
- Increased Computational Power: The advent of GPUs (graphics processing units) allowed for faster training of large neural networks.
- Big Data: The explosion of digital data (e.g., images, text) provided the fuel for training complex models.
- Algorithmic Advances: Innovations like ReLU (Rectified Linear Unit) activation functions and dropout regularization improved training efficiency and model performance. Landmark achievements include:
- 2012: AlexNet, a deep convolutional neural network (CNN), won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) with a significant margin, demonstrating the power of deep learning in computer vision.
- 2016: AlphaGo, developed by DeepMind, defeated a world champion Go player, showcasing deep learning’s potential in strategic decision-making.
- 2020s: Large language models (LLMs) like GPT-3 and BERT revolutionized NLP, enabling applications such as chatbots, translation, and content generation.
#How It Works
#Neural Networks: The Building Blocks A deep learning model is composed of multiple layers of artificial neurons, organized into three primary types:
- Input Layer: Receives raw data (e.g., pixels of an image, words in a sentence).
- Hidden Layers: Perform computations and extract features. These layers can include:
- Convolutional Layers (CNNs): Ideal for spatial data like images, using filters to detect patterns (e.g., edges, textures).
- Recurrent Layers (RNNs/LSTMs): Suitable for sequential data (e.g., time series, text), where the order of inputs matters.
- Fully Connected Layers: Connect every neuron in one layer to every neuron in the next, used for high-level reasoning.
- Output Layer: Produces the final prediction (e.g., a class label, a probability score).
#Key Concepts
- Activation Functions: Introduce non-linearity to the model, enabling it to learn complex patterns. Common functions include:
- ReLU (Rectified Linear Unit): Outputs the input directly if positive; otherwise, zero.
- Sigmoid: Squashes outputs between 0 and 1, useful for binary classification.
- Softmax: Converts outputs into probabilities for multi-class classification.
- Loss Functions: Measure the difference between predicted and actual values. Examples:
- Mean Squared Error (MSE): Used for regression tasks.
- Cross-Entropy Loss: Common in classification problems.
- Optimization Algorithms: Adjust the model’s weights to minimize loss. Popular methods include:
- Stochastic Gradient Descent (SGD): Updates weights based on the gradient of the loss function.
- Adam: Combines adaptive learning rates with momentum for faster convergence.
- Regularization: Techniques to prevent overfitting (e.g., dropout, L1/L2 regularization).
#Training Process
- Forward Propagation: Data passes through the network, and predictions are generated.
- Loss Calculation: The loss function quantifies the error between predictions and true labels.
- Backpropagation: The gradient of the loss is computed with respect to each weight, and weights are updated to reduce the loss.
- Iteration: The process repeats over multiple epochs (full passes through the dataset) until the model converges.
#Important Facts
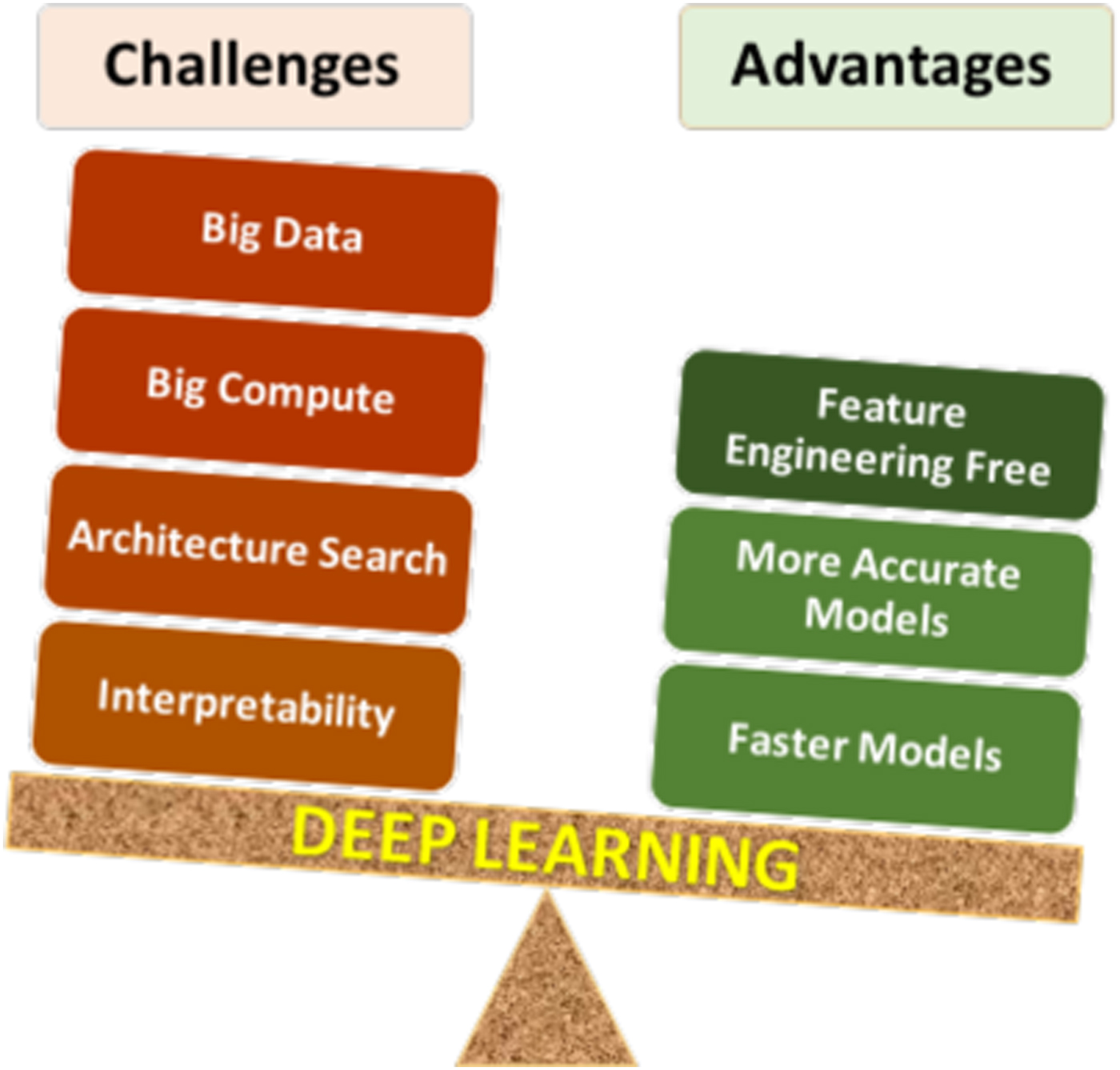
- Data Dependency: Deep learning models require large datasets to generalize well. Small datasets may lead to overfitting.
- Computational Cost: Training deep models demands significant computational resources, often necessitating GPUs or TPUs (Tensor Processing Units).
- Transfer Learning: Pre-trained models (e.g., ResNet, BERT) can be fine-tuned for specific tasks, reducing the need for extensive training data.
- Ethical Considerations: Deep learning raises concerns about bias, privacy, and misuse (e.g., deepfakes, surveillance).
- Hardware Advancements: The development of TPUs by Google and NPUs (Neural Processing Units) by companies like Intel and NVIDIA has accelerated deep learning research and deployment.
- Explainability: Deep learning models are often "black boxes," making it challenging to interpret their decisions. Techniques like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) aim to address this.
#Timeline
- Foundational ideas
Core concepts and early methods shape How to Get Started with Deep Learning.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How to Get Started with Deep Learning cover?
Explains how to get started with deep learning, including the main process, tools, examples, risks, and practical implementation steps.
Why is How to Get Started with Deep Learning important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Get, Started, Deep before using the ideas in real projects.
#References
- How to Get Started with Deep Learning terminology and background research
- How to Get Started with Deep Learning use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Get case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.