
#Short Answer
Explains how to get started with computer vision, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
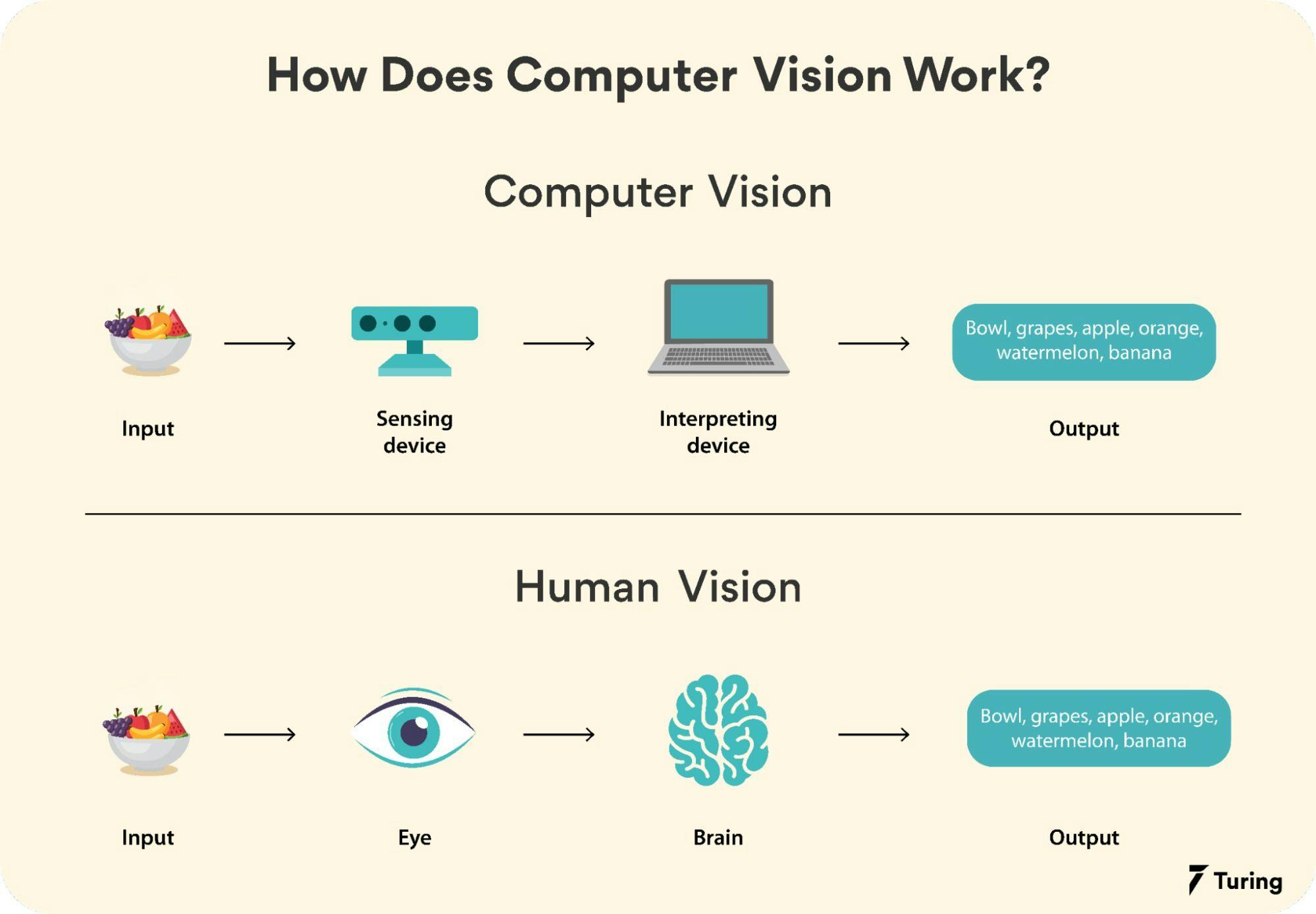
Computer vision is a multidisciplinary field that combines computer science, mathematics, and cognitive science to enable machines to interpret and act upon visual data. Unlike traditional image processing, which focuses on manipulating images, computer vision aims to extract meaningful information from visual inputs, such as identifying objects, detecting patterns, or understanding scenes. The field has evolved significantly over the past few decades, transitioning from rule-based systems to advanced deep learning models. Today, computer vision powers applications ranging from facial recognition and medical diagnostics to autonomous driving and augmented reality. Its integration with other AI domains, such as natural language processing and robotics, continues to expand its potential.
#History / Background
#Early Foundations (1950s–1970s)
The origins of computer vision trace back to the 1950s and 1960s, when researchers began exploring ways to automate visual perception. Early work focused on pattern recognition and simple image processing tasks. In 1966, MIT’s Seymour Papert and Marvin Minsky initiated the "Summer Vision Project," aiming to develop a system that could describe a scene from an image. This project laid the groundwork for future research. During this period, techniques like edge detection and segmentation were developed, primarily using handcrafted features. However, progress was limited by computational constraints and the lack of large datasets.
#The Rise of Machine Learning (1980s–2000s)
The 1980s and 1990s saw the emergence of machine learning techniques in computer vision. Researchers began using statistical methods and neural networks to improve image classification and object recognition. The introduction of the Scale-Invariant Feature Transform (SIFT) by David Lowe in 1999 revolutionized feature extraction, enabling more robust image matching and recognition. Despite these advancements, traditional computer vision methods struggled with complex, real-world scenarios due to their reliance on predefined features and limited scalability.
#The Deep Learning Revolution (2010s–Present)
The breakthrough in computer vision came with the advent of deep learning, particularly convolutional neural networks (CNNs). The 2012 ImageNet competition marked a turning point when AlexNet, a deep CNN, achieved unprecedented accuracy in image classification, outperforming traditional methods by a significant margin. Since then, deep learning has dominated the field, with architectures like ResNet, YOLO (You Only Look Once), and Faster R-CNN pushing the boundaries of object detection and segmentation. The availability of large datasets (e.g., ImageNet, COCO) and powerful GPUs has further accelerated progress. Today, computer vision is a cornerstone of modern AI, with applications in healthcare, security, retail, and beyond.
#How It Works
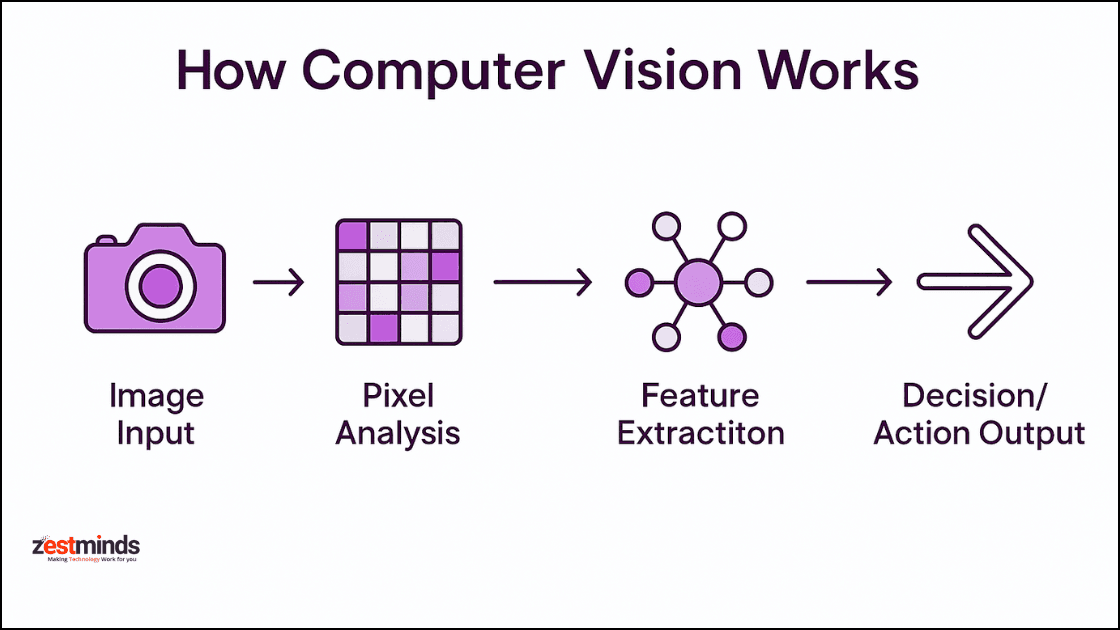
Computer vision systems process visual data through a series of steps, often involving preprocessing, feature extraction, and decision-making. The exact workflow depends on the task, but the following stages are common:
#1. Image Acquisition The process begins with capturing visual data using cameras, sensors, or pre-existing images. The quality of input data (resolution, lighting, noise) significantly impacts the system’s performance.
#2. Preprocessing Raw images often require enhancement to improve clarity and remove noise. Common preprocessing techniques include:
- Grayscale conversion (reducing computational load)
- Noise reduction (e.g., Gaussian blur, median filtering)
- Normalization (adjusting pixel values to a standard range)
- Augmentation (artificially expanding datasets via rotations, flips, or brightness adjustments)
#3. Feature Extraction Features are distinctive attributes of an image that help in classification or recognition. Traditional methods relied on handcrafted features like:
- Edges (Canny edge detection)
- Corners (Harris corner detection)
- Textures (Local Binary Patterns)
- Histograms of Oriented Gradients (HOG) Modern deep learning approaches, particularly CNNs, automatically learn hierarchical features from raw pixels, eliminating the need for manual feature engineering.
#4. Model Training Computer vision models are trained using labeled datasets. For example:
- Classification tasks use datasets like ImageNet, where images are labeled with categories (e.g., "cat," "dog").
- Object detection tasks use datasets like COCO, which provide bounding box annotations.
- Segmentation tasks use datasets like PASCAL VOC, where each pixel is labeled. Training involves optimizing a loss function (e.g., cross-entropy for classification) using algorithms like Stochastic Gradient Descent (SGD) or Adam.
#5. Inference Once trained, the model can make predictions on new, unseen data. For instance: - A classification model predicts the category of an input image. - An object detection model identifies and localizes objects within an image. - A segmentation model delineates object boundaries at the pixel level.
#6. Post-Processing Results may require refinement to improve accuracy or usability. Techniques include:
- Non-Maximum Suppression (NMS) (removing duplicate detections)
- Thresholding (filtering low-confidence predictions)
- 3D reconstruction (for depth estimation)
#Important Facts
- Human vs. Machine Vision: While humans can recognize objects effortlessly, computer vision systems require millions of labeled examples to achieve similar accuracy.
- Computational Demand: Training deep learning models for computer vision often requires high-performance GPUs or TPUs due to the massive computational resources needed.
- Real-Time Processing: Applications like autonomous vehicles and robotics demand real-time processing, necessitating optimized algorithms and hardware acceleration.
- Bias in Datasets: Computer vision models can inherit biases present in training data, leading to unfair or inaccurate predictions (e.g., racial or gender bias in facial recognition).
- Transfer Learning: Pre-trained models (e.g., ResNet, VGG) can be fine-tuned for specific tasks, reducing the need for large labeled datasets.
- Explainability: Deep learning models are often "black boxes," making it challenging to interpret their decision-making process. Techniques like Grad-CAM help visualize which parts of an image influenced the prediction.
- Ethical Concerns: Computer vision raises ethical issues, including privacy violations (e.g., surveillance), misuse in deepfakes, and potential job displacement in industries reliant on manual inspection.
#Timeline
- Foundational ideas
Core concepts and early methods shape How to Get Started with Computer Vision.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How to Get Started with Computer Vision cover?
Explains how to get started with computer vision, including the main process, tools, examples, risks, and practical implementation steps.
Why is How to Get Started with Computer Vision important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Computer Vision decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Get, Started, Computer before using the ideas in real projects.
#References
- How to Get Started with Computer Vision terminology and background research
- How to Get Started with Computer Vision use cases, implementation examples, and limitations
- Computer Vision best practices, standards, and risk guidance
- Get case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.