#Short Answer
Covers the science behind computer vision, including core concepts, practical examples, benefits, limitations, and risks in Computer Vision.
#Infobox
#Overview
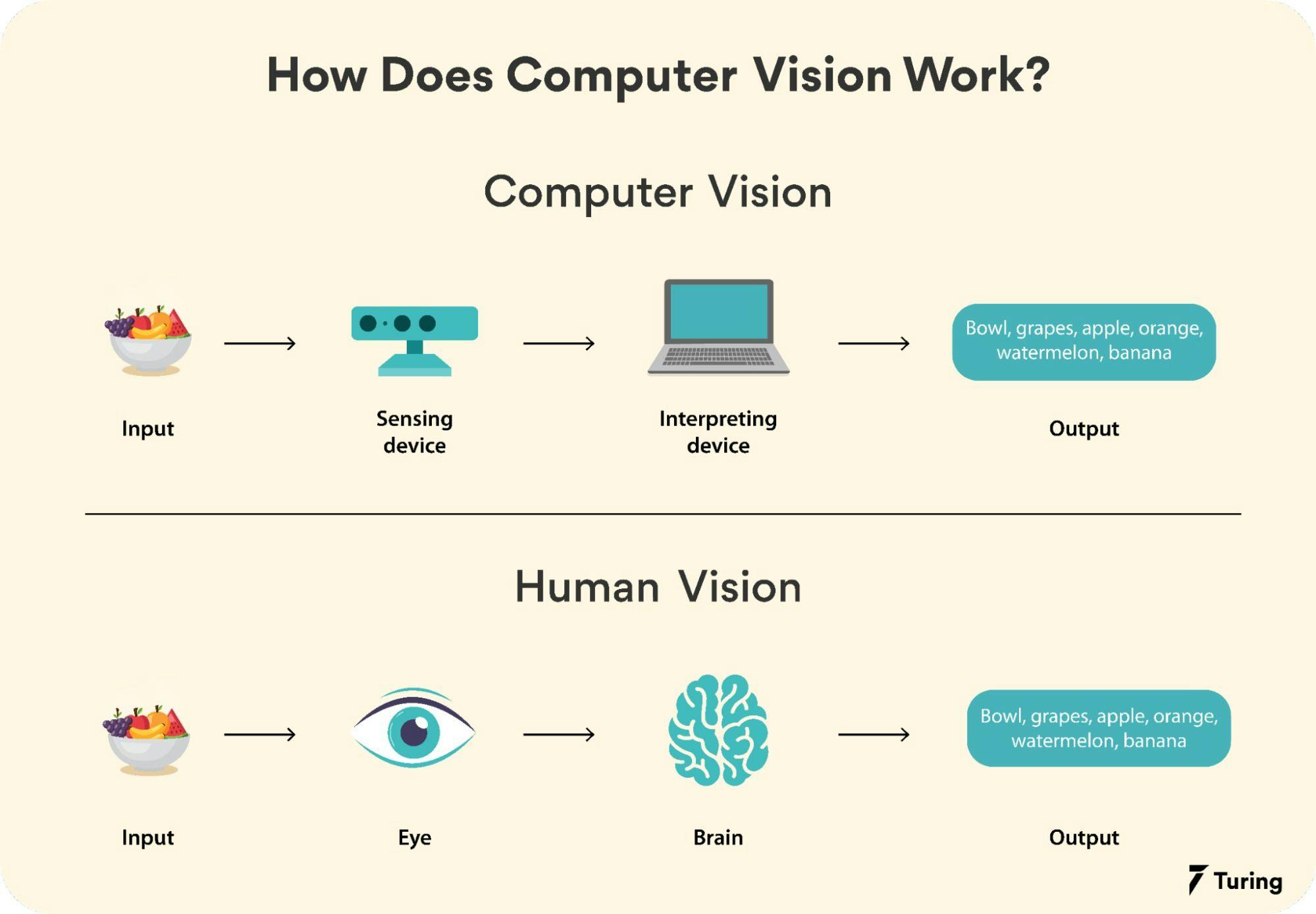
Computer vision (CV) is a multidisciplinary field that focuses on enabling computers to derive meaningful information from digital images, videos, and other visual inputs. It bridges the gap between human visual perception and machine interpretation, allowing systems to perform tasks such as object recognition, scene understanding, and decision-making based on visual data. The primary goal of computer vision is to replicate the human ability to see and interpret the world, but with greater speed, precision, and scalability. Unlike traditional image processing, which relies on predefined algorithms, modern computer vision leverages artificial intelligence (AI) and machine learning (ML) to adapt and improve over time. Applications of computer vision span diverse industries, including healthcare (medical imaging), automotive (self-driving cars), security (facial recognition), retail (inventory management), and agriculture (crop monitoring). As computational power and data availability grow, computer vision continues to evolve, driving innovations in automation and human-computer interaction.
#History / Background
#Early Foundations (1950s–1970s)
The origins of computer vision trace back to the 1950s and 1960s, when researchers began exploring pattern recognition and image processing. Early work focused on simple tasks like edge detection and character recognition. In 1966, MIT’s Seymour Papert and Marvin Minsky launched the "Summer Vision Project," aiming to develop a system that could describe a scene from a camera input—a foundational step toward automated visual understanding. During this period, techniques were largely rule-based, relying on handcrafted algorithms to identify features in images. Limitations in computational power and data storage restricted progress, but these efforts laid the groundwork for future advancements.
#The AI Revolution (1980s–1990s)
The 1980s and 1990s saw significant strides in computer vision, driven by improvements in computing and the rise of AI. Researchers developed more sophisticated methods, such as feature-based matching and stereo vision, which enabled 3D reconstruction from 2D images. The introduction of support vector machines (SVMs) and other statistical learning techniques improved classification tasks. However, challenges persisted, particularly in handling variability in real-world images (e.g., lighting changes, occlusions). The field remained fragmented, with limited success in generalizing beyond controlled environments.
#The Deep Learning Era (2010s–Present)
The breakthrough in computer vision came with the advent of deep learning, particularly Convolutional Neural Networks (CNNs). Pioneered by researchers like Yann LeCun (creator of LeNet) and Geoffrey Hinton, CNNs revolutionized the field by automatically learning hierarchical features from raw pixel data, eliminating the need for manual feature engineering. Key milestones include:
- 2012: AlexNet, a CNN architecture, won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), achieving unprecedented accuracy in image classification.
- 2015: Microsoft’s ResNet surpassed human-level performance in image recognition tasks.
- 2016: Google’s AlphaGo demonstrated computer vision’s role in decision-making by analyzing visual data during gameplay. Today, computer vision powers real-time applications like facial recognition, autonomous driving, and medical diagnostics, with ongoing research exploring 3D vision, generative models, and multimodal learning.
#How It Works
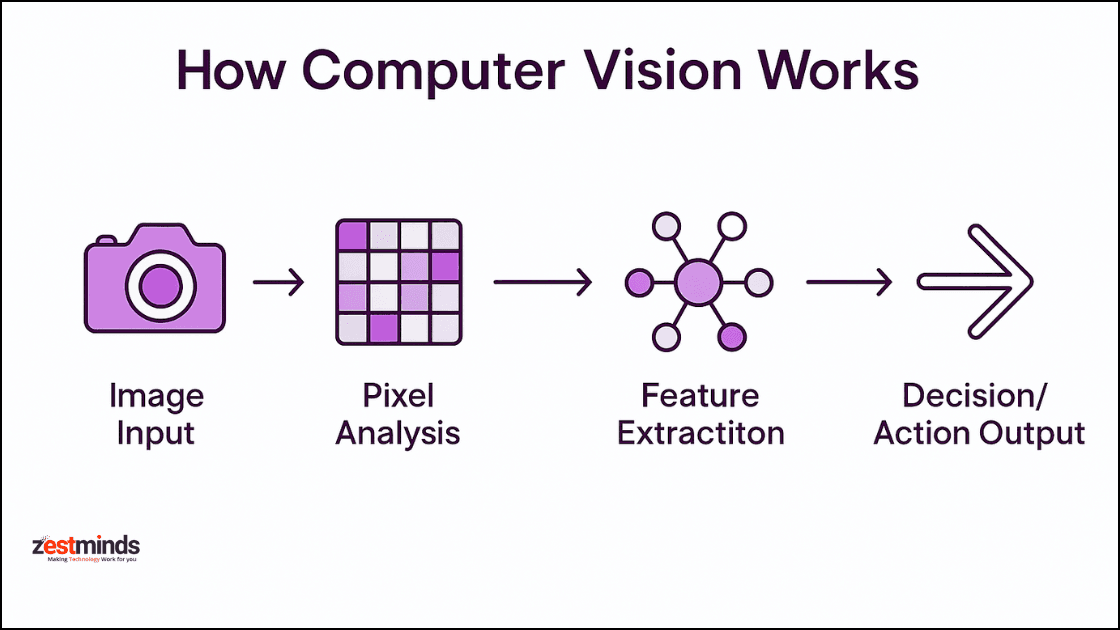
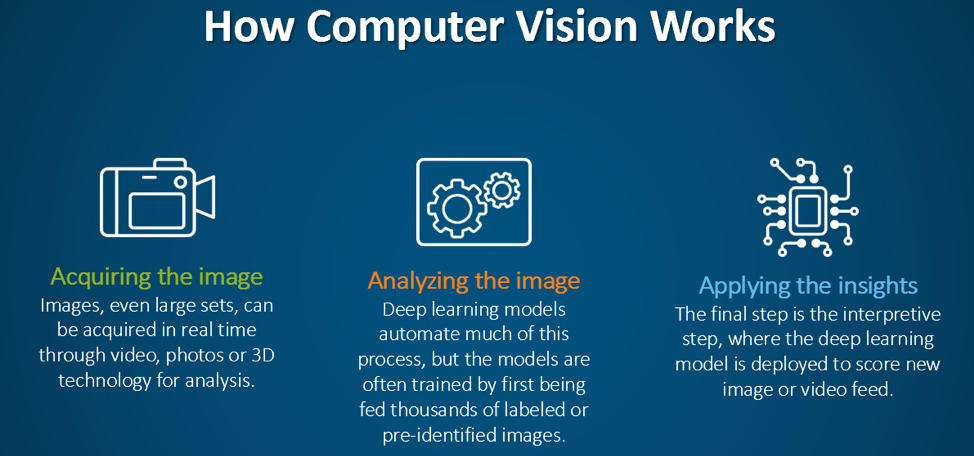
#Core Principles Computer vision systems process visual data through a series of steps, transforming raw pixels into actionable insights. The process typically involves:
- Image Acquisition: Capturing visual data via cameras, sensors, or other imaging devices.
- Preprocessing: Enhancing image quality by reducing noise, normalizing lighting, and correcting distortions.
- Feature Extraction: Identifying key patterns (e.g., edges, textures, shapes) using algorithms like SIFT (Scale-Invariant Feature Transform) or HOG (Histogram of Oriented Gradients).
- Object Detection/Recognition: Classifying objects within an image using models like CNNs or YOLO (You Only Look Once).
- Scene Understanding: Interpreting the context of objects (e.g., spatial relationships, actions).
- Decision Making: Applying the extracted information to perform tasks (e.g., navigation, identification).
#Key Techniques
- Convolutional Neural Networks (CNNs): Deep learning models designed to process grid-like data (e.g., images) by applying convolutional filters to detect features hierarchically.
- Transfer Learning: Leveraging pre-trained models (e.g., ResNet, VGG) to adapt to new tasks with minimal data.
- Semantic Segmentation: Partitioning an image into meaningful regions (e.g., separating a car from its background).
- Optical Character Recognition (OCR): Converting text in images into machine-readable data.
- 3D Vision: Reconstructing 3D models from 2D images using techniques like stereo vision or LiDAR.
#Challenges Despite advancements, computer vision faces hurdles:
- Variability: Real-world images vary in lighting, angles, and occlusions.
- Data Requirements: Deep learning models demand large, labeled datasets.
- Bias and Fairness: Algorithms may inherit biases from training data (e.g., facial recognition disparities).
- Computational Cost: Training large models requires significant resources.
#Important Facts
- Human vs. Machine Vision: While humans process visual information in ~130 milliseconds, computer vision systems can analyze thousands of images per second.
- ImageNet Dataset: A benchmark dataset with over 14 million labeled images, pivotal in training modern CV models.
- GPU Acceleration: Graphics Processing Units (GPUs) have accelerated CV tasks by enabling parallel processing of large datasets.
- Edge Computing: Deploying CV models on edge devices (e.g., smartphones) reduces latency and enhances privacy.
- Ethical Concerns: Facial recognition systems have sparked debates over privacy and surveillance.
#Timeline
- Foundational ideas
Core concepts and early methods shape The Science Behind Computer Vision.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does The Science Behind Computer Vision cover?
Covers the science behind computer vision, including core concepts, practical examples, benefits, limitations, and risks in Computer Vision.
Why is The Science Behind Computer Vision important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Computer Vision decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Science, Behind, Computer before using the ideas in real projects.
#References
- The Science Behind Computer Vision terminology and background research
- The Science Behind Computer Vision use cases, implementation examples, and limitations
- Computer Vision best practices, standards, and risk guidance
- Science case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.