
#Short Answer
Traces timeline of computer vision, highlighting major milestones, context, examples, and future implications.
#Infobox
#Overview
Computer vision is a multidisciplinary field that integrates computer science, mathematics, and cognitive science to enable machines to process, analyze, and interpret visual information from the real world. Unlike traditional image processing, which focuses on manipulating pixel data, computer vision aims to extract meaningful insights, such as object recognition, scene understanding, and decision-making, from visual inputs. The field has witnessed exponential growth due to advancements in computational power, the availability of large datasets, and breakthroughs in machine learning, particularly deep learning. Today, computer vision systems are integral to industries ranging from healthcare and automotive to retail and security, driving automation and enhancing human capabilities.
#History / Background
#Early Foundations (1950s–1960s)
The origins of computer vision trace back to the 1950s, when researchers began exploring ways to automate visual tasks. Early work focused on Optical Character Recognition (OCR), which aimed to digitize printed text. In 1959, David Hubel and Torsten Wiesel conducted groundbreaking research on the visual cortex, laying the groundwork for understanding how biological systems process visual information. By the 1960s, the field saw the development of edge detection algorithms, such as the Sobel operator, which identified boundaries in images. The Shannon-Fano algorithm and other early pattern recognition techniques were also explored during this period.
#The 1970s: Structural Analysis and 3D Reconstruction The 1970s marked a shift toward structural analysis and 3D reconstruction. David Marr, a prominent figure in computer vision, proposed a computational theory of vision in his 1982 book "Vision: A Computational Investigation into the Human Representation and Processing of Visual Information". Marr’s framework emphasized the importance of primitive sketching, 2.5D sketch, and 3D model representation, which influenced subsequent research. During this decade, researchers also began experimenting with stereo vision, which uses multiple cameras to perceive depth, and shape-from-shading techniques to infer 3D structures from 2D images.
#The 1980s–1990s: Rise of Machine Learning and Feature Extraction The 1980s and 1990s saw the integration of machine learning into computer vision. Support Vector Machines (SVMs) and neural networks became popular for tasks like object recognition and classification. PCA (Principal Component Analysis) and SIFT (Scale-Invariant Feature Transform) emerged as key techniques for feature extraction, enabling more robust image matching and recognition. In 1997, Paul Viola and Michael Jones introduced the Viola-Jones object detection framework, a milestone in real-time face detection. This algorithm, based on Haar-like features and cascade classifiers, significantly improved the speed and accuracy of object detection systems.
#The 2000s: The Internet and Big Data Era The proliferation of the internet and digital cameras in the 2000s led to an explosion of visual data. Researchers leveraged large-scale datasets like ImageNet (introduced in 2009) to train more sophisticated models. Bag-of-Visual-Words (BoVW) and latent Dirichlet allocation (LDA) became standard techniques for image classification. The 2006 ImageNet challenge further accelerated progress, with teams competing to classify millions of images into thousands of categories. This period also saw the rise of graph-based methods and sparse coding for visual recognition.
#The 2010s: Deep Learning Revolution The 2010s witnessed a paradigm shift with the advent of deep learning, particularly Convolutional Neural Networks (CNNs). AlexNet (2012), developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, achieved unprecedented accuracy in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), surpassing traditional methods by a significant margin. Subsequent breakthroughs included:
- ResNet (2015): Introduced residual learning to train very deep networks.
- YOLO (You Only Look Once, 2015): Enabled real-time object detection.
- Generative Adversarial Networks (GANs, 2014): Revolutionized image synthesis and style transfer. The availability of GPU computing and open-source frameworks like TensorFlow and PyTorch democratized deep learning, making it accessible to researchers and developers worldwide.
#The 2020s: Multimodal and Real-World Applications Today, computer vision is evolving toward multimodal systems that integrate visual data with other sensory inputs (e.g., text, audio). Vision Transformers (ViTs), introduced in 2020, leverage the Transformer architecture (originally from NLP) to achieve state-of-the-art performance in image classification. Key trends in the 2020s include:
- Self-supervised learning: Reducing reliance on labeled data.
- Edge AI: Deploying lightweight models on edge devices for real-time applications.
- Explainable AI (XAI): Enhancing interpretability of deep learning models.
- Autonomous systems: Advancing self-driving cars, drones, and robotic vision.
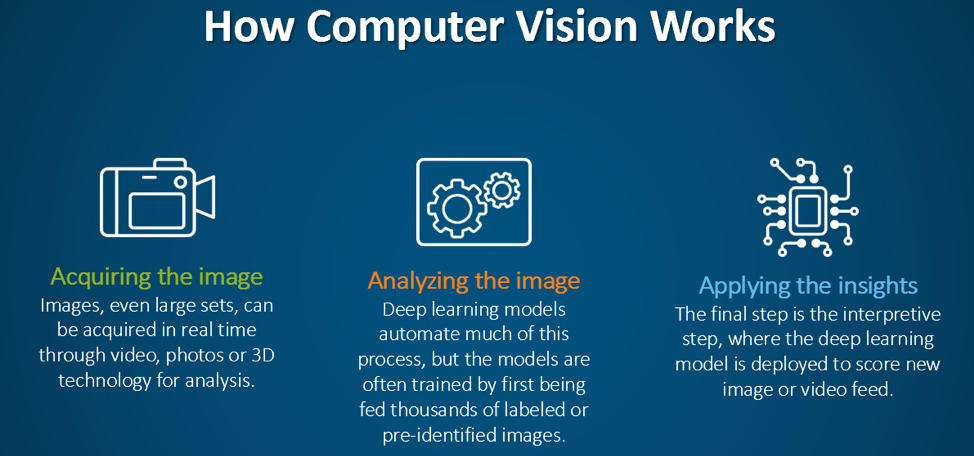
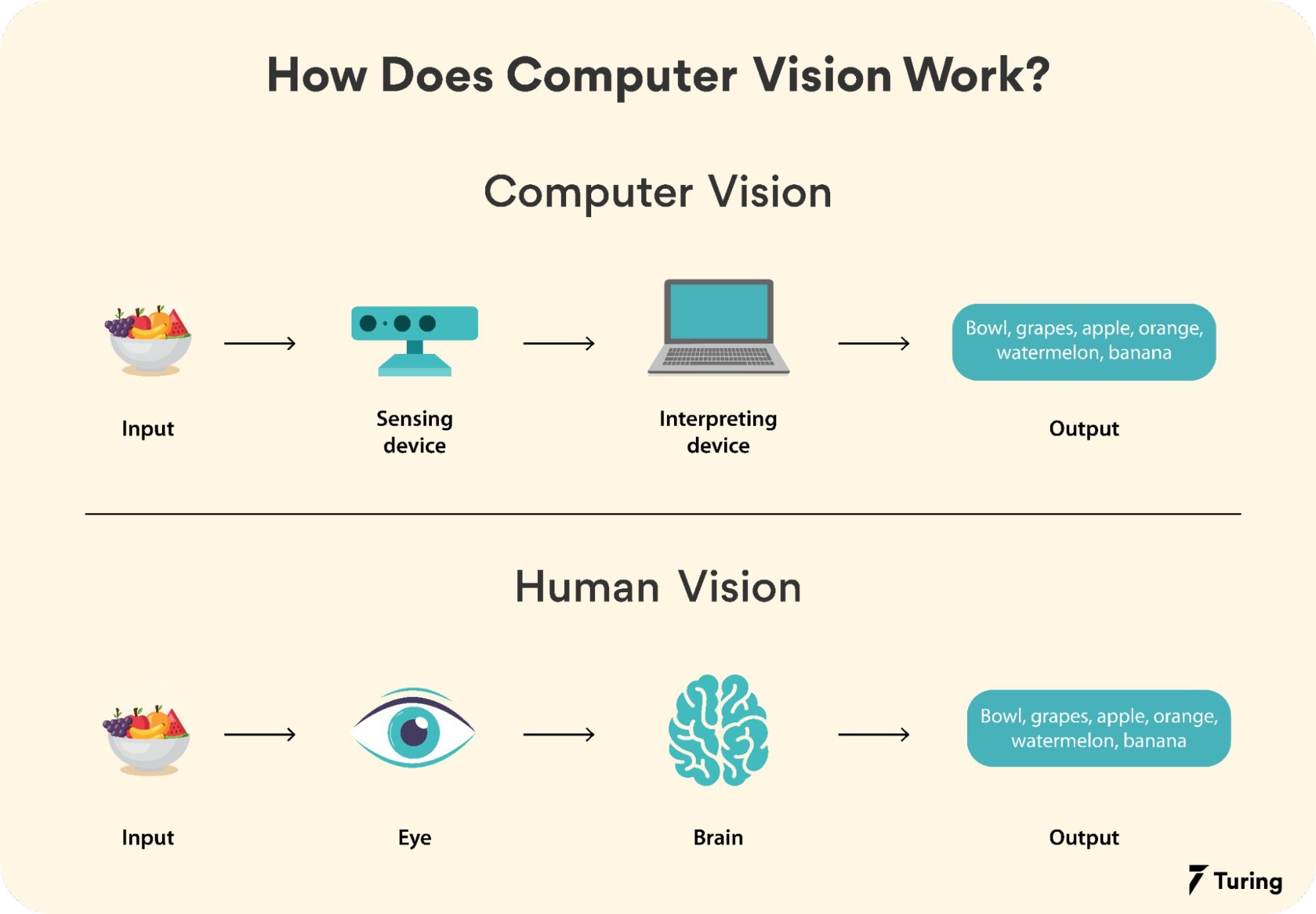
#How It Works
Computer vision systems process visual data through a series of interconnected stages, each designed to extract, analyze, and interpret information. The workflow typically involves:
#
- Image Acquisition Visual data is captured using devices like cameras, LiDAR, or depth sensors. The quality of input (resolution, lighting, noise) directly impacts downstream processing.
#
- Preprocessing Raw images undergo enhancement to improve clarity and reduce noise. Common techniques include:
- Grayscale conversion (for simplicity).
- Noise reduction (e.g., Gaussian blur, median filtering).
- Contrast adjustment (histogram equalization).
- Normalization (scaling pixel values to a standard range).
#
- Feature Extraction Features are distinctive patterns or attributes that help distinguish objects. Traditional methods include:
- Edge detection (Canny, Sobel operators).
- Corner detection (Harris corner detector).
- Texture analysis (Local Binary Patterns).
- Keypoint descriptors (SIFT, SURF, ORB). Modern deep learning approaches, particularly CNNs, automatically learn hierarchical features from raw pixels, eliminating the need for manual feature engineering.
#
- Object Detection and Recognition This stage involves identifying and localizing objects within an image. Techniques include:
- Two-stage detectors (R-CNN, Faster R-CNN): Generate region proposals before classification.
- One-stage detectors (YOLO, SSD): Perform detection in a single pass.
- Semantic segmentation: Assigns a class label to each pixel (e.g., U-Net, Mask R-CNN).
- Instance segmentation: Differentiates between individual objects of the same class.
#
- Scene Understanding Beyond object detection, advanced systems aim to interpret the context of a scene. This includes:
- 3D reconstruction (Structure from Motion, LiDAR).
- Depth estimation (Monocular depth prediction).
- Activity recognition (spatiotemporal analysis of video).
- Captioning and visual question answering (VQA): Generating textual descriptions or answering queries about images.
#
- Decision Making and Action The final output is used to inform decisions or trigger actions. Examples include:
- Autonomous navigation (path planning for robots or self-driving cars).
- Medical diagnosis (identifying tumors in X-rays or MRIs).
- Industrial inspection (detecting defects in manufacturing).
- Augmented Reality (AR): Overlaying digital information on real-world views.
#Important Facts
- Biological Inspiration: Computer vision draws inspiration from the human visual system, particularly the ventral stream (object recognition) and dorsal stream (spatial awareness).
- Computational Cost: Training deep learning models requires significant computational resources, often leveraging GPUs or TPUs (Tensor Processing Units).
- Data Dependency: High-performance models rely on large, labeled datasets (e.g., ImageNet contains over 14 million images).
- Bias and Fairness: Computer vision systems can inherit biases from training data, leading to disparities in performance across demographics or environments.
- Real-Time Processing: Applications like autonomous driving demand low-latency inference, often achieved through model optimization (e.g., quantization, pruning).
- Ethical Concerns: Issues such as privacy invasion (facial recognition), deepfakes, and surveillance raise ethical and regulatory challenges.
- Interdisciplinary Nature: Computer vision intersects with robotics, neuroscience, physics, and cognitive science, fostering collaborative research.
#Timeline
- Foundational ideas
Core concepts and early methods shape Timeline of Computer Vision.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Timeline of Computer Vision cover?
Traces timeline of computer vision, highlighting major milestones, context, examples, and future implications.
Why is Timeline of Computer Vision important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Computer Vision decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Timeline, Computer, Vision before using the ideas in real projects.
#References
- Timeline of Computer Vision terminology and background research
- Timeline of Computer Vision use cases, implementation examples, and limitations
- Computer Vision best practices, standards, and risk guidance
- Timeline case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.