
#Short Answer
Explains how do ai frameworks work?, including the main process, tools, examples, risks, and practical implementation steps.
#Infobox
#Overview
AI frameworks serve as the backbone of modern artificial intelligence and machine learning systems, bridging the gap between theoretical algorithms and practical implementation. These frameworks encapsulate decades of research in numerical computation, optimization, and neural network architectures, allowing developers—regardless of their mathematical expertise—to build sophisticated models with minimal effort. By providing high-level abstractions, AI frameworks democratize AI development, enabling applications in computer vision, natural language processing, robotics, and healthcare. At their core, AI frameworks consist of two primary components:
- Frontend APIs: User-friendly interfaces (often in Python or other high-level languages) that allow developers to define models using intuitive syntax.
- Backend Engines: Optimized computational backends (written in C++, CUDA, or other low-level languages) that execute operations efficiently on hardware accelerators. This dual-layer design ensures both usability and performance, making AI frameworks indispensable tools in both academic research and industrial applications.
#History / Background
The evolution of AI frameworks is closely tied to the progress of machine learning itself, with key milestones reflecting advancements in computational power, algorithmic innovation, and software engineering practices.
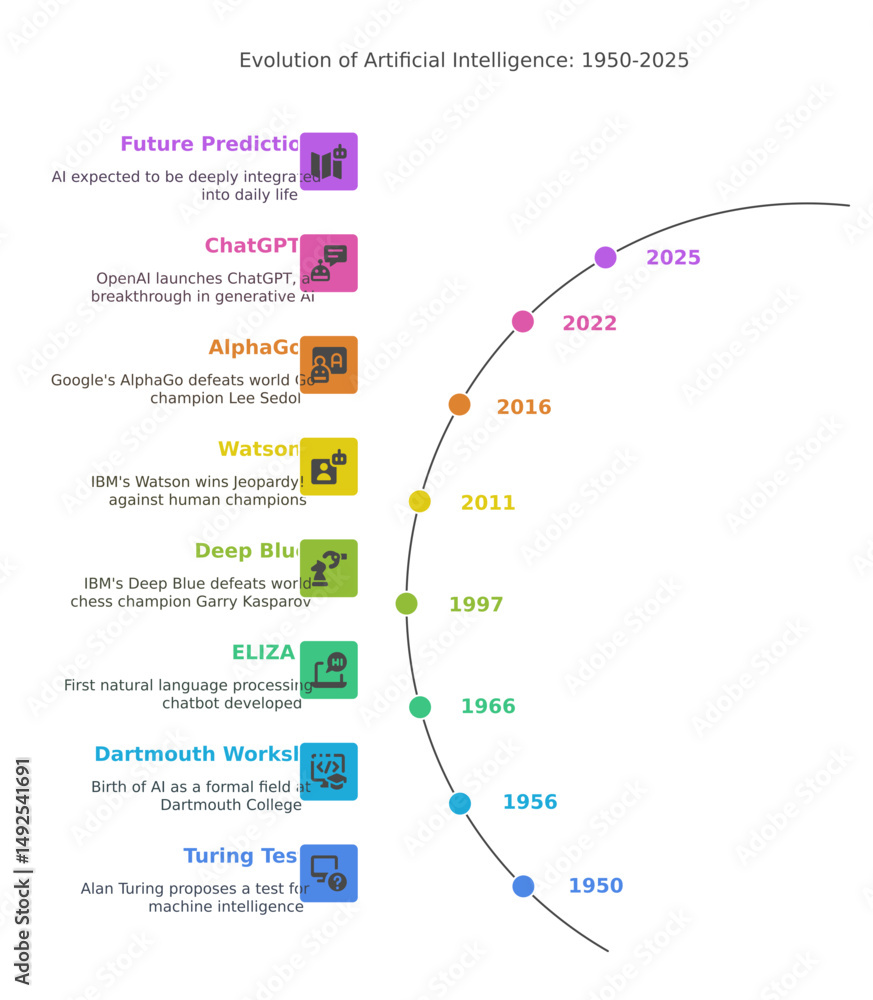
#Early Foundations (1950s–1990s)
The conceptual roots of AI frameworks can be traced back to early AI research, where symbolic AI systems like LISP and Prolog were used to implement rule-based systems. However, these languages lacked the numerical computation capabilities required for modern ML. The 1980s saw the rise of neural network simulators such as SNNS (Stuttgart Neural Network Simulator), which provided basic tools for training simple models.
#The Rise of Numerical Computing (1990s–2000s)
The late 1990s and early 2000s marked a shift toward numerical computing frameworks. MATLAB and R became popular for statistical and linear algebra operations, while Theano (developed in 2007) introduced automatic differentiation—a critical feature for training deep learning models. Theano’s symbolic computation graph allowed users to define complex mathematical expressions that were optimized for execution on GPUs.
#Deep Learning Revolution (2010s–Present)
The breakthrough in deep learning, particularly with the success of convolutional neural networks (CNNs) in image recognition (e.g., AlexNet in 2012), accelerated the development of modern AI frameworks. Key milestones include:
- 2015: TensorFlow (Google Brain) was open-sourced, offering a flexible, scalable framework with support for distributed training.
- 2016: PyTorch (Facebook AI Research) introduced dynamic computation graphs, which improved usability for research and prototyping.
- 2019: JAX (Google) emerged as a high-performance numerical computing library, enabling automatic differentiation and just-in-time compilation.
- 2020s: Frameworks like Hugging Face Transformers, FastAI, and ONNX (Open Neural Network Exchange) expanded capabilities for NLP, transfer learning, and cross-framework model deployment. Today, AI frameworks are integral to both academic research and commercial AI products, with continuous advancements in hardware (e.g., TPUs, neuromorphic chips) driving further innovation.
#How It Works
AI frameworks operate by combining several key technologies to streamline the AI/ML workflow. The process can be broken down into the following stages:
#1. Model Definition Developers define the architecture of an AI model using high-level APIs. For example, in TensorFlow/Keras, a simple neural network might be defined as: python model = tf.keras.Sequential([ tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) This abstraction hides the underlying mathematical operations (e.g., matrix multiplications, activation functions) while allowing customization.
#2. Computation Graph Construction The framework converts the high-level model definition into a computation graph, a directed acyclic graph (DAG) where nodes represent operations (e.g., matrix multiplication, ReLU) and edges represent data flow. This graph is optimized for execution:
- Static Graphs (e.g., TensorFlow): The graph is fixed before execution, enabling optimizations like graph pruning and operator fusion.
- Dynamic Graphs (e.g., PyTorch): The graph is constructed on-the-fly during runtime, offering flexibility for debugging and research.
#3. Automatic Differentiation To train models, frameworks compute gradients (derivatives) of the loss function with respect to model parameters using automatic differentiation. This involves:
- Forward Pass: Computing the model’s output given input data.
- Backward Pass: Propagating errors backward through the graph to update weights via optimization algorithms (e.g., stochastic gradient descent). Frameworks like PyTorch and TensorFlow handle this automatically, eliminating the need for manual gradient calculations.
#4. Hardware Acceleration AI frameworks leverage hardware accelerators to speed up computations:
- GPUs: Parallelize matrix operations (e.g., via CUDA or OpenCL).
- TPUs: Google’s Tensor Processing Units are optimized for tensor operations in deep learning.
- FPGAs: Provide reconfigurable hardware for low-latency inference. Frameworks automatically offload computations to the most suitable hardware, often with minimal user intervention.
#5. Optimization and Compilation Before execution, the computation graph is optimized:
- Operator Fusion: Combining multiple operations into a single kernel (e.g., merging a convolution and ReLU into one GPU kernel).
- Memory Management: Efficiently allocating and deallocating memory for tensors.
- Just-in-Time (JIT) Compilation: Frameworks like JAX or PyTorch 2.0 compile graphs to optimized machine code (e.g., XLA for TensorFlow) for faster execution.
#6. Training and Inference
- Training: The model learns from data by iteratively adjusting parameters to minimize a loss function. Frameworks provide built-in optimizers (e.g., Adam, SGD) and loss functions (e.g., cross-entropy).
- Inference: Once trained, the model is deployed to make predictions on new data. Frameworks support deployment options like TensorFlow Serving, ONNX Runtime, or TorchScript for cross-platform compatibility.
#7. Scalability and Distributed Training For large-scale models, frameworks support distributed training across multiple GPUs or machines:
- Data Parallelism: Splitting data across workers (e.g., TensorFlow’s
MirroredStrategy). - Model Parallelism: Splitting the model across devices (e.g., for very large language models like GPT-3).
- Hybrid Approaches: Combining data and model parallelism (e.g., Megatron-LM for transformer models).
#Important Facts
- Performance vs. Usability Trade-off: Frameworks like PyTorch prioritize flexibility and ease of use, making them ideal for research, while TensorFlow emphasizes production deployment and scalability.
- Hardware Agnosticism: Modern frameworks (e.g., TensorFlow, PyTorch) abstract hardware differences, allowing the same code to run on CPUs, GPUs, or TPUs with minimal changes.
- Reproducibility: Frameworks like JAX and PyTorch support deterministic operations, ensuring reproducible results across runs.
- Interoperability: Tools like ONNX enable models trained in one framework (e.g., PyTorch) to be deployed in another (e.g., TensorFlow Lite).
- Quantization and Pruning: Frameworks support techniques like quantization (reducing model precision to 8-bit integers) and pruning (removing unimportant weights) to optimize models for edge devices.
- AutoML Integration: Some frameworks (e.g., AutoKeras, Google Vertex AI) include automated machine learning (AutoML) features to optimize model architectures and hyperparameters.
- Security: Frameworks implement safeguards against adversarial attacks (e.g., TensorFlow Privacy for differential privacy) and model inversion attacks.
#Timeline
- Foundational ideas
Core concepts and early methods shape How Do AI Frameworks Work?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does How Do AI Frameworks Work? cover?
Explains how do ai frameworks work?, including the main process, tools, examples, risks, and practical implementation steps.
Why is How Do AI Frameworks Work? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how AI Tools decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Do, AI, Frameworks before using the ideas in real projects.
#References
- How Do AI Frameworks Work? terminology and background research
- How Do AI Frameworks Work? use cases, implementation examples, and limitations
- AI Tools best practices, standards, and risk guidance
- Do case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.