
#Short Answer
Covers exploring the basics of computer vision, including core concepts, practical examples, benefits, limitations, and risks in Computer Vision.
#Infobox
#Overview
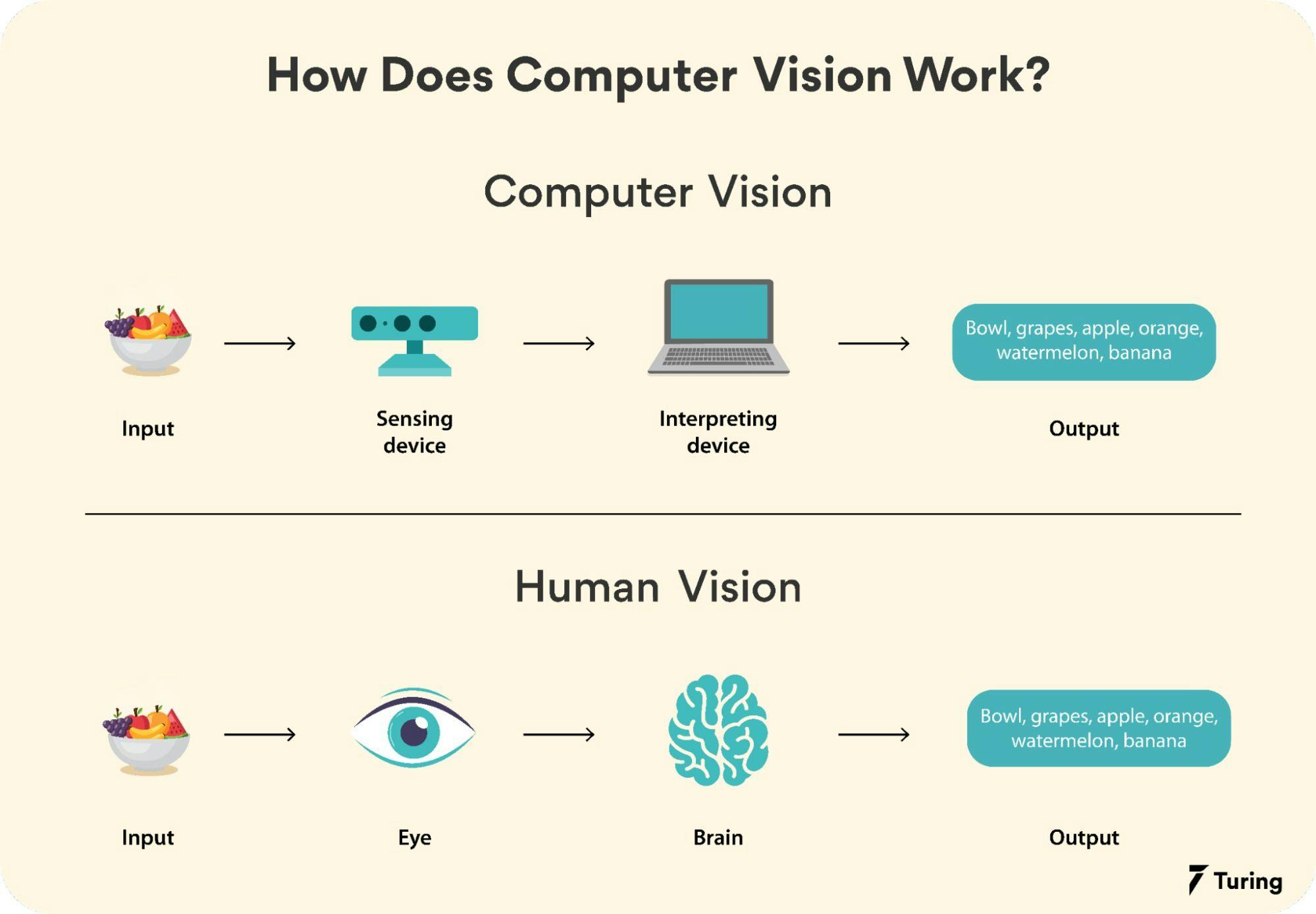
Computer vision is a multidisciplinary field that combines elements of computer science, artificial intelligence, and signal processing to enable machines to derive meaningful information from digital images or videos. Unlike traditional image processing, which focuses on manipulating pixel data, computer vision aims to replicate the human visual system’s ability to recognize, classify, and interpret visual inputs. The primary goal of computer vision is to automate tasks that rely on visual perception, such as facial recognition, autonomous driving, medical imaging, and industrial inspection. By leveraging algorithms and machine learning models, computer vision systems can identify objects, detect anomalies, track movements, and even reconstruct 3D scenes from 2D images.
#History / Background
#Early Foundations (1950s–1970s)
The origins of computer vision trace back to the 1950s and 1960s, when researchers began exploring ways to automate visual tasks. One of the earliest milestones was the development of pattern recognition techniques, which laid the groundwork for later advancements. In 1966, a summer project at MIT, led by Seymour Papert and Marvin Minsky, attempted to create a system that could describe the contents of a scene—a foundational idea in computer vision. During this period, researchers focused on edge detection and feature extraction, using simple algorithms to identify lines and shapes in images. However, computational limitations and the lack of large datasets hindered progress.
#The 1980s–1990s: Rise of Machine Learning The 1980s and 1990s saw significant strides with the integration of machine learning into computer vision. Researchers developed statistical models and neural networks to improve image classification and object recognition. The introduction of Support Vector Machines (SVMs) in the 1990s provided a robust method for separating different classes of visual data. This era also witnessed the emergence of 3D reconstruction techniques, enabling computers to generate 3D models from 2D images—a critical advancement for fields like robotics and medical imaging.
#The 2000s–Present: Deep Learning Revolution The 2000s marked a paradigm shift with the advent of deep learning, particularly Convolutional Neural Networks (CNNs). Proposed by Yann LeCun in the 1990s, CNNs gained prominence after the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012, where a CNN-based model, AlexNet, achieved unprecedented accuracy in image classification. Since then, deep learning has dominated computer vision, enabling breakthroughs in:
- Object detection (e.g., YOLO, Faster R-CNN)
- Semantic segmentation (e.g., U-Net, Mask R-CNN)
- Generative models (e.g., Generative Adversarial Networks for image synthesis)
- Real-time processing (e.g., applications in autonomous vehicles and surveillance)
#How It Works
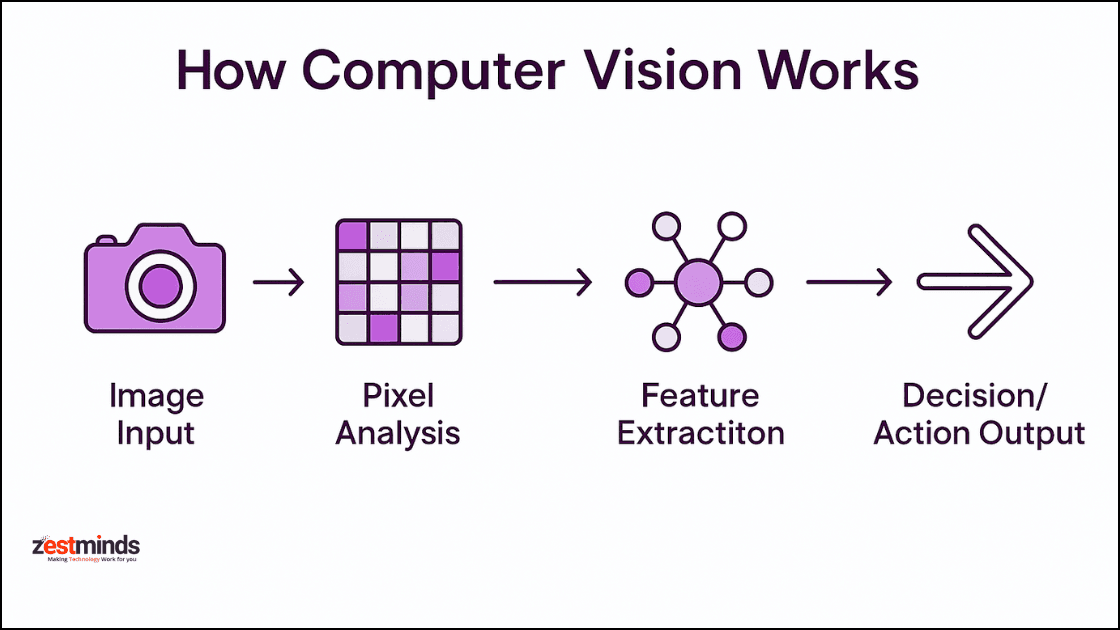
Computer vision systems operate through a series of interconnected steps, from raw image acquisition to high-level interpretation. The process can be broadly divided into the following stages:
#1. Image Acquisition The first step involves capturing visual data using devices like cameras, LiDAR, or medical imaging scanners. The quality of the input directly impacts the system’s performance, so preprocessing techniques such as noise reduction and contrast enhancement are often applied.
#2. Preprocessing Before analysis, images undergo preprocessing to improve clarity and remove distortions. Common techniques include:
- Grayscale conversion (simplifying data by reducing color channels)
- Normalization (scaling pixel values to a standard range)
- Filtering (e.g., Gaussian blur to reduce noise)
- Edge detection (using algorithms like Canny or Sobel to highlight boundaries)
#3. Feature Extraction This step involves identifying key patterns or structures within the image. Traditional methods rely on handcrafted features such as:
- SIFT (Scale-Invariant Feature Transform)
- HOG (Histogram of Oriented Gradients)
- SURF (Speeded-Up Robust Features) Modern systems, however, increasingly use deep learning-based feature extraction, where neural networks automatically learn hierarchical representations of visual data.
#4. Object Detection and Recognition Once features are extracted, the system classifies objects or detects their locations within the image. Techniques include:
- Object detection (identifying and localizing multiple objects, e.g., using YOLO or Faster R-CNN)
- Image segmentation (dividing an image into meaningful regions, e.g., using U-Net)
- Facial recognition (matching faces against a database for identification)
#5. Post-Processing and Decision Making The final step involves refining results and making decisions based on the analysis. This may include:
- Non-maximum suppression (removing duplicate detections)
- Confidence thresholding (filtering low-probability predictions)
- Contextual analysis (using surrounding information to improve accuracy)
#Important Facts
- Human Vision vs. Computer Vision: While humans can recognize objects in milliseconds, computer vision systems require significant computational power, especially for real-time applications.
- Data Dependency: Modern computer vision relies heavily on large labeled datasets (e.g., ImageNet, COCO) for training deep learning models.
- Hardware Acceleration: Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) are essential for training and deploying complex models.
- Ethical Concerns: Issues like privacy invasion (e.g., facial recognition misuse) and bias in datasets (e.g., underrepresentation of certain demographics) are critical challenges.
- Industry Impact: Computer vision is a $25+ billion market, with applications in healthcare, retail, automotive, agriculture, and security.
#Timeline
- Foundational ideas
Core concepts and early methods shape Exploring the Basics of Computer Vision.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Exploring the Basics of Computer Vision cover?
Covers exploring the basics of computer vision, including core concepts, practical examples, benefits, limitations, and risks in Computer Vision.
Why is Exploring the Basics of Computer Vision important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Computer Vision decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Exploring, Basics, Computer before using the ideas in real projects.
#References
- Exploring the Basics of Computer Vision terminology and background research
- Exploring the Basics of Computer Vision use cases, implementation examples, and limitations
- Computer Vision best practices, standards, and risk guidance
- Exploring case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.