
#Short Answer
Debunks common myths about common misconceptions about natural language processing, clarifying capabilities, limitations, risks, and practical expectations.
#Infobox
Common Misconceptions About Natural Language Processing Field Natural language processing Focus Linguistic inaccuracies, technical limitations, and public misunderstandings Key Misconceptions NLP equals human-level understanding, always accurate, only for text, ignores context, requires no data Origin Early computational linguistics (1950s–1960s), popularized by AI advancements (2010s–2020s) Notable Figures Noam Chomsky, John Searle, Marvin Minsky, Geoffrey Hinton
#Overview
Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) focused on the interaction between computers and human language. Despite its advancements, NLP remains prone to misconceptions that distort public and even expert perceptions of its capabilities. These misunderstandings stem from conflating statistical pattern recognition with genuine linguistic comprehension, overestimating system accuracy, and underestimating the complexity of human language.
This article addresses prevalent myths about NLP, including its perceived infallibility, universal applicability, and the notion that it operates independently of human input. By clarifying these misconceptions, the discussion aims to foster a more accurate understanding of NLP's strengths, limitations, and ongoing challenges.
#History / Background
#Early Developments
The origins of NLP trace back to the 1950s, when researchers began exploring the possibility of machines processing human language. Early efforts, such as the Georgetown-IBM experiment in 1954, demonstrated rudimentary machine translation, though results were heavily constrained by linguistic rules and limited computational power. The field was further shaped by the work of Noam Chomsky, whose theories on generative grammar influenced early NLP approaches, emphasizing rule-based systems over statistical methods.
#Shift to Statistical Methods
By the 1990s, the limitations of rule-based systems became apparent, leading to a paradigm shift toward statistical and machine learning approaches. The introduction of Hidden Markov models and later support vector machines enabled systems to learn patterns from large datasets. This era also saw the rise of part-of-speech tagging and named-entity recognition, which improved the accuracy of language processing tasks.
#Deep Learning Era
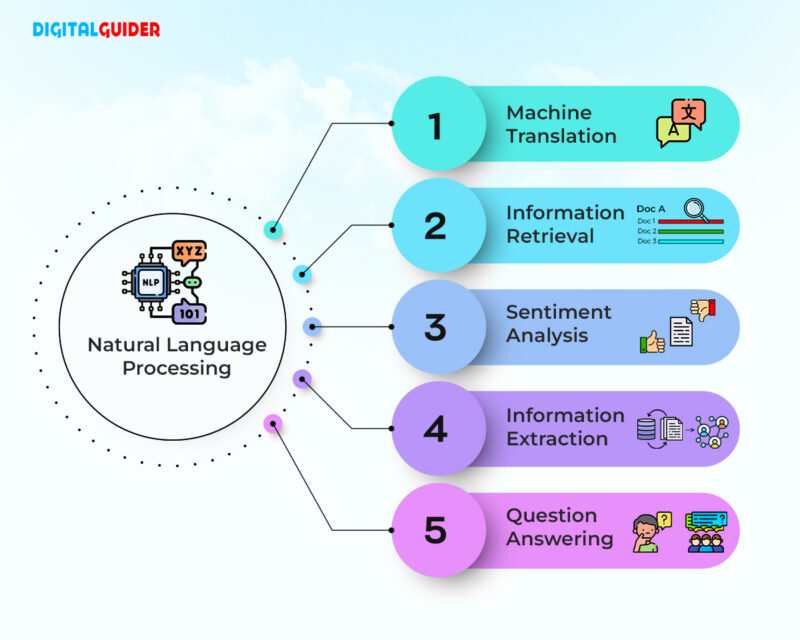
The 2010s marked a revolutionary phase with the advent of deep learning, particularly recurrent neural networks (RNNs) and transformers. Models like BERT and GPT demonstrated unprecedented performance in tasks such as language translation, sentiment analysis, and question answering. However, these advancements also fueled new misconceptions, including the belief that such models possess human-like understanding rather than sophisticated pattern matching.
#How It Works
#Core Principles
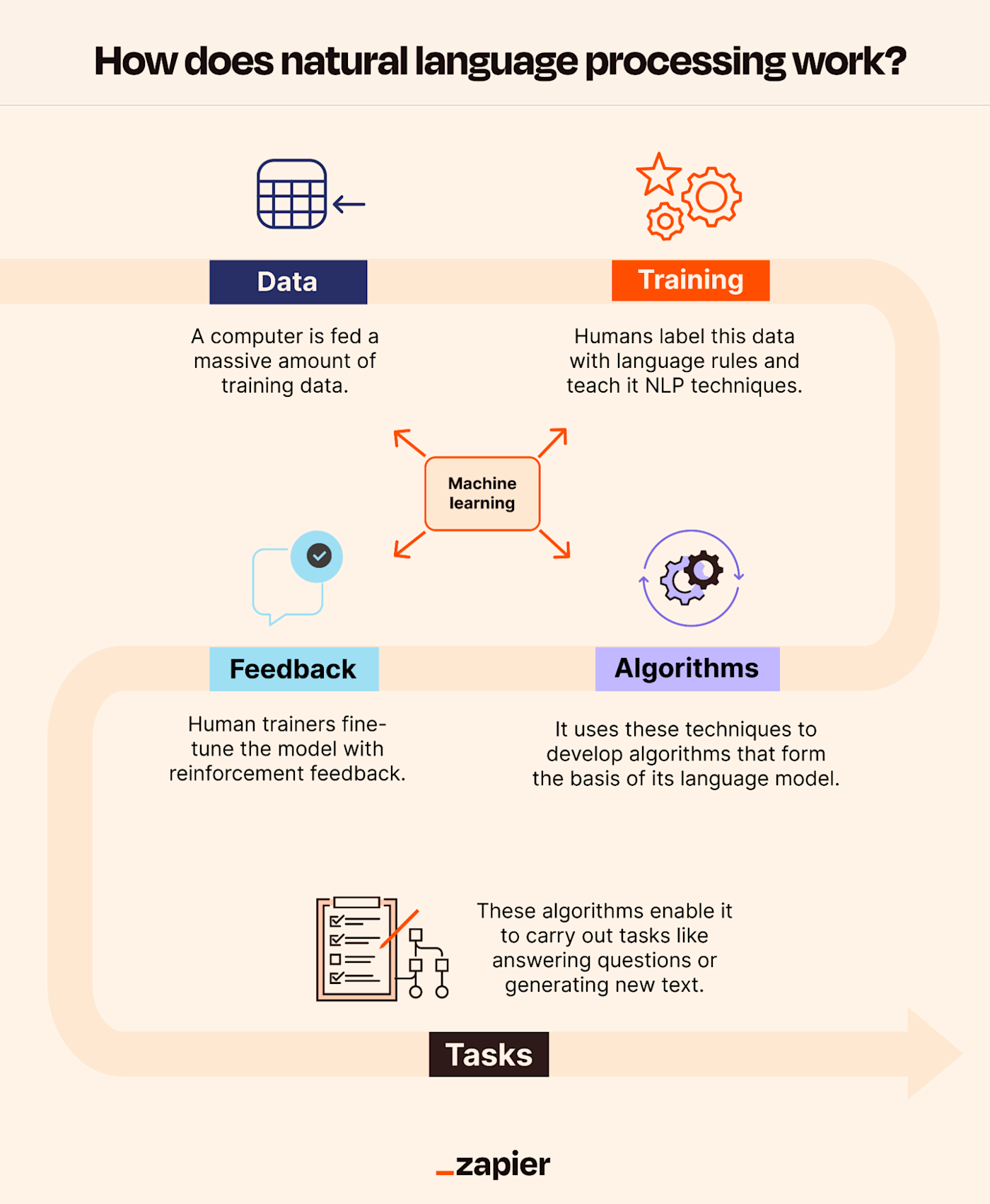
NLP systems operate by converting human language into a format that machines can process. This typically involves several stages: tokenization (breaking text into words or phrases), parsing (analyzing sentence structure), and feature extraction (identifying key elements like nouns or verbs). Modern systems, particularly those using deep learning, rely on neural networks to model relationships between words and predict outcomes based on training data.
#Key Technologies
- Rule-Based Systems: Early NLP relied on predefined linguistic rules, such as grammar and syntax dictionaries. While precise, these systems struggled with ambiguity and scalability.
- Statistical NLP: Introduced in the 1990s, this approach used probabilistic models to infer language patterns from large datasets. It improved accuracy but still faced challenges with context and rare word combinations.
- Machine Learning: Algorithms like Naive Bayes and decision trees enabled systems to learn from data without explicit programming. However, they required substantial labeled datasets.
- Deep Learning: Neural networks, particularly transformers, revolutionized NLP by capturing complex dependencies in language. Models like BERT and GPT-3 leverage vast amounts of text to generate human-like responses, though they lack true comprehension.
#Challenges and Limitations
Despite progress, NLP faces inherent challenges that contribute to common misconceptions:
- Ambiguity: Words and phrases often have multiple meanings (e.g., "bank" as a financial institution or river edge), which machines struggle to disambiguate without context.
- Contextual Understanding: Sarcasm, irony, and cultural references are difficult for NLP systems to interpret accurately.
- Bias in Data: Training data often reflects societal biases, leading to skewed or unfair outputs in applications like hiring or law enforcement.
- Scalability: While deep learning models excel in specific tasks, they require enormous computational resources and energy, limiting accessibility for smaller organizations.
#Important Facts
- NLP ≠ Human Understanding: Despite generating coherent text, NLP models do not possess consciousness, intent, or true comprehension. They predict sequences based on statistical patterns.
- Data Dependency: The performance of NLP systems is directly tied to the quality and quantity of training data. Poor or biased data leads to poor results.
- Contextual Errors: Systems often misinterpret idioms, metaphors, or domain-specific jargon. For example, "kick the bucket" may be taken literally by a machine.
- Ethical Concerns: NLP applications, such as chatbots or automated content generation, can spread misinformation, reinforce stereotypes, or manipulate users if not carefully designed.
- Multilingual Limitations: While some models support multiple languages, their performance varies significantly, with high-resource languages (e.g., English, Mandarin) outperforming low-resource ones (e.g., Swahili, Quechua).
#Timeline
Year Event 1950 Alan Turing proposes the Turing test, laying the groundwork for AI and NLP. 1954 Georgetown-IBM experiment demonstrates the first machine translation system, translating 60 Russian sentences into English. 1966 ELIZA, an early chatbot, simulates conversation by using pattern matching and substitution. 1970s–1980s Rule-based systems dominate NLP, with projects like SHRDLU showcasing limited but structured language understanding. 1990s Shift to statistical methods begins, with the introduction of Hidden Markov models for speech recognition. 2011 IBM Watson wins Jeopardy!, demonstrating advanced NLP in question answering. 2017 Transformer architecture is introduced, enabling models like BERT. 2020 GPT-3 is released, showcasing unprecedented text generation capabilities. 2023 Large language models (LLMs) like GPT-4 and PaLM push the boundaries of NLP, though debates about their limitations persist.
#Related Terms
#FAQ
What does Common Misconceptions About Natural Language Processing cover?
Debunks common myths about common misconceptions about natural language processing, clarifying capabilities, limitations, risks, and practical expectations.
Why is Common Misconceptions About Natural Language Processing important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Language AI decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare the benefits, limitations, data requirements, and related themes such as Myth Busting, Common, Misconception before using the ideas in real projects.
#References
- Common Misconceptions About Natural Language Processing terminology and background research
- Common Misconceptions About Natural Language Processing use cases, implementation examples, and limitations
- Language AI best practices, standards, and risk guidance
- Myth Busting case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.