#Short Answer
Explains What Is K-means Clustering, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
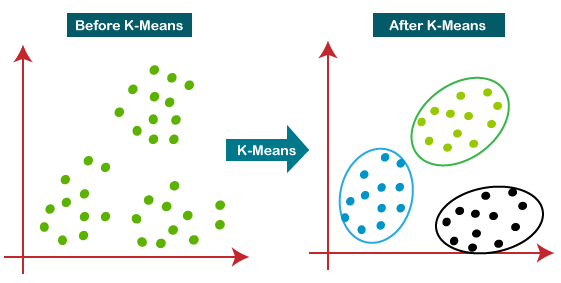
k-Means Clustering is a foundational algorithm in unsupervised machine learning, designed to automatically group unlabeled data into k clusters based on feature similarity. The algorithm iteratively assigns each data point to the nearest cluster centroid and recalculates the centroids until convergence. Unlike supervised learning, k-Means does not require labeled data, making it ideal for exploratory analysis and pattern discovery in large datasets. The core principle of k-Means is to minimize the within-cluster sum of squares (WCSS), also known as the inertia, which measures the compactness of clusters. By reducing WCSS, the algorithm ensures that data points within a cluster are as similar as possible, while points in different clusters are as dissimilar as possible.
#History / Background
The origins of k-Means can be traced to the 1950s, with early contributions from Hugo Steinhaus (1956), who proposed a method for partitioning data into groups, and Edgar Anderson (1958), who introduced the concept of k-means in the context of biological data. However, the algorithm gained prominence in the 1960s and 1970s through the work of James MacQueen (1967), who formalized the iterative centroid-based approach and coined the term "k-Means." Key milestones in the evolution of k-Means include:
- 1965: Edward Forgy and J. A. Hartigan independently developed similar algorithms, with Forgy’s method focusing on iterative centroid updates.
- 1979: Hartigan and Wong introduced the k-Means++ initialization technique, which improves convergence speed and cluster quality by strategically selecting initial centroids.
- 1982: Lloyd’s algorithm (often referred to as the standard k-Means algorithm) was popularized, providing a clear and efficient implementation.
- 2000s: Advances in computational power and big data led to variants like Mini-Batch k-Means, which processes data in smaller batches for scalability. Today, k-Means remains one of the most widely used clustering algorithms due to its simplicity, efficiency, and adaptability across domains.
#How It Works
The k-Means algorithm follows a step-by-step iterative process to partition data into k clusters. Below is a detailed breakdown of the workflow:
#
- Initialization
- Input: A dataset with n data points and d features, and a predefined number of clusters k.
- Centroid Selection:
- Random Initialization: k data points are randomly selected as initial centroids.
- k-Means++ Initialization: A smarter method that spreads out initial centroids to improve convergence. The first centroid is chosen randomly, and subsequent centroids are selected with probability proportional to their squared distance from the nearest existing centroid.
#
- Assignment Step - Each data point is assigned to the nearest centroid based on a distance metric (typically Euclidean distance). - The distance between a point x and centroid c is calculated as: \[ \textDistance(x, c) = \sqrt\sum_i=1^d (x_i - c_i)^2 \]
#
- Update Step - New centroids are computed as the mean of all data points assigned to each cluster. - For cluster j, the new centroid c_j is: \[ c_j = \frac1C_j \sum_x \in C_j x \] where C_j is the set of points in cluster j.
#
- Convergence Check - The algorithm repeats the assignment and update steps until one of the following conditions is met: - The centroids no longer change significantly (i.e., the change in WCSS is below a threshold). - A maximum number of iterations is reached. - The WCSS stabilizes (indicating minimal improvement).
#
- Output - The final clusters, their centroids, and the assignment of each data point to a cluster.
#Important Facts
#Strengths
- Simplicity: Easy to understand and implement.
- Scalability: Efficient for large datasets, especially with optimizations like k-Means++.
- Speed: Typically converges in a small number of iterations.
- Versatility: Applicable to various data types, including numerical, categorical (with encoding), and high-dimensional data.
#Limitations
- Sensitivity to Initialization: Poor initial centroid selection can lead to suboptimal clusters.
- Fixed k: Requires predefining the number of clusters, which may not always be known.
- Spherical Clusters: Assumes clusters are spherical and equally sized; struggles with non-convex or varying-density clusters.
- Outliers: Highly sensitive to outliers, which can skew centroid positions.
- Local Optima: May converge to local minima, necessitating multiple runs with different initializations.
#Distance Metrics While Euclidean distance is the default, other metrics can be used:
- Manhattan Distance: Suitable for high-dimensional data.
- Cosine Similarity: Useful for text or sparse data.
- Mahalanobis Distance: Accounts for feature correlations.
#Preprocessing
- Normalization: Scaling features (e.g., using Min-Max or Z-score) is critical to prevent bias toward high-magnitude features.
- Dimensionality Reduction: Techniques like PCA can improve performance by reducing noise and computational load.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is K-means Clustering?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is K-means Clustering? cover?
Explains What Is K-means Clustering, including the core definition, how it works, practical examples, and limitations.
Why is What Is K-means Clustering? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Artificial Intelligence decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Means, Clustering, AI before using the ideas in real projects.
#References
- What Is K-means Clustering? terminology and background research
- What Is K-means Clustering? use cases, implementation examples, and limitations
- Artificial Intelligence best practices, standards, and risk guidance
- Means case studies, benchmarks, and current industry analysis




Comments
No comments yet. Start the discussion with a useful note.