#Short Answer
Explains What Is Computer Vision, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
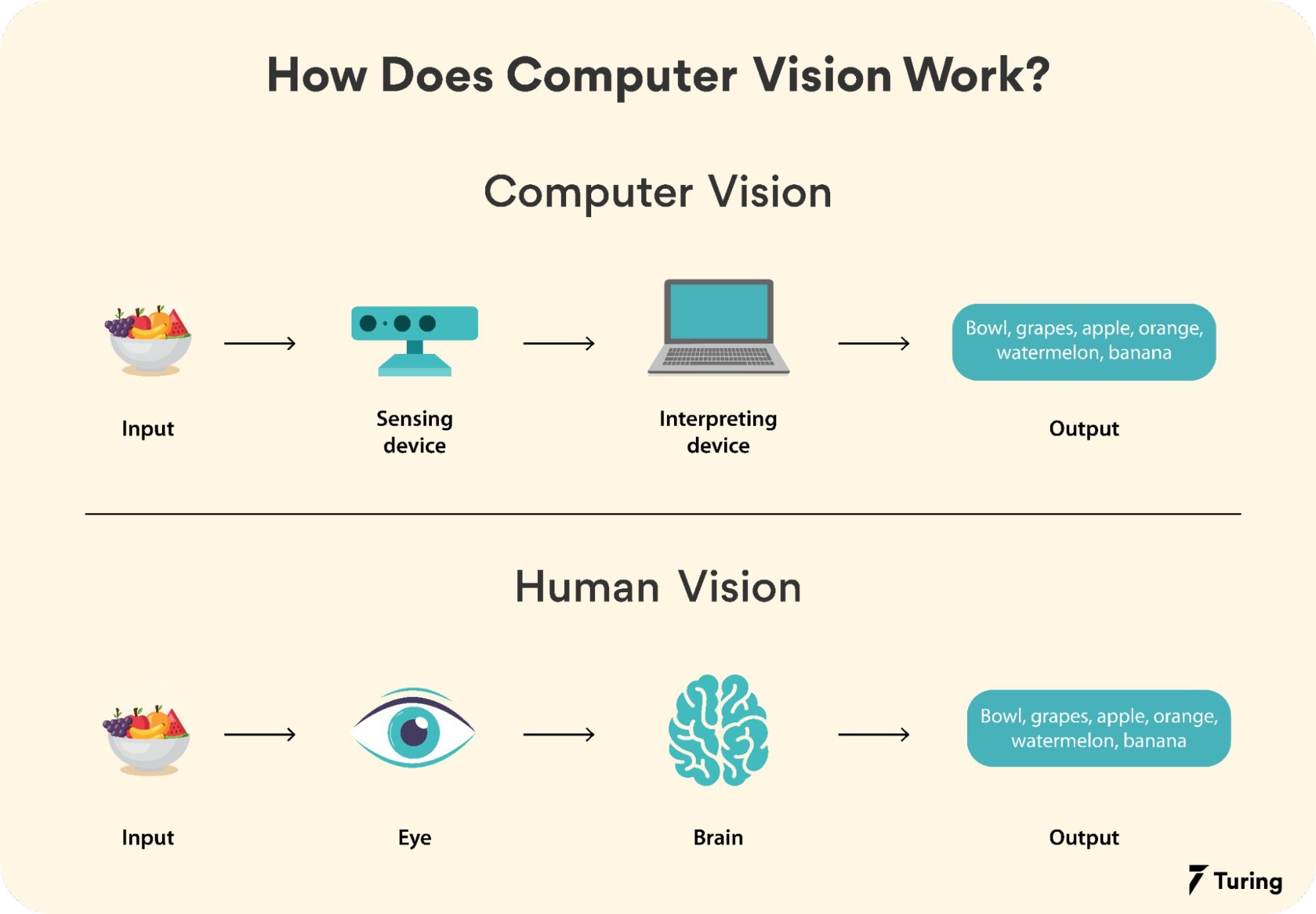
Computer vision is a multidisciplinary field that integrates principles from computer science, mathematics, and cognitive science to enable machines to process and interpret visual data. Unlike traditional image processing, which focuses on manipulating images for human consumption, computer vision aims to extract meaningful information from visual inputs, allowing systems to make decisions or take actions based on what they "see." The field has evolved significantly over the past few decades, driven by advances in computational power, algorithmic innovations, and the availability of large datasets. Today, computer vision powers applications ranging from everyday technologies like smartphone cameras and social media filters to critical systems such as medical diagnostics, surveillance, and autonomous vehicles. At its core, computer vision seeks to replicate the human visual system’s ability to recognize objects, detect patterns, and understand scenes. However, unlike human vision—which is intuitive and context-driven—computer vision relies on mathematical models and algorithms to achieve similar outcomes. This distinction highlights the complexity of the field, as machines must process vast amounts of data to achieve even basic visual tasks.
#History / Background
#Early Foundations (1950s–1970s)
The origins of computer vision can be traced back to the 1950s and 1960s, when researchers began exploring ways to automate visual tasks. One of the earliest milestones was the development of optical character recognition (OCR) systems, which aimed to digitize printed text. In 1959, researchers at the Massachusetts Institute of Technology (MIT) created one of the first OCR systems, capable of reading typed characters. During the 1960s, the field gained momentum with the work of Larry Roberts, often regarded as the "father of computer vision." His 1963 Ph.D. thesis, "Machine Perception of Three-Dimensional Solids," laid the groundwork for understanding how computers could interpret 3D scenes from 2D images. Roberts’ research introduced the concept of block world scenes, where simple geometric shapes were used to study visual perception. The 1970s saw further advancements, including the development of edge detection algorithms (e.g., the Sobel operator) and early attempts at object recognition. However, progress was limited by the computational constraints of the time, as well as the lack of large datasets and sophisticated algorithms.
#The 1980s–1990s: Rise of Machine Learning The 1980s marked a shift toward machine learning approaches in computer vision. Researchers began experimenting with statistical methods to improve image classification and segmentation. One notable development was the introduction of neural networks, inspired by the structure of the human brain. However, these early neural networks were computationally expensive and struggled with scalability. In the 1990s, the field saw the emergence of feature-based methods, such as Scale-Invariant Feature Transform (SIFT) and Speeded-Up Robust Features (SURF), which improved object recognition by identifying distinctive keypoints in images. Additionally, the rise of the internet facilitated the creation of larger datasets, enabling more robust training of vision algorithms.
#The 2000s–2010s: Deep Learning Revolution The 2000s brought about a paradigm shift with the advent of deep learning, a subset of machine learning that uses multi-layered neural networks to process data. The breakthrough came in 2012 when AlexNet, a deep convolutional neural network (CNN), won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) by a significant margin. This event demonstrated the superiority of deep learning over traditional methods and sparked widespread adoption of CNNs in computer vision. Key milestones during this period included:
- 2012: AlexNet’s victory in ILSVRC.
- 2014: Introduction of GoogLeNet and VGGNet, which further improved image classification accuracy.
- 2015: Development of ResNet, which addressed the problem of vanishing gradients in deep networks, enabling training of much deeper models. The proliferation of GPUs (Graphics Processing Units) also played a crucial role in accelerating deep learning research, as these processors were highly efficient at parallel computations required for training neural networks.
#Modern Era
(2020s–Present)
Today, computer vision is a cornerstone of artificial intelligence, with applications spanning nearly every industry. Advances in transformer-based architectures (e.g., Vision Transformers or ViTs) and self-supervised learning have further pushed the boundaries of what machines can achieve. Additionally, the integration of computer vision with other AI technologies, such as natural language processing (NLP) and robotics, has led to innovations like autonomous drones, augmented reality (AR), and smart surveillance systems.
#How It Works
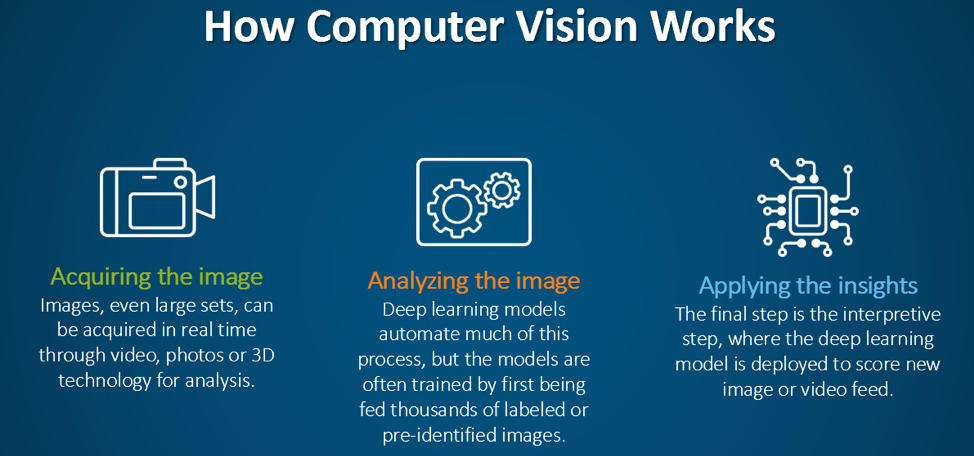
#Core Principles Computer vision systems operate by breaking down visual data into manageable components and extracting meaningful features. The process typically involves several key steps:
- Image Acquisition: Capturing visual data using cameras, sensors, or other input devices.
- Preprocessing: Enhancing image quality by reducing noise, normalizing brightness, and correcting distortions.
- Feature Extraction: Identifying relevant patterns, edges, textures, or shapes within the image.
- Object Recognition/Detection: Classifying objects or detecting their presence and location within the image.
- Post-Processing: Refining results through techniques like non-maximum suppression or contextual analysis.
#Key Techniques
and Algorithms
1. Traditional Methods Before the deep learning era, computer vision relied on handcrafted features and statistical models:
- Edge Detection: Algorithms like Canny or Sobel identify boundaries between objects.
- Feature Matching: Techniques such as SIFT or ORB compare keypoints across images for tasks like image stitching or object tracking.
- Segmentation: Methods like k-means clustering or graph cuts divide an image into meaningful regions.
2. Deep Learning Approaches Modern computer vision predominantly uses deep learning, particularly convolutional neural networks (CNNs), which are designed to process grid-like data (e.g., images). Key components include:
- Convolutional Layers: Apply filters to detect local features (e.g., edges, textures).
- Pooling Layers: Reduce spatial dimensions to decrease computational load and control overfitting.
- Fully Connected Layers: Perform high-level reasoning and classification. Popular CNN architectures include:
- AlexNet (2012): Pioneered deep CNNs for image classification.
- ResNet (2015): Introduced residual connections to train deeper networks.
- YOLO (You Only Look Once) (2015): Enables real-time object detection by processing the entire image in a single pass.
3. Advanced Techniques Recent advancements have introduced novel approaches:
- Transformers in Vision: Vision Transformers (ViTs) apply transformer architectures (originally designed for NLP) to image processing, achieving state-of-the-art results in tasks like image classification.
- Generative Models: Generative Adversarial Networks (GANs) and Diffusion Models are used for image synthesis, super-resolution, and data augmentation.
- Self-Supervised Learning: Techniques like contrastive learning (e.g., SimCLR) enable models to learn from unlabeled data, reducing the need for large annotated datasets.
#Applications of Computer Vision
| Application | Description | Example Use Cases | |-------------------------------|---------------------------------------------------------------------------------|-----------------------------------------------| | Object Detection | Identifying and localizing objects within an image or video. | Autonomous vehicles, retail inventory tracking | | Facial Recognition | Detecting and recognizing human faces for identification or authentication. | Security systems, smartphone unlocking | | Medical Imaging | Analyzing medical scans (e.g., X-rays, MRIs) for disease diagnosis. | Tumor detection, radiology assistance | | Augmented Reality (AR) | Overlaying digital information onto the real world. | Snapchat filters, Pokémon GO | | Autonomous Systems | Enabling machines to navigate and interact with their environment. | Self-driving cars, drones | | Image Segmentation | Partitioning an image into segments for detailed analysis. | Satellite imagery, agricultural monitoring | | Optical Character Recognition (OCR) | Converting different types of documents (e.g., scanned paper, PDFs) into editable and searchable data. | Digitizing books, extracting text from images |
#Important Facts
- Human vs. Machine Vision: While humans can recognize objects in milliseconds with minimal effort, computer vision systems require millions of labeled images and significant computational resources to achieve similar accuracy.
- Data Dependency: The performance of modern computer vision models is heavily reliant on the quality and quantity of training data. Biases in datasets can lead to inaccurate or unfair outcomes.
- Real-Time Processing: Advances in hardware (e.g., Tensor Processing Units (TPUs)) and algorithms have enabled real-time applications, such as live video analysis and autonomous driving.
- Ethical Concerns: Computer vision raises ethical issues, including privacy violations (e.g., facial recognition in public spaces), bias in algorithms, and misuse in surveillance.
- Energy Consumption: Training large deep learning models for computer vision can consume significant energy, contributing to environmental concerns. Efforts are underway to develop more efficient models (e.g., quantization, pruning).
- Interdisciplinary Nature: Computer vision intersects with fields like robotics (for navigation), medicine (for diagnostics), and artificial intelligence (for decision-making).
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is Computer Vision?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is Computer Vision? cover?
Explains What Is Computer Vision, including the core definition, how it works, practical examples, and limitations.
Why is What Is Computer Vision? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Computer Vision decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Computer, Vision, AI before using the ideas in real projects.
#References
- What Is Computer Vision? terminology and background research
- What Is Computer Vision? use cases, implementation examples, and limitations
- Computer Vision best practices, standards, and risk guidance
- Computer case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.