#Short Answer
Covers step-by-step guide to ai model evaluation, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
#Infobox
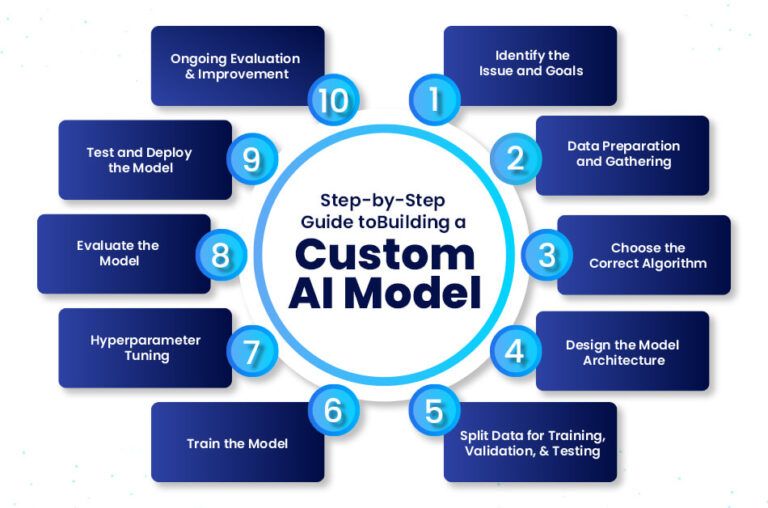
#How It Works
- Data Preparation
Before evaluation, data must be split into distinct subsets:
- Training Set: Used to train the model.
- Validation Set: Used for hyperparameter tuning and intermediate evaluation.
- Test Set: Reserved for final performance assessment to simulate real-world conditions. Techniques like stratified sampling ensure balanced class distribution in classification tasks.
- Metric Selection
The choice of evaluation metrics depends on the problem type:
- Classification:
- Accuracy: Overall correctness (suitable for balanced datasets).
- Precision: Proportion of true positives among predicted positives.
- Recall (Sensitivity): Proportion of true positives correctly identified.
- F1-Score: Harmonic mean of precision and recall.
- ROC-AUC: Measures the model’s ability to distinguish between classes.
- Regression:
- Mean Squared Error (MSE): Average squared difference between predicted and actual values.
- Root Mean Squared Error (RMSE): Square root of MSE for interpretability.
- R² Score: Proportion of variance explained by the model.
- Clustering:
- Silhouette Score: Measures cohesion and separation of clusters.
- Adjusted Rand Index (ARI): Compares clustering results to ground truth.
- Cross-Validation
K-fold cross-validation divides the dataset into k subsets, training the model k times on different combinations of subsets to reduce variance in performance estimates. Leave-one-out cross-validation (LOOCV) is an extreme case where k equals the number of data points.
- Bias-Variance Tradeoff Analysis
- High Bias (Underfitting): Model is too simple, missing patterns in data.
- High Variance (Overfitting): Model is too complex, capturing noise in training data. Techniques like regularization (L1/L2), dropout (for neural networks), and early stopping mitigate these issues.
- Benchmarking
Models are compared against baselines (e.g., random guessing, simple heuristics) and state-of-the-art (SOTA) models to contextualize performance. Leaderboards (e.g., Kaggle competitions) provide standardized benchmarks.
- Error Analysis
Examining misclassified samples or high-error predictions helps identify systematic biases or data quality issues. Tools like confusion matrices and SHAP values (for interpretability) aid in diagnosis.
- Deployment Readiness
Final evaluation ensures the model meets business or application-specific thresholds (e.g., latency, interpretability). A/B testing may be used to compare the model against existing systems in production.
#Important Facts
- No Free Lunch Theorem: No single model performs best across all possible datasets. Evaluation must be problem-specific.
- Data Leakage: Including test data in training (e.g., improper preprocessing) inflates performance metrics, leading to misleading results.
- Class Imbalance: Metrics like accuracy can be misleading for imbalanced datasets. Precision, recall, and F1-score are more informative.
- Reproducibility: Random seeds, data splits, and code versioning ensure consistent evaluation across runs.
- Ethical Considerations: Evaluation must account for fairness (e.g., demographic parity, equalized odds) to avoid biased outcomes.
- Explainability: Models like deep neural networks require post-hoc explainability tools (e.g., LIME, SHAP) to interpret decisions.
- Scalability: Large models (e.g., LLMs) may require distributed evaluation frameworks (e.g., Ray, Dask).
#Timeline
- Foundational ideas
Core concepts and early methods shape Step-by-step Guide to AI Model Evaluation.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Step-by-step Guide to AI Model Evaluation cover?
Covers step-by-step guide to ai model evaluation, including core concepts, practical examples, benefits, limitations, and risks in Machine Learning.
Why is Step-by-step Guide to AI Model Evaluation important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as AI, Model, Evaluation before using the ideas in real projects.
#References
- Step-by-step Guide to AI Model Evaluation terminology and background research
- Step-by-step Guide to AI Model Evaluation use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- AI case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.