#Short Answer
Explains What Is a Support Vector Machine (svm), including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
A Support Vector Machine (SVM) is a powerful machine learning model designed to analyze data for classification and regression tasks. Unlike traditional algorithms that focus on minimizing error, SVMs aim to find the optimal decision boundary—known as the hyperplane—that maximizes the margin between different classes of data points. This approach enhances generalization and reduces overfitting, making SVMs highly effective in high-dimensional spaces. SVMs are particularly well-suited for scenarios where the number of features exceeds the number of samples, a common challenge in fields like genomics and text mining. By leveraging the kernel trick, SVMs can transform non-linear data into a higher-dimensional space where a linear separation becomes possible, thereby handling complex datasets efficiently.
#History / Background
The foundations of Support Vector Machines trace back to the 1960s, rooted in the work of Vladimir Vapnik and Alexey Chervonenkis on statistical learning theory. Their research introduced the concept of Vapnik-Chervonenkis (VC) dimension, a measure of model complexity that later became central to SVM development. The modern formulation of SVMs emerged in 1992 when Vapnik, along with Bernhard Boser and Isabelle Guyon, published a seminal paper introducing the soft-margin classifier. This innovation addressed the limitations of hard-margin SVMs, which required perfectly separable data. The introduction of the slack variable allowed SVMs to handle noisy data and overlapping classes by tolerating minor misclassifications. During the late 1990s and early 2000s, SVMs gained widespread adoption due to their robustness and performance in high-dimensional spaces. Researchers extended the algorithm to support regression tasks (Support Vector Regression, SVR) and introduced kernel functions like the Radial Basis Function (RBF) and polynomial kernel, enabling non-linear classification. Today, SVMs remain a cornerstone in machine learning, with applications spanning from medical diagnosis to financial forecasting. Their theoretical elegance and practical efficacy continue to inspire advancements in kernel methods and optimization techniques.
#How It Works
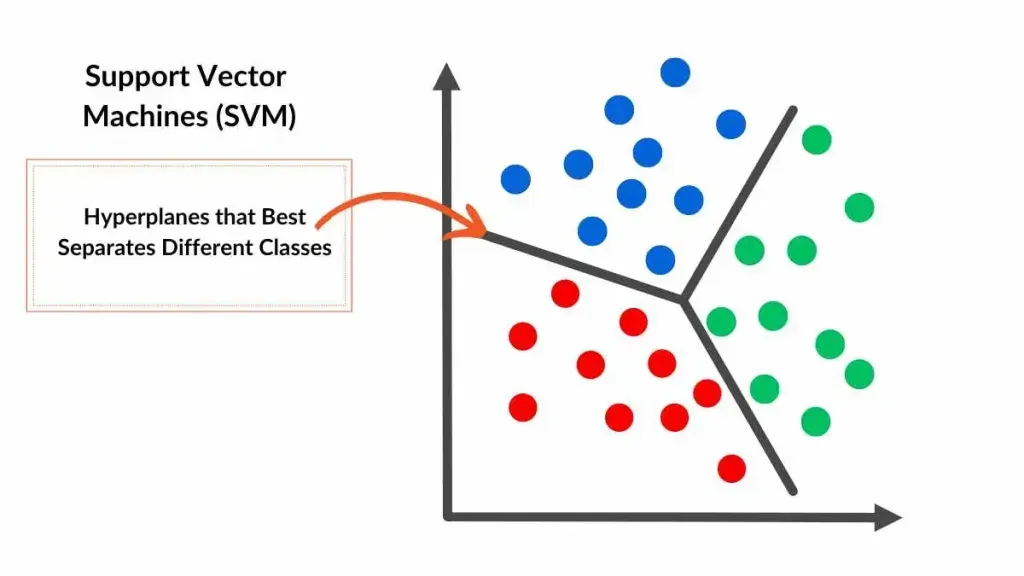
#Core Concept: The Hyperplane At its core, an SVM seeks to find the optimal hyperplane that best separates data points belonging to different classes. In a two-dimensional space, this hyperplane is a line; in three dimensions, it’s a plane; and in higher dimensions, it’s a hyperplane. The goal is to maximize the margin—the distance between the hyperplane and the nearest data points from each class, known as support vectors.
#Margin Maximization The margin is critical because it enhances the model’s ability to generalize to unseen data. A larger margin implies a lower risk of overfitting, as the decision boundary is less sensitive to minor fluctuations in the training data. The support vectors are the data points that lie closest to the hyperplane and directly influence its position.
#Mathematical Formulation For a linearly separable dataset, the SVM optimization problem can be expressed as: \[ \min_w, b \frac12 |w|^2 \quad \textsubject to \quad y_i (w \cdot x_i + b) \geq 1 \quad \forall i \] where: - ( w ) is the weight vector, - ( b ) is the bias term, - ( x_i ) are the input features, - ( y_i ) are the class labels (typically +1 or -1).
#Soft-Margin SVM Real-world data is rarely perfectly separable. To handle overlapping classes and noise, the soft-margin SVM introduces slack variables (( \xi_i )) that allow for misclassifications while penalizing them via a regularization parameter ( C ): \[ \min_w, b, \xi \frac12 |w|^2 + C \sum_i=1^n \xi_i \quad \textsubject to \quad y_i (w \cdot x_i + b) \geq 1 - \xi_i, \quad \xi_i \geq 0 \] The parameter ( C ) controls the trade-off between maximizing the margin and minimizing classification errors.
#Kernel Trick When data is not linearly separable, SVMs employ the kernel trick to map input features into a higher-dimensional space where separation becomes feasible. Common kernel functions include:
- Linear Kernel: ( K(x_i, x_j) = x_i \cdot x_j )
- Polynomial Kernel: ( K(x_i, x_j) = (x_i \cdot x_j + c)^d )
- Radial Basis Function (RBF) Kernel: ( K(x_i, x_j) = \exp(-\gamma |x_i - x_j|^2) )
- Sigmoid Kernel: ( K(x_i, x_j) = \tanh(\alpha x_i \cdot x_j + c) ) The choice of kernel and its parameters (e.g., ( \gamma ) in RBF) significantly impacts SVM performance and must be tuned via cross-validation.
#Training and Prediction During training, the SVM solves a quadratic programming (QP) problem to identify the support vectors and determine the optimal hyperplane. Once trained, the model uses the support vectors and kernel function to classify new, unseen data points by computing their position relative to the hyperplane.
#Important Facts
- High-Dimensional Efficiency: SVMs perform well even when the number of features is much larger than the number of samples, making them ideal for text classification and genomics.
- Kernel Flexibility: The ability to use different kernel functions allows SVMs to model complex, non-linear relationships in data.
- Global Optimum: Unlike neural networks, which may converge to local minima, SVMs solve a convex optimization problem, ensuring a globally optimal solution.
- Robustness to Overfitting: By maximizing the margin, SVMs inherently reduce the risk of overfitting, especially in high-dimensional spaces.
- Interpretability: The support vectors provide insight into which data points are most critical for classification, aiding in model interpretability.
- Computational Complexity: Training an SVM can be computationally expensive, particularly for large datasets, due to the QP problem’s complexity.
- Sensitivity to Parameter Tuning: Performance heavily depends on the choice of kernel and hyperparameters (e.g., ( C ), ( \gamma )), requiring careful tuning.
- Versatility: SVMs can be adapted for regression (SVR), anomaly detection (One-Class SVM), and multi-class classification (via strategies like one-vs-one or one-vs-rest).
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a Support Vector Machine (svm)?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a Support Vector Machine (svm)? cover?
Explains What Is a Support Vector Machine (svm), including the core definition, how it works, practical examples, and limitations.
Why is What Is a Support Vector Machine (svm)? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Artificial Intelligence decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Support, Vector, Machine before using the ideas in real projects.
#References
- What Is a Support Vector Machine (svm)? terminology and background research
- What Is a Support Vector Machine (svm)? use cases, implementation examples, and limitations
- Artificial Intelligence best practices, standards, and risk guidance
- Support case studies, benchmarks, and current industry analysis



Comments
No comments yet. Start the discussion with a useful note.