#Short Answer
Explains What Is a Loss Function, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
A loss function, also known as a cost function or objective function, is a fundamental concept in machine learning and statistical modeling. It provides a quantitative measure of how well a model's predictions align with the true values in the training data. The primary objective of a loss function is to guide the learning algorithm toward minimizing prediction errors, thereby improving the model's generalization to unseen data. In supervised learning, where models are trained on labeled datasets, the loss function evaluates the discrepancy between predicted outputs (e.g., regression values or class probabilities) and the ground truth labels. By minimizing this discrepancy, the model adjusts its parameters (e.g., weights in a neural network) to better capture underlying patterns in the data. Loss functions are not limited to regression tasks; they are also essential in classification problems, where they measure the difference between predicted class probabilities and actual class labels. For instance, in binary classification, the cross-entropy loss penalizes incorrect predictions more severely than correct ones, encouraging the model to output confident and accurate probabilities.
#History / Background
The concept of loss functions has evolved alongside the development of statistical learning and optimization techniques. Early foundations can be traced back to the 18th and 19th centuries, with contributions from mathematicians and statisticians who sought to quantify errors in predictions.
- 18th Century: Early work by mathematicians like Pierre-Simon Laplace and Carl Friedrich Gauss introduced the idea of minimizing squared errors, leading to the development of the least squares method. This method, formalized by Gauss in the early 1800s, became a cornerstone for regression analysis and remains widely used today.
- Early 20th Century: The field of statistical decision theory, pioneered by Abraham Wald and others, formalized the notion of loss functions as a way to quantify the cost of incorrect decisions. This framework laid the groundwork for modern machine learning.
- 1950s–1960s: The rise of artificial intelligence and computational learning brought renewed interest in loss functions. Researchers like Frank Rosenblatt, who developed the perceptron algorithm, used loss-like functions to train early neural networks.
- 1980s–1990s: The advent of backpropagation and deep learning popularized differentiable loss functions, such as mean squared error (MSE) and cross-entropy loss, which could be optimized using gradient descent. This period saw the development of more sophisticated loss functions tailored to specific tasks, such as hinge loss for support vector machines (SVMs).
- 21st Century: With the explosion of big data and deep learning, loss functions have become even more specialized. Modern applications include contrastive loss for similarity learning, triplet loss for face recognition, and adversarial loss for generative models like GANs (Generative Adversarial Networks).
#How It Works
#Core Mechanism A loss function operates by taking two inputs:
- Predicted Output: The value generated by the model (e.g., a regression prediction or a class probability).
- True Output: The actual observed value from the training data. The function then computes a scalar value representing the "loss" or "cost" associated with the prediction. The goal of training is to minimize this loss by adjusting the model's parameters.
#Mathematical Formulation For a dataset with ( n ) samples, the loss function ( L ) is typically defined as the average loss over all samples: \[ L(\theta) = \frac1n \sum_i=1^n \ell(y_i, \haty_i; \theta) \] where: - ( \theta ) represents the model parameters. - ( y_i ) is the true value for the ( i )-th sample. - ( \haty_i ) is the predicted value for the ( i )-th sample. - ( \ell ) is the per-sample loss function (e.g., squared error, cross-entropy).
#Gradient Descent and Optimization To minimize the loss, optimization algorithms like gradient descent compute the gradient of the loss function with respect to the model parameters. The gradient indicates the direction in which the loss increases most rapidly, so the parameters are updated in the opposite direction to reduce the loss: \[ \theta \leftarrow \theta - \eta \nabla_\theta L(\theta) \] where: - ( \eta ) is the learning rate, a hyperparameter controlling the step size. - ( \nabla_\theta L(\theta) ) is the gradient of the loss function.
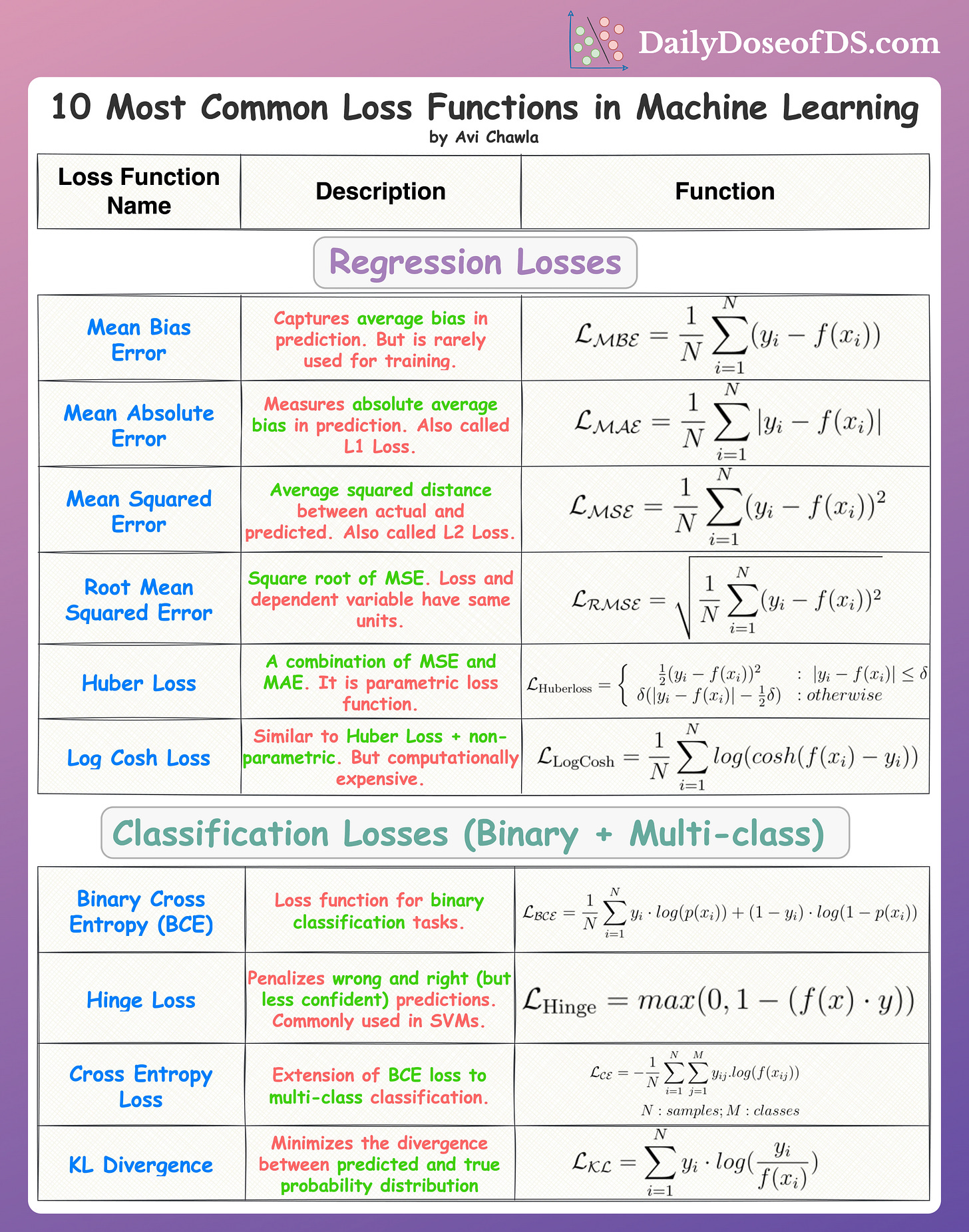
#Common Loss Functions
- Mean Squared Error (MSE) - Used in regression tasks. - Formula: ( \textMSE = \frac1n \sum_i=1^n (y_i - \haty_i)^2 ). - Sensitive to outliers due to the squaring operation.
- Mean Absolute Error (MAE) - Another regression loss, less sensitive to outliers than MSE. - Formula: ( \textMAE = \frac1n \sum_i=1^n |y_i - \haty_i| ).
- Cross-Entropy Loss - Used in classification tasks, especially for probabilistic outputs. - Formula (binary): ( \textCE = -[y \log(\haty) + (1-y) \log(1-\haty)] ). - Formula (multiclass): ( \textCE = -\sum_i=1^C y_i \log(\haty_i) ), where ( C ) is the number of classes.
- Hinge Loss - Commonly used in SVMs for classification. - Formula: ( \textHinge = \max(0, 1 - y \cdot \haty) ), where ( y \in -1, 1\ ).
- Huber Loss - A robust loss function that combines MSE and MAE. - Less sensitive to outliers than MSE but differentiable everywhere.
- Kullback-Leibler (KL) Divergence - Measures the difference between two probability distributions. - Used in variational autoencoders (VAEs) and reinforcement learning.
#Important Facts
- Differentiability: Most loss functions used in deep learning are differentiable, enabling the use of gradient-based optimization methods like gradient descent.
- Robustness: Some loss functions (e.g., Huber loss) are designed to be robust to outliers, improving model performance in noisy datasets.
- Regularization: Loss functions can be combined with regularization terms (e.g., L1 or L2 penalties) to prevent overfitting. For example, the elastic net loss combines L1 and L2 regularization.
- Task-Specific Design: Loss functions are often tailored to specific tasks. For instance, contrastive loss is used in siamese networks for similarity learning, while triplet loss is used in face recognition.
- Imbalanced Data: In classification, loss functions like focal loss down-weight well-classified examples, addressing class imbalance by focusing on hard-to-classify samples.
- Multi-Task Learning: Some models use compound loss functions that combine losses from multiple tasks (e.g., object detection and segmentation in computer vision).
- Interpretability: While loss functions provide a numerical measure of error, they do not always offer interpretability. Some advanced models (e.g., Bayesian neural networks) incorporate uncertainty into the loss function.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a Loss Function?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a Loss Function? cover?
Explains What Is a Loss Function, including the core definition, how it works, practical examples, and limitations.
Why is What Is a Loss Function? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Artificial Intelligence decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Loss, Function, AI before using the ideas in real projects.
#References
- What Is a Loss Function? terminology and background research
- What Is a Loss Function? use cases, implementation examples, and limitations
- Artificial Intelligence best practices, standards, and risk guidance
- Loss case studies, benchmarks, and current industry analysis




Comments
No comments yet. Start the discussion with a useful note.