#Short Answer
Explains What Is a Decision Tree, including the core definition, how it works, practical examples, and limitations.
#Infobox
#Overview
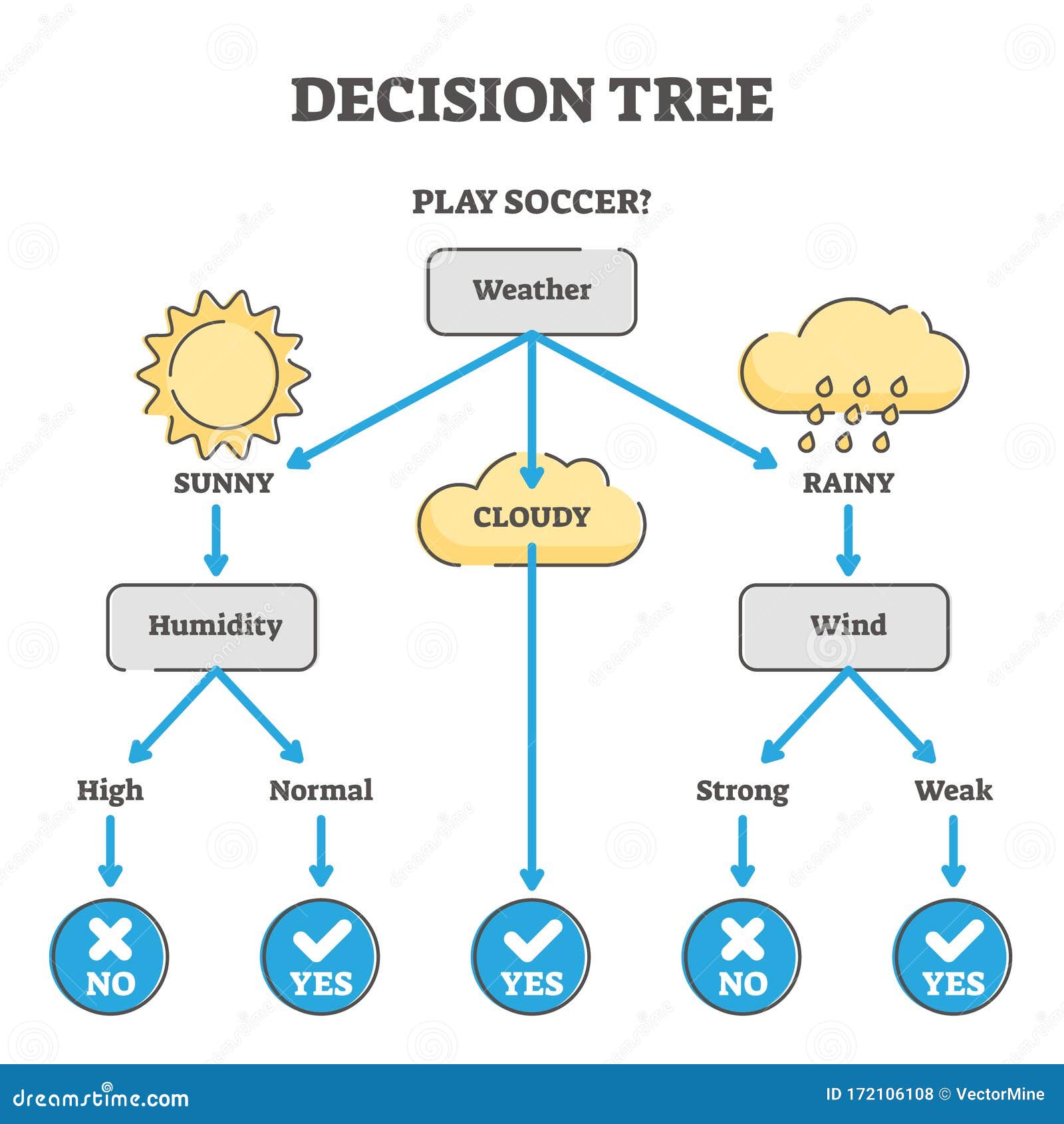
A decision tree is a flowchart-like structure where each internal node represents a decision based on an attribute, each branch denotes an outcome of that decision, and each leaf node corresponds to a final prediction or classification. The algorithm recursively partitions the dataset into subsets based on the most significant attribute at each step, aiming to maximize information gain or minimize impurity (e.g., Gini impurity or entropy in classification). Decision trees are widely used in machine learning due to their simplicity and interpretability. Unlike black-box models (e.g., neural networks), decision trees provide transparent reasoning, making them valuable in domains where explainability is critical, such as healthcare diagnostics or financial risk assessment. They can model complex relationships without requiring extensive feature engineering and are adaptable to both categorical and numerical data. The algorithm’s hierarchical structure allows it to approximate any Boolean function, making it a universal approximator. However, its performance heavily depends on the quality of the training data and the choice of splitting criteria.
#History / Background
The origins of decision trees trace back to the 1960s, with early work in automated decision-making and game theory. One of the first notable contributions came from J. Ross Quinlan, who developed the ID3 (Iterative Dichotomiser 3) algorithm in 1986. ID3 used information gain (derived from entropy) to select attributes for splitting, laying the foundation for modern decision tree algorithms. Quinlan later improved upon ID3 with C4.5 in 1993, which addressed limitations such as handling continuous attributes and pruning overfitted trees. The CART (Classification and Regression Trees) algorithm, introduced by Leo Breiman, Jerome Friedman, Richard Olshen, and Charles Stone in 1984, extended decision trees to regression tasks and introduced the Gini impurity as a splitting criterion. The 1990s and 2000s saw further advancements, including Random Forests (Breiman, 2001), which combined multiple decision trees to improve robustness and reduce overfitting. Ensemble methods like Gradient Boosted Trees (e.g., XGBoost, LightGBM) later emerged, combining decision trees with boosting techniques to enhance predictive performance. Decision trees have since become a cornerstone of machine learning, influencing fields such as data mining, artificial intelligence, and business analytics. Their evolution reflects broader trends in machine learning, from interpretability-focused models to high-performance ensemble methods.
#How It Works
#Core Principles A decision tree operates by recursively partitioning the dataset into subsets based on attribute values. The process involves:
- Selecting the Best Attribute: At each node, the algorithm evaluates all possible attributes to determine the one that best splits the data. Common criteria include:
- Information Gain (ID3, C4.5): Measures the reduction in entropy (uncertainty) after a split.
- Gini Impurity (CART): Quantifies the likelihood of misclassifying a randomly chosen element if it were labeled according to the distribution of classes in the subset.
- Variance Reduction (Regression Trees): Minimizes the variance of the target variable in the resulting subsets.
- Splitting the Data: The dataset is divided into branches based on the selected attribute’s values. For categorical attributes, branches correspond to distinct categories; for continuous attributes, splits are typically binary (e.g., "feature ≤ threshold").
- Recursive Partitioning: The process repeats for each subset until a stopping condition is met, such as: - All instances in a subset belong to the same class. - A maximum tree depth is reached. - A minimum number of samples per leaf is satisfied. - No further improvement in impurity or gain is possible.
- Prediction: For classification, the leaf node’s majority class is assigned; for regression, the mean or median of the target values in the leaf is used.
#Example Consider a dataset predicting whether a customer will purchase a product based on age and income:
- Root Node: Split on age (e.g., age ≤ 30 vs. age > 30).
- Child Nodes: Further split on income (e.g., income ≤ $50K vs. income > $50K).
- Leaf Nodes: Final predictions (e.g., "Purchase" or "No Purchase").
#Pruning To prevent overfitting, decision trees are often pruned:
- Pre-pruning: Halts tree growth early based on criteria like maximum depth or minimum samples per leaf.
- Post-pruning: Grows the tree fully and then trims branches that contribute little to accuracy (e.g., using reduced-error pruning or cost-complexity pruning).
#Important Facts
- Interpretability: Decision trees provide a visual representation of decision-making processes, making them ideal for explainable AI (XAI) applications.
- Non-Linearity: Unlike linear models, decision trees can capture non-linear relationships and interactions between features.
- Feature Importance: The algorithm ranks features by their contribution to splits, aiding in feature selection.
- Handling Missing Data: Some variants (e.g., C4.5) can manage missing values by distributing instances across branches probabilistically.
- Bias-Variance Tradeoff: Deep trees risk overfitting (high variance), while shallow trees may underfit (high bias).
- Ensemble Methods: Combining multiple trees (e.g., Random Forests, Gradient Boosting) mitigates overfitting and improves generalization.
- Computational Efficiency: Training is relatively fast, but prediction can be slow for very deep trees.
- Data Requirements: Decision trees work well with large datasets but may struggle with high-dimensional data without feature selection.
#Timeline
- Foundational ideas
Core concepts and early methods shape What Is a Decision Tree?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does What Is a Decision Tree? cover?
Explains What Is a Decision Tree, including the core definition, how it works, practical examples, and limitations.
Why is What Is a Decision Tree? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Artificial Intelligence decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Decision, Tree, AI before using the ideas in real projects.
#References
- What Is a Decision Tree? terminology and background research
- What Is a Decision Tree? use cases, implementation examples, and limitations
- Artificial Intelligence best practices, standards, and risk guidance
- Decision case studies, benchmarks, and current industry analysis




Comments
No comments yet. Start the discussion with a useful note.