
#Short Answer
Traces the rise of deep learning: a historical perspective, highlighting major milestones, context, examples, and future implications.
#Infobox
#Overview
Deep learning represents a paradigm shift in artificial intelligence (AI), enabling machines to learn from vast amounts of data by mimicking the structure and function of the human brain. Unlike traditional machine learning models, which rely on handcrafted features, deep learning systems automatically extract hierarchical representations from raw data through layered neural networks. This capability has unlocked unprecedented performance in tasks such as image classification, language translation, and autonomous decision-making. The proliferation of deep learning has been fueled by three critical factors: the exponential growth of digital data, the availability of powerful computing hardware (especially GPUs), and the development of sophisticated algorithms. These elements converged in the 2010s, leading to a surge in real-world applications and commercial adoption across industries. Today, deep learning underpins many of the most transformative technologies, from facial recognition systems to large language models like those used in conversational AI.
#History / Background
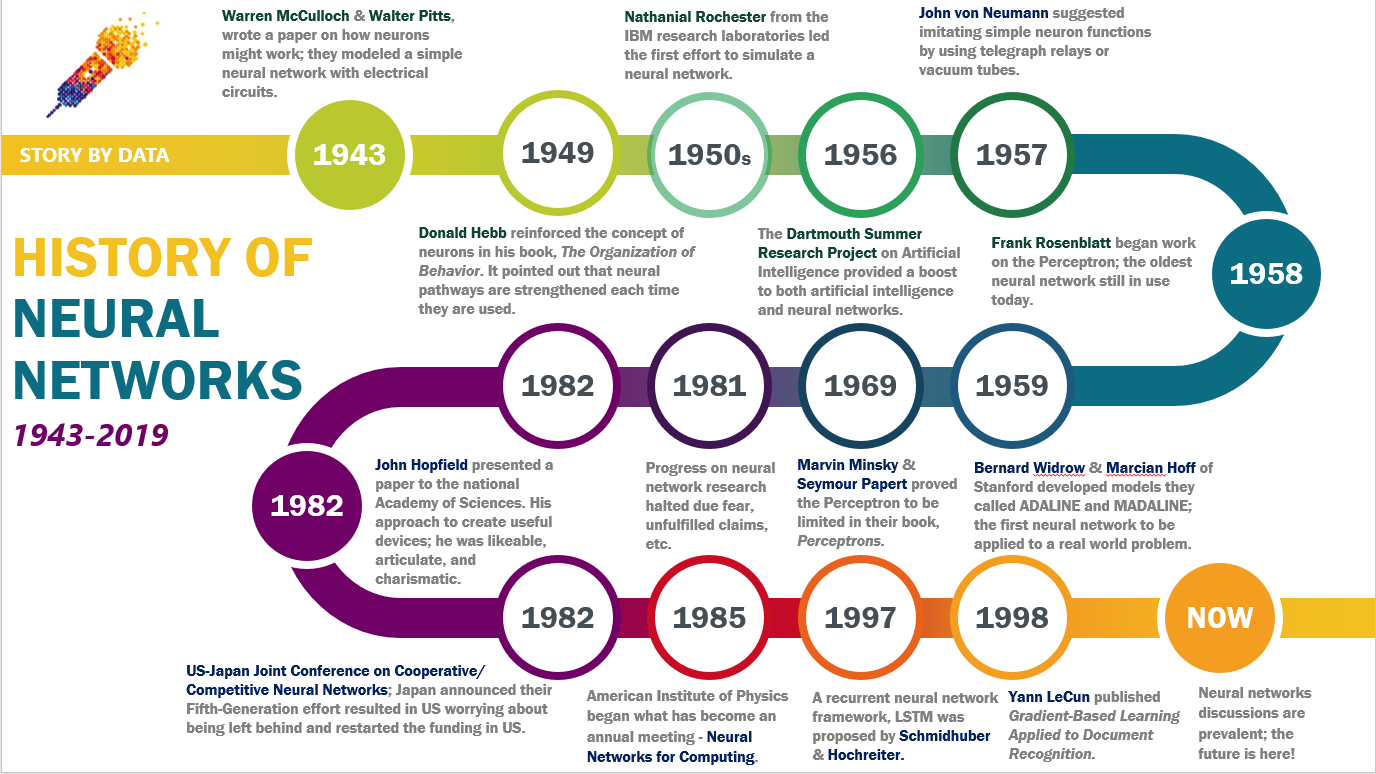
#Early Foundations (1940s–1980s)
The conceptual roots of deep learning trace back to the 1940s with the work of Warren McCulloch and Walter Pitts, who proposed a mathematical model of artificial neurons. This idea was later formalized in the 1958 Perceptron model by Frank Rosenblatt, which demonstrated the potential of neural networks to learn from data. However, early perceptrons were limited to linear decision boundaries, and their inability to solve non-linear problems led to the first "AI winter" in the 1970s. In the 1980s, the backpropagation algorithm—developed independently by several researchers including David Rumelhart, Geoffrey Hinton, and Ronald Williams—revived interest in neural networks. Backpropagation enabled networks to learn from errors by adjusting weights across multiple layers, laying the groundwork for deep architectures. During this period, the term "deep learning" began to emerge, though it was not yet widely used.
#The First Wave of Deep Learning (1990s–2000s)
Despite theoretical progress, practical applications were constrained by limited computational power and the vanishing gradient problem—where gradients in deep networks become too small to effectively update early layers. Researchers like Yann LeCun made significant contributions by introducing convolutional neural networks (CNNs), which were applied successfully to handwritten digit recognition (e.g., the LeNet-5 system). However, deep learning remained a niche field, overshadowed by other AI approaches such as support vector machines (SVMs). The lack of large labeled datasets and affordable high-performance computing further hindered progress.
#The Deep Learning Revolution (2010s–Present)
The turning point came in 2012 when a deep convolutional neural network called AlexNet, developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, won the ImageNet Large Scale Visual Recognition Challenge by a wide margin. This victory demonstrated that deep learning could surpass traditional methods in complex visual tasks, sparking global interest. Following AlexNet, rapid advancements followed:
- 2014: Emergence of Generative Adversarial Networks (GANs) by Ian Goodfellow, enabling realistic image and data generation.
- 2015: ResNet (Residual Networks), introduced by Kaiming He et al., addressed the vanishing gradient problem using skip connections, allowing training of extremely deep networks (over 100 layers).
- 2017: The Transformer architecture, developed by Vaswani et al., revolutionized natural language processing by replacing recurrent networks with self-attention mechanisms, leading to models like BERT and later GPT. The rise of cloud computing and open-source frameworks such as TensorFlow and PyTorch democratized access to deep learning tools, accelerating innovation. Today, deep learning powers applications ranging from medical imaging and drug discovery to autonomous vehicles and personalized recommendation systems.
#How It Works
#Artificial Neural Networks (ANNs)
At the core of deep learning are artificial neural networks, which consist of interconnected nodes (neurons) organized into layers:
- Input Layer: Receives raw data (e.g., pixels in an image).
- Hidden Layers: Perform transformations through weighted connections and activation functions (e.g., ReLU, sigmoid).
- Output Layer: Produces the final prediction or classification.
#Key Architectures
- Convolutional Neural Networks (CNNs): Specialized for grid-like data (e.g., images). Convolutional layers apply filters to detect local patterns, while pooling layers reduce spatial dimensions. CNNs are the backbone of modern computer vision systems.
- Recurrent Neural Networks (RNNs): Designed for sequential data (e.g., time series, text). Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) variants help mitigate the vanishing gradient problem in long sequences.
- Transformers: Introduced in the "Attention Is All You Need" paper (2017), transformers use self-attention mechanisms to weigh the importance of different parts of the input simultaneously. This architecture is the foundation of large language models (LLMs) like those used in chatbots and translation services.
#Training Process
Deep learning models are trained using supervised learning, where labeled data is fed into the network. The model makes predictions, compares them to the true labels using a loss function, and adjusts its weights via backpropagation and optimization algorithms like Stochastic Gradient Descent (SGD) or Adam. Regularization techniques such as dropout, batch normalization, and data augmentation are used to prevent overfitting and improve generalization.
#Key Concepts
- Feature Hierarchy: Deep networks learn representations at multiple levels of abstraction (e.g., edges → textures → object parts → whole objects in images).
- Transfer Learning: Pre-trained models (e.g., ResNet, BERT) are fine-tuned on new tasks, reducing the need for large labeled datasets.
- Explainability: Techniques like Grad-CAM and SHAP help interpret model decisions, crucial for applications in healthcare and finance.
#Important Facts
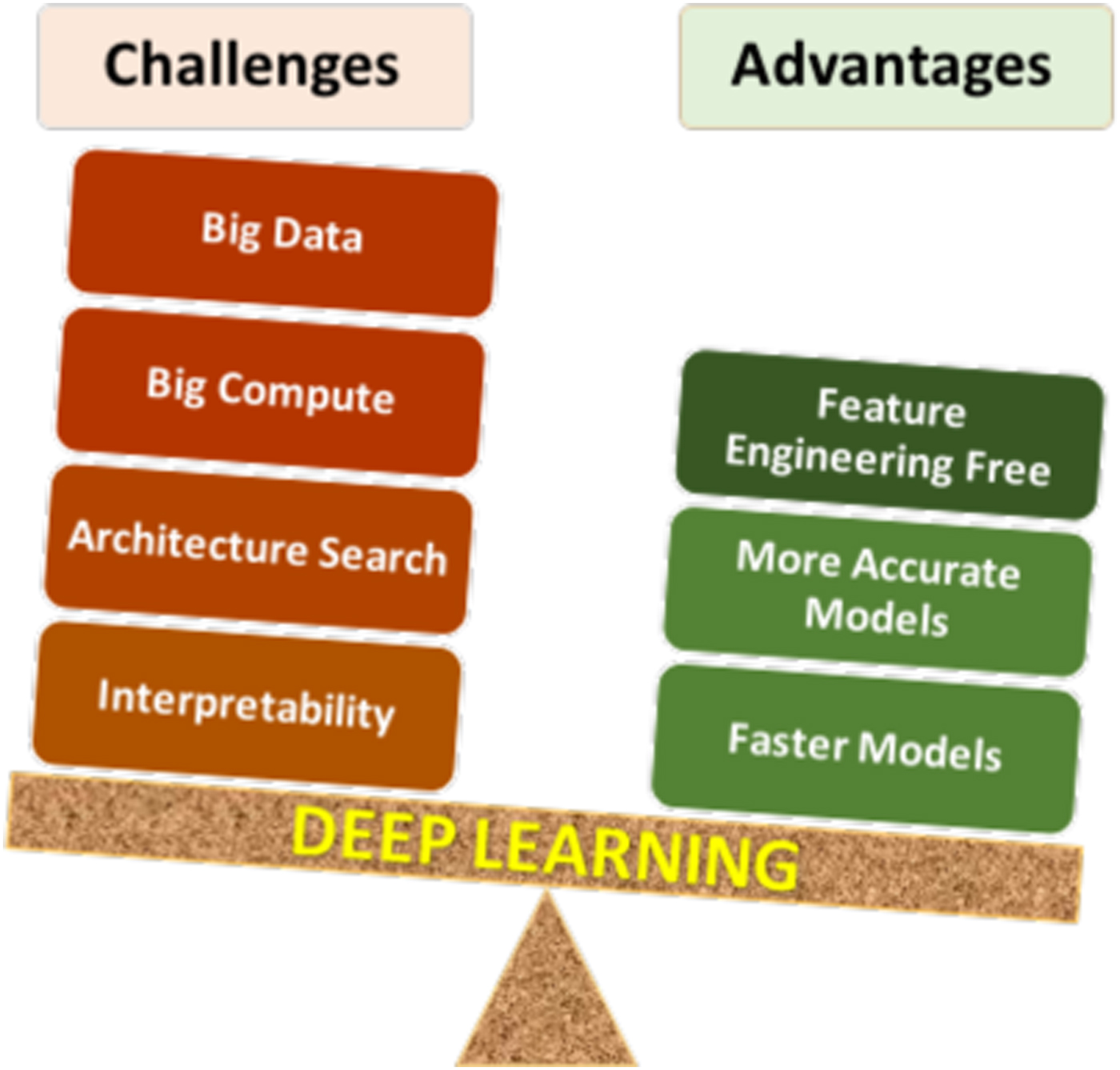
- Data Dependency: Deep learning models require massive datasets to perform well. For example, ImageNet contains over 14 million labeled images.
- Computational Cost: Training large models can consume thousands of GPU hours. The training of GPT-3 reportedly cost millions of dollars in compute time.
- Energy Consumption: The carbon footprint of training large models has raised environmental concerns, prompting research into more efficient architectures and training methods.
- Bias and Fairness: Deep learning models can inherit biases present in training data, leading to discriminatory outcomes in applications like facial recognition and hiring algorithms.
- Black Box Nature: Many deep learning models operate as "black boxes," making it difficult to understand how decisions are made—a major challenge in high-stakes domains.
- Hardware Advancements: The development of specialized hardware like Tensor Processing Units (TPUs) by Google and GPUs by NVIDIA has been instrumental in scaling deep learning.
- Open Research: Many foundational models and datasets are released under open licenses (e.g., Hugging Face Transformers, ImageNet), fostering collaboration and innovation.
#Timeline
- Foundational ideas
Core concepts and early methods shape The Rise of Deep Learning: a Historical Perspective.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does The Rise of Deep Learning: a Historical Perspective cover?
Traces the rise of deep learning: a historical perspective, highlighting major milestones, context, examples, and future implications.
Why is The Rise of Deep Learning: a Historical Perspective important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Rise, Deep, Learning before using the ideas in real projects.
#References
- The Rise of Deep Learning: a Historical Perspective terminology and background research
- The Rise of Deep Learning: a Historical Perspective use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Rise case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.