
#Short Answer
Compares Supervised vs Unsupervised Learning: Key Differences, covering key differences, advantages, limitations, and selection criteria.
#Infobox
#Overview
Supervised and unsupervised learning represent the foundational categories of machine learning, each serving distinct purposes in data analysis and predictive modeling. Supervised learning leverages labeled datasets to train algorithms that generalize patterns for making predictions on new, unseen data. In contrast, unsupervised learning operates on unlabeled data, uncovering intrinsic structures such as clusters, associations, or latent features without prior guidance. The choice between these paradigms depends on the problem domain, data availability, and the nature of the insights sought. Supervised learning excels in tasks requiring precise predictions or classifications, while unsupervised learning is invaluable for exploratory data analysis, dimensionality reduction, and discovering hidden relationships in complex datasets.
#History / Background
#Early Foundations The conceptual roots of supervised and unsupervised learning trace back to the mid-20th century, coinciding with the emergence of artificial intelligence and statistical learning theory. In 1950, Alan Turing proposed the idea of machines learning from experience, laying the groundwork for modern machine learning. However, the formal distinction between supervised and unsupervised learning began to crystallize in the 1960s and 1970s with advancements in statistical pattern recognition and clustering algorithms.
#Supervised Learning: The Rise of Predictive Modeling Supervised learning gained prominence with the development of algorithms like the perceptron (1958) by Frank Rosenblatt, which introduced the concept of learning from labeled examples. The 1960s and 1970s saw the rise of linear regression, logistic regression, and decision trees, which became staples in predictive modeling. The introduction of support vector machines (SVMs) in the 1990s by Vladimir Vapnik further advanced supervised learning by providing robust methods for classification and regression tasks.
#Unsupervised Learning: Discovering Hidden Structures Unsupervised learning evolved alongside the need to analyze large, unlabeled datasets. Early work on clustering by statisticians such as John Tukey and Herbert Robbins in the 1950s and 1960s laid the foundation for algorithms like k-means clustering (1967) and hierarchical clustering. The 1980s and 1990s witnessed the development of principal component analysis (PCA) and independent component analysis (ICA), which enabled dimensionality reduction and feature extraction from high-dimensional data. The advent of neural networks and autoencoders in the 2000s expanded unsupervised learning’s capabilities, particularly in representation learning and generative modeling.
#Modern Developments The 21st century has seen a convergence of supervised and unsupervised techniques, with semi-supervised learning and self-supervised learning bridging the gap between labeled and unlabeled data. Advances in deep learning have further blurred the lines, enabling models like transformers and generative adversarial networks (GANs) to leverage both paradigms for tasks such as natural language processing and image generation.
#How It Works
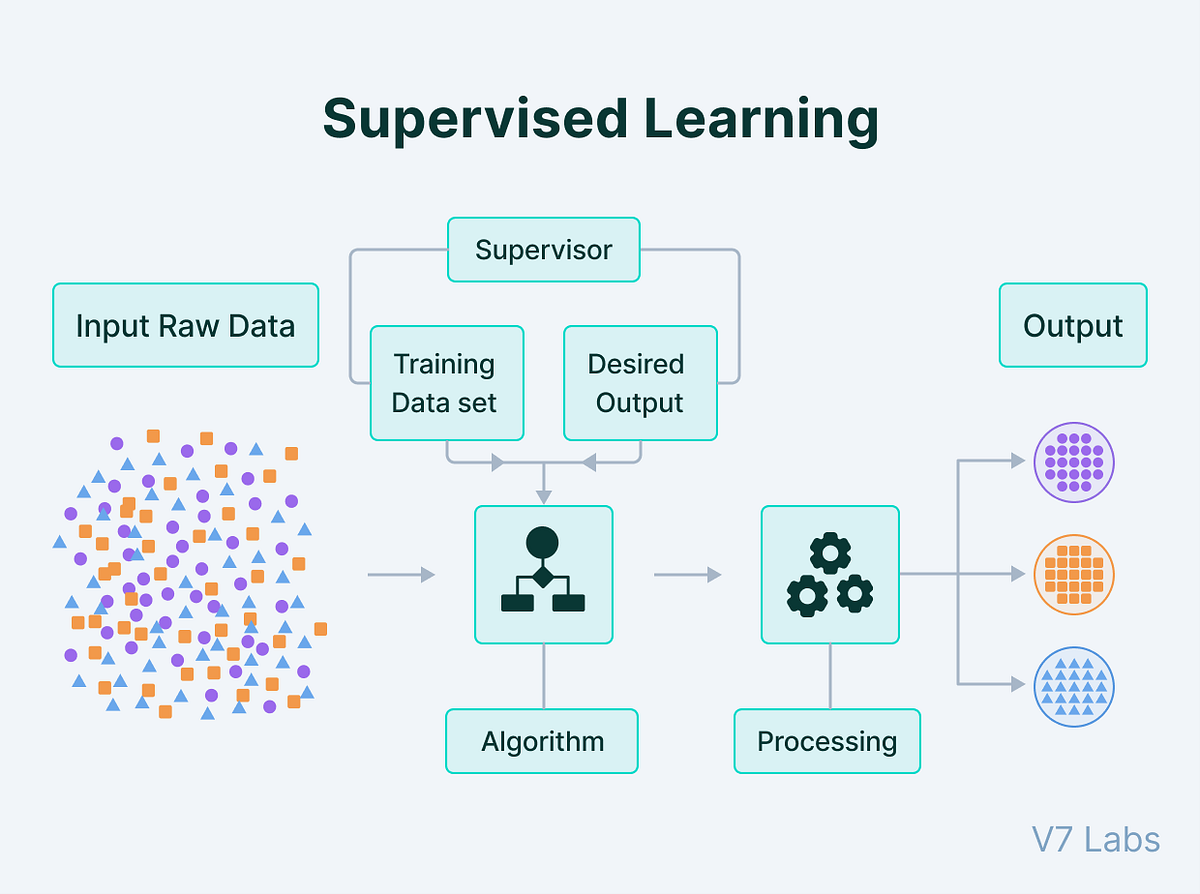
#Supervised Learning Supervised learning algorithms learn a mapping function from input variables (features) to output variables (labels) using a labeled training dataset. The process involves the following steps:
- Data Collection: Gather a dataset with input-output pairs, where the output is the desired prediction or classification.
- Preprocessing: Clean and normalize the data, handle missing values, and encode categorical variables.
- Model Selection: Choose an appropriate algorithm based on the problem type (classification or regression).
- Training: Feed the labeled data into the algorithm, which adjusts its parameters to minimize the difference between predicted and actual outputs (e.g., using loss functions like mean squared error or cross-entropy).
- Evaluation: Assess the model’s performance on a held-out test dataset using metrics such as accuracy, precision, recall, or mean absolute error.
- Deployment: Deploy the trained model to make predictions on new, unseen data. Common Algorithms:
- Classification: Logistic regression, decision trees, random forests, support vector machines (SVM), k-nearest neighbors (KNN).
- Regression: Linear regression, polynomial regression, ridge regression, lasso regression.
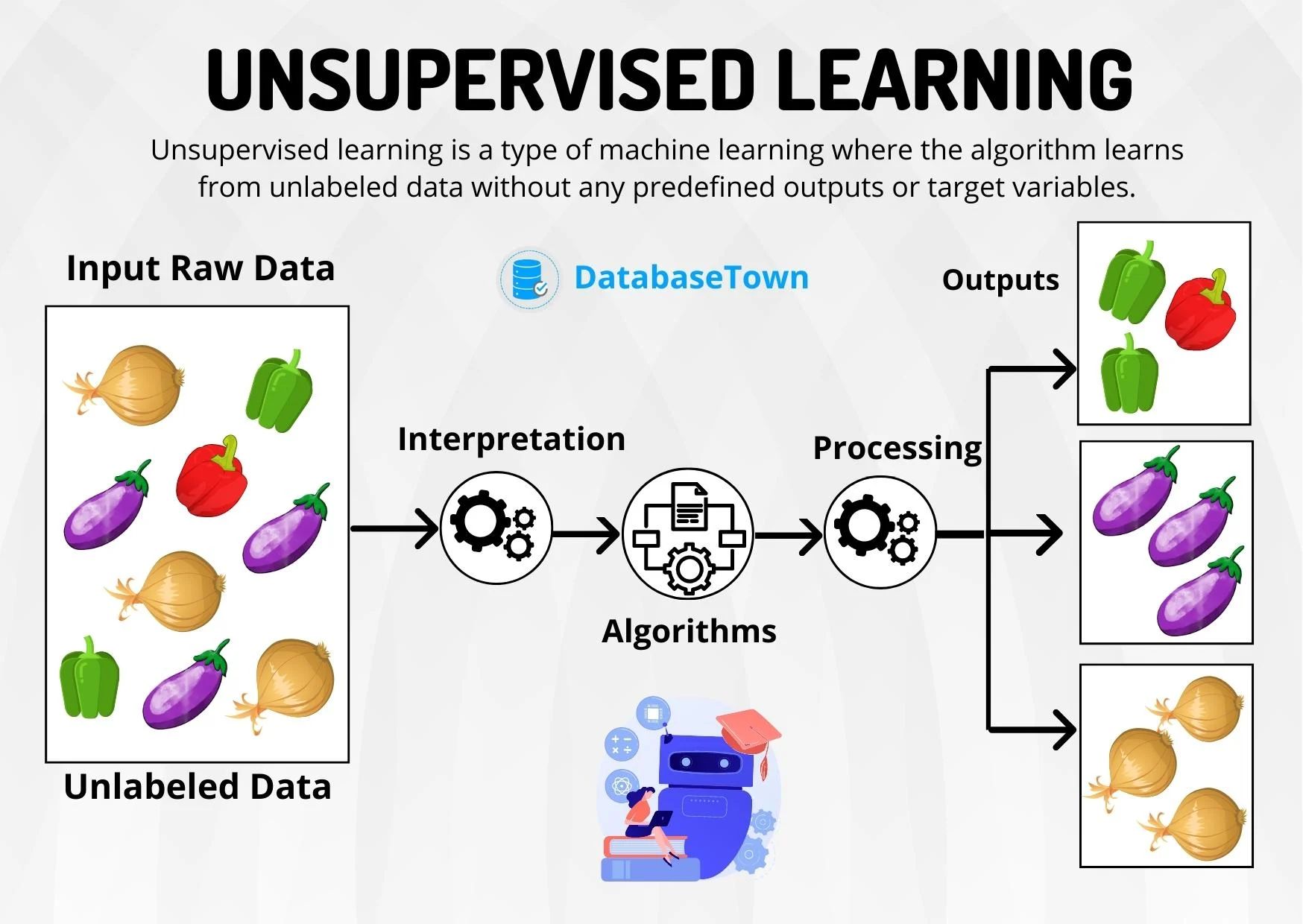
#Unsupervised Learning Unsupervised learning algorithms identify patterns or structures in unlabeled data without predefined outputs. The process typically includes:
- Data Collection: Gather a dataset without labels, focusing on raw features.
- Preprocessing: Normalize or standardize the data, handle outliers, and reduce dimensionality if necessary.
- Model Selection: Choose an algorithm suited to the task (e.g., clustering, association, or dimensionality reduction).
- Training: Apply the algorithm to uncover hidden patterns, such as grouping similar data points or identifying latent features.
- Interpretation: Analyze the results to derive meaningful insights, such as customer segments or anomaly detection.
- Visualization: Use techniques like t-SNE or PCA to visualize high-dimensional data in lower dimensions. Common Algorithms:
- Clustering: K-means, hierarchical clustering, DBSCAN, Gaussian mixture models.
- Dimensionality Reduction: Principal component analysis (PCA), t-distributed stochastic neighbor embedding (t-SNE), autoencoders.
- Association: Apriori algorithm, FP-growth algorithm.
#Important Facts
- Data Dependency: - Supervised learning requires high-quality labeled data, which can be expensive and time-consuming to obtain. - Unsupervised learning is more flexible but may produce less interpretable results without additional validation.
- Bias-Variance Tradeoff: - Supervised models risk overfitting if trained on noisy or overly complex data. - Unsupervised models may struggle with high-dimensional data, necessitating techniques like PCA for dimensionality reduction.
- Applications: - Supervised learning powers real-world systems such as recommendation engines (e.g., Netflix, Amazon), medical diagnosis (e.g., tumor detection), and financial forecasting (e.g., stock price prediction). - Unsupervised learning is used in customer segmentation (e.g., marketing), anomaly detection (e.g., fraud detection), and genomic data analysis (e.g., gene expression clustering).
- Hybrid Approaches:
- Semi-supervised learning combines labeled and unlabeled data to improve model performance.
- Self-supervised learning generates labels from the data itself, enabling unsupervised tasks to leverage supervised techniques.
- Challenges: - Supervised learning faces challenges like label scarcity, class imbalance, and data drift. - Unsupervised learning grapples with evaluating clustering quality, scalability, and interpretability.
#Timeline
- Foundational ideas
Core concepts and early methods shape Supervised vs Unsupervised Learning: Key Differences.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Supervised vs Unsupervised Learning: Key Differences cover?
Compares Supervised vs Unsupervised Learning: Key Differences, covering key differences, advantages, limitations, and selection criteria.
Why is Supervised vs Unsupervised Learning: Key Differences important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Supervised, Unsupervised, Learning before using the ideas in real projects.
#References
- Supervised vs Unsupervised Learning: Key Differences terminology and background research
- Supervised vs Unsupervised Learning: Key Differences use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Supervised case studies, benchmarks, and current industry analysis

Comments
No comments yet. Start the discussion with a useful note.