#Short Answer
Compares Machine Learning vs Deep Learning: What’s the Difference, covering key differences, advantages, limitations, and selection criteria.
#Infobox
#Overview
Machine learning and deep learning represent two pivotal paradigms in the evolution of artificial intelligence, each addressing different challenges in data analysis and automation. While both aim to enable computers to learn from data, their methodologies, applications, and underlying architectures differ significantly. Machine learning, a broader field, encompasses algorithms that improve their performance as they are exposed to more data. These algorithms can be categorized into supervised learning (using labeled data), unsupervised learning (finding patterns in unlabeled data), and reinforcement learning (learning through rewards and penalties). Traditional ML models include linear regression, decision trees, support vector machines, and k-means clustering. Deep learning, a specialized branch of ML, leverages artificial neural networks with many layers—hence the term "deep"—to model high-level abstractions in data. These neural networks are inspired by the structure and function of the human brain, consisting of interconnected nodes (neurons) organized into layers. The depth of these networks allows them to learn complex representations, making them particularly effective for tasks involving unstructured data such as images, speech, and text. The distinction between ML and DL is not merely academic; it has practical implications for industries ranging from healthcare to finance. ML is often sufficient for tasks with clear patterns and structured data, while DL is preferred for tasks requiring the analysis of vast, unstructured datasets where manual feature extraction would be impractical.
#History / Background
#Origins of Machine Learning The foundations of machine learning trace back to the mid-20th century. In 1950, Alan Turing proposed the concept of a machine that could learn, laying the groundwork for AI research. The term "machine learning" was coined by Arthur Samuel in 1959, who defined it as the ability of computers to learn without being explicitly programmed. Early ML models, such as Arthur Samuel's checkers-playing program, demonstrated the potential of computers to improve their performance through experience. During the 1960s and 1970s, research focused on symbolic AI and rule-based systems, which were limited by their inability to handle complex, real-world data. The 1980s and 1990s saw a shift toward statistical learning methods, with the development of algorithms like decision trees, support vector machines, and Bayesian networks. The advent of the internet and the explosion of digital data in the late 20th century provided the fuel for ML to flourish, enabling the training of models on vast datasets.
#Rise of Deep Learning Deep learning emerged as a dominant force in AI in the 21st century, driven by advances in computational power, the availability of large datasets, and breakthroughs in neural network architectures. The concept of artificial neural networks dates back to the 1940s, with the first computational model of a neuron proposed by Warren McCulloch and Walter Pitts in 1943. However, early neural networks were limited by computational constraints and the lack of effective training methods. The breakthrough came in 2006 when Geoffrey Hinton, Ruslan Salakhutdinov, and others demonstrated that deep neural networks could be trained effectively using a technique called "greedy layer-wise training." This approach involved pre-training each layer of the network as an unsupervised model before fine-tuning the entire network with labeled data. The success of this method led to a resurgence of interest in neural networks and the coining of the term "deep learning." The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012 marked a turning point for DL, with a convolutional neural network (CNN) called AlexNet achieving unprecedented accuracy in image classification. Since then, deep learning has become the go-to method for tasks such as speech recognition, natural language processing, and autonomous driving. The development of frameworks like TensorFlow, PyTorch, and Keras has further democratized DL, enabling researchers and practitioners to build and deploy complex models with relative ease.
#How It Works
#Machine Learning Workflow The typical workflow for a machine learning project involves several key steps:
- Data Collection: Gathering relevant data from various sources, such as databases, APIs, or web scraping.
- Data Preprocessing: Cleaning and transforming raw data into a format suitable for training. This includes handling missing values, normalizing numerical data, and encoding categorical variables.
- Feature Engineering: Selecting and transforming relevant features from the dataset to improve model performance. This step often requires domain expertise and creativity.
- Model Selection: Choosing an appropriate algorithm based on the problem type (e.g., classification, regression, clustering) and the nature of the data.
- Training: Feeding the preprocessed data into the model to learn patterns and relationships. The model adjusts its parameters to minimize error.
- Evaluation: Assessing the model's performance using metrics such as accuracy, precision, recall, or mean squared error. Techniques like cross-validation are used to ensure the model generalizes well to unseen data.
- Deployment: Integrating the trained model into a production environment where it can make predictions on new data.
- Monitoring and Maintenance: Continuously evaluating the model's performance in real-world scenarios and updating it as necessary to adapt to changing data patterns.
#Deep Learning Workflow Deep learning follows a similar workflow but with key differences due to its reliance on neural networks:
- Data Collection: Similar to ML, but often involves larger and more complex datasets, such as images, videos, or text corpora.
- Data Preprocessing: Includes tasks like resizing images, normalizing pixel values, tokenizing text, and augmenting data to increase diversity.
- Model Architecture Design: Defining the structure of the neural network, including the number of layers, types of layers (e.g., convolutional, recurrent, fully connected), and activation functions.
- Training: Utilizing backpropagation and optimization algorithms like stochastic gradient descent (SGD) or Adam to adjust the weights of the network. DL models typically require more computational resources and time due to their complexity.
- Hyperparameter Tuning: Adjusting parameters such as learning rate, batch size, and number of epochs to optimize model performance.
- Evaluation: Using metrics like accuracy, F1-score, or area under the ROC curve (AUC-ROC) to assess performance. DL models often require more sophisticated evaluation techniques due to their complexity.
- Deployment: Deploying the model in environments that can handle its computational demands, such as cloud platforms or edge devices with specialized hardware.
- Fine-Tuning and Transfer Learning: Leveraging pre-trained models (e.g., ResNet, BERT) and fine-tuning them for specific tasks to reduce training time and improve performance.
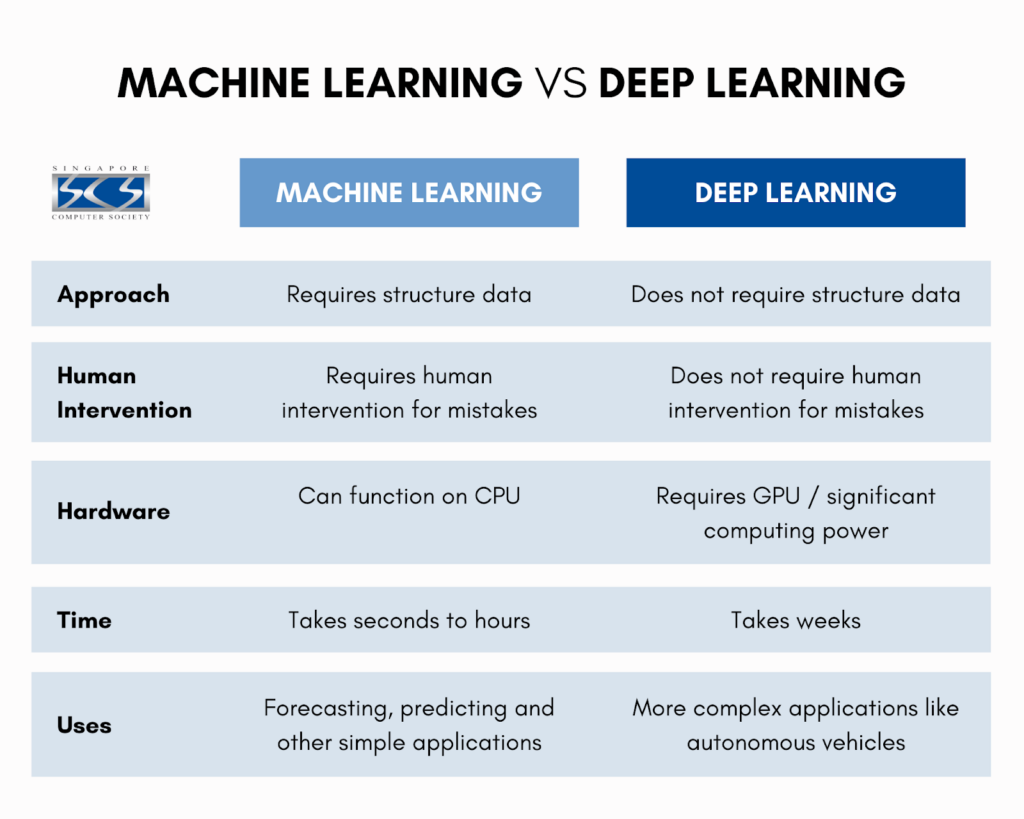
#Key Differences in Implementation
- Feature Extraction: ML requires manual feature engineering, while DL automatically extracts features through its layers.
- Data Requirements: ML can work with smaller datasets, whereas DL typically requires large datasets to avoid overfitting.
- Hardware: ML models can run on standard CPUs, while DL models often require GPUs or TPUs to handle the computational load.
- Interpretability: ML models are generally more interpretable, while DL models are often considered "black boxes" due to their complexity.
#Important Facts
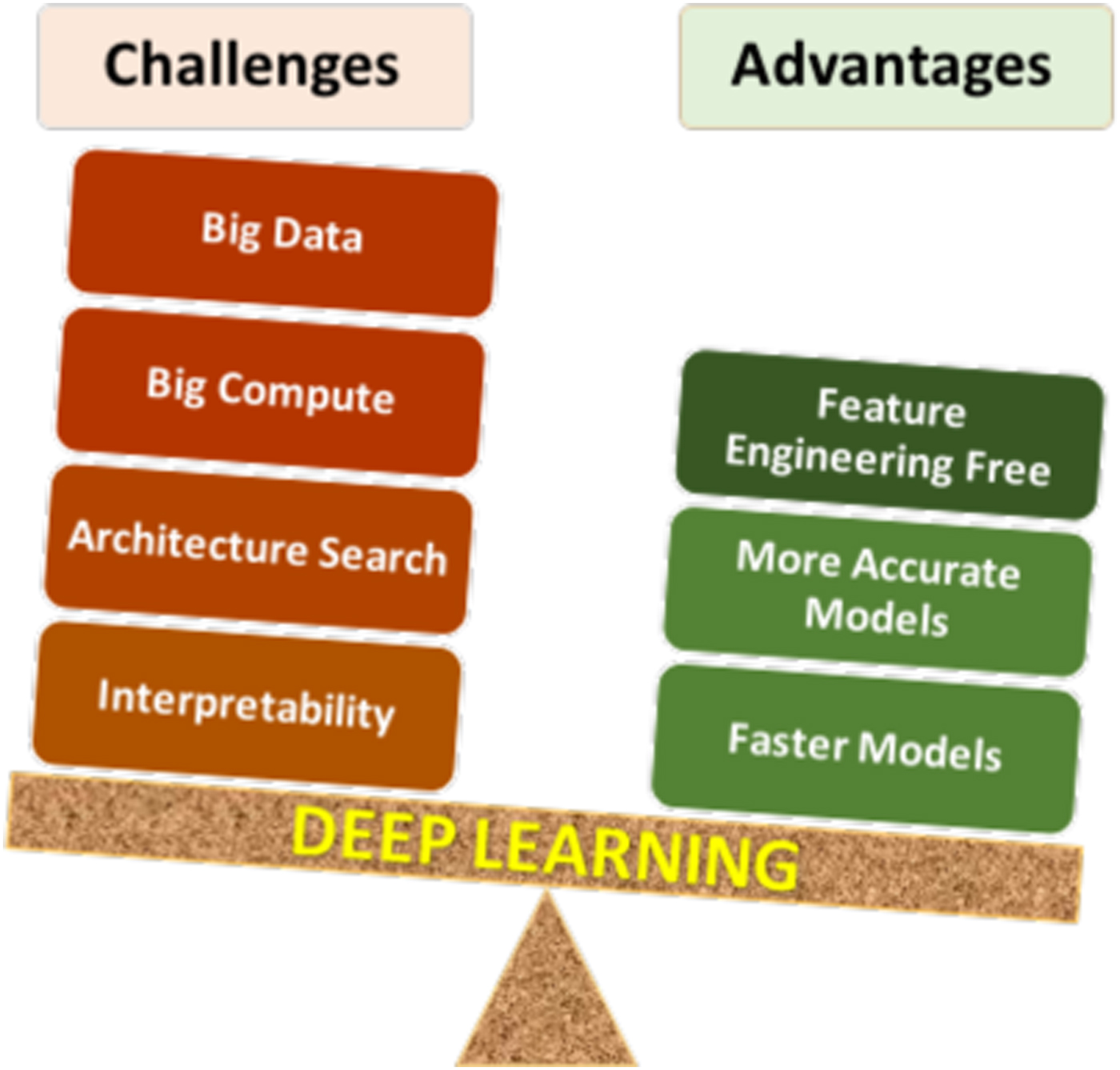
- Scalability: Deep learning models scale better with data. As the amount of data increases, DL models tend to improve in performance, whereas ML models may plateau.
- Automation: DL reduces the need for manual intervention in feature extraction, making it more suitable for tasks involving unstructured data.
- Hardware Dependency: The training of DL models is heavily dependent on specialized hardware like GPUs and TPUs, which can be expensive and power-intensive.
- Overfitting: DL models are more prone to overfitting due to their large number of parameters. Techniques like dropout, regularization, and data augmentation are used to mitigate this.
- Transfer Learning: DL models can leverage pre-trained models, allowing them to be fine-tuned for new tasks with relatively little data.
- Explainability: ML models are generally more explainable, making them preferable in domains where interpretability is critical, such as healthcare and finance.
- Real-World Applications:
- Machine Learning: Spam filtering, credit scoring, customer segmentation, and predictive maintenance.
- Deep Learning: Facial recognition, machine translation, autonomous vehicles, and medical image analysis.
- Ethical Considerations: Both ML and DL raise ethical concerns, such as bias in training data, privacy issues, and the potential for misuse in surveillance or deepfake technology.
#Timeline
- Foundational ideas
Core concepts and early methods shape Machine Learning vs Deep Learning: What’s the Difference?.
- Practical use
Tools, examples, and real-world deployments make the topic easier to evaluate.
- Responsible implementation
Current work focuses on reliability, governance, performance, and measurable impact.
#Related Terms
#FAQ
What does Machine Learning vs Deep Learning: What’s the Difference? cover?
Compares Machine Learning vs Deep Learning: What’s the Difference, covering key differences, advantages, limitations, and selection criteria.
Why is Machine Learning vs Deep Learning: What’s the Difference? important?
It helps readers understand key concepts, compare practical use cases, and evaluate how Machine Learning decisions affect outcomes, risks, and implementation choices.
What should readers verify before applying this topic?
Readers should compare benefits, limitations, data requirements, and related themes such as Machine, Learning, Deep before using the ideas in real projects.
#References
- Machine Learning vs Deep Learning: What’s the Difference? terminology and background research
- Machine Learning vs Deep Learning: What’s the Difference? use cases, implementation examples, and limitations
- Machine Learning best practices, standards, and risk guidance
- Machine case studies, benchmarks, and current industry analysis


Comments
No comments yet. Start the discussion with a useful note.